



 本文深入浅出地介绍了线性回归这一经典预测模型的基本原理及应用。通过实例展示如何利用线性回归进行数据预测,并探讨了误差函数的概念及其最小化过程。此外,还强调了相关性与因果性之间的区别。
本文深入浅出地介绍了线性回归这一经典预测模型的基本原理及应用。通过实例展示如何利用线性回归进行数据预测,并探讨了误差函数的概念及其最小化过程。此外,还强调了相关性与因果性之间的区别。
Regression is All you Need
Author: Bobby(Zhuoran) Peng
People have created and utilized a bewildering variety of algorithms trying to predict future data in various industries. However, the most prevalent and perhaps east-to-intrpret and proven algorithm remains to be linear regression. The following figure showing linear regression to be the most welcomed algorithm also implies that it is one of the most basic rules for supervised machine learning and beyond.
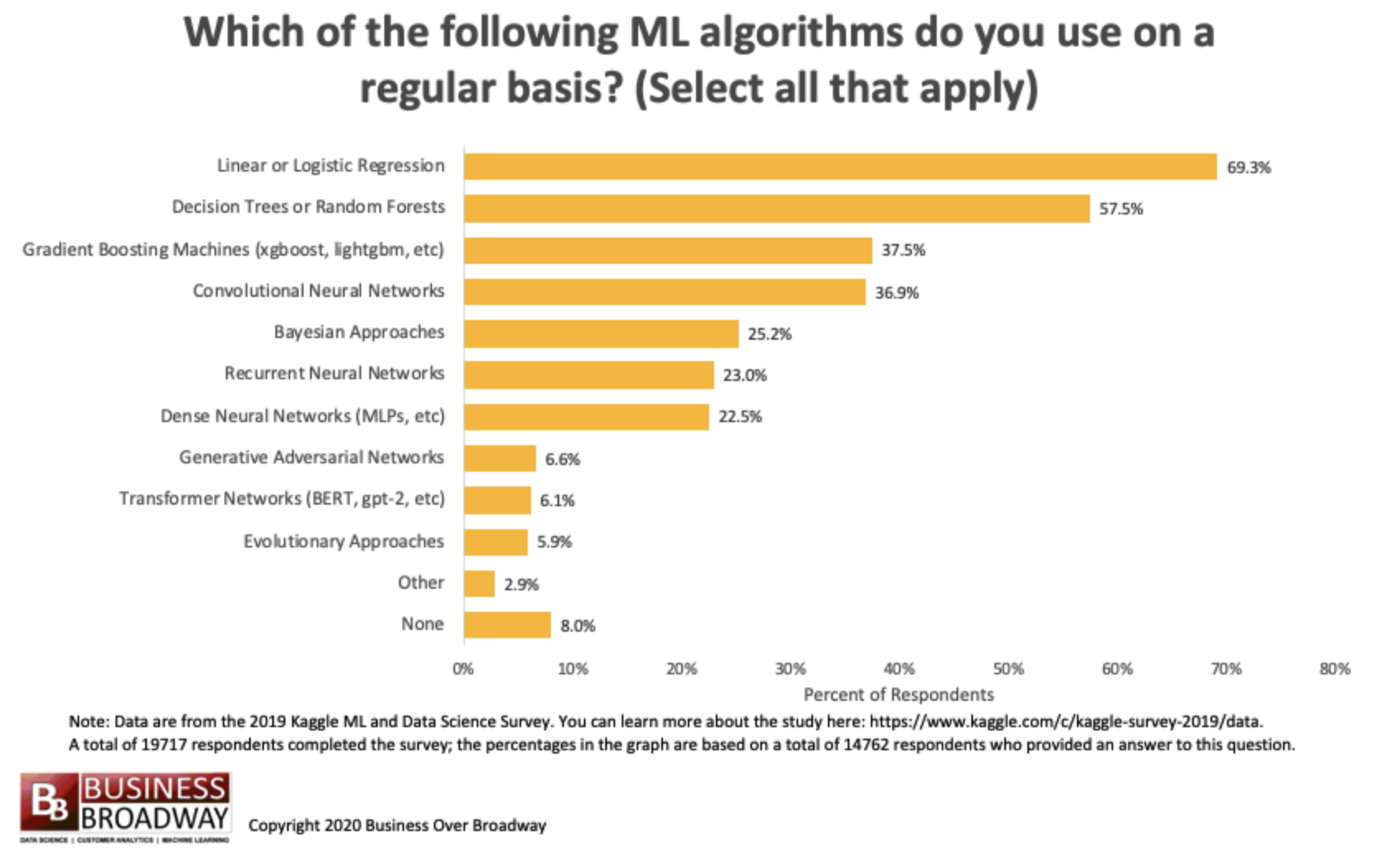
What is Linear Regression
There are two variables in a linear regression, one is dependent variable and the other is independent variable. The dependent variable is what we want to predict, and its value depends on the changes of independent variable.
y=α0+α1x
y = \alpha_0 + \alpha_1x
y=α0+α1x
In the above model, we are using x to predict the value of y.
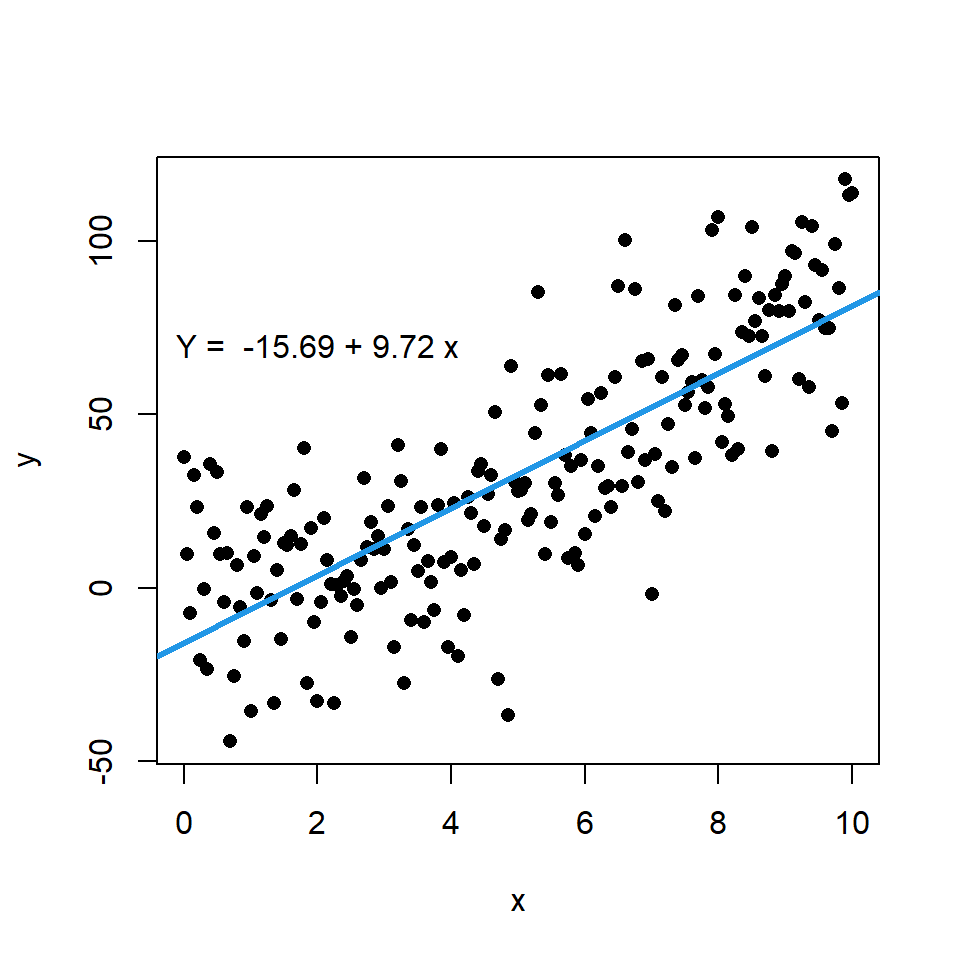
The above scatter plot is an example of a linear regression model. Here we get a fitting line of y=−15.69+9.72xy=-15.69+9.72xy=−15.69+9.72x, if we then have a xxx value, we can use the equation to predict a yyy value.
Also, we can use matrix to present the linear relationship. Let XXX be a d×nd\times nd×n matrix (nnn items and ddd features), and www be d×1d\times 1d×1 matrix (containing cooeficients), and Yˉ\bar{Y}Yˉ be the output matrix of size n×1n\times 1n×1, then we have: XTw=YˉX^Tw=\bar{Y}XTw=Yˉ
Data in the real world are just like this scatter plot, our linear regression model is just a prediction, and we use yˉ\bar{y}yˉ to present the predicted values of the model on our blue fitting line, while real data are those black spots scattering in the figure. The difference between the predicted yˉ\bar{y}yˉ and the real yyy value is called the error, and we often use eee to represent it, and we have the following equation: y=α0+α1x+ey = \alpha_0 + \alpha_1x + ey=α0+α1x+e or Y=XTw+eY=X^Tw + eY=XTw+e
The Error Function
As mentioned above, error is the distance between yyy and yˉ\bar{y}yˉ, then we can derive a way to estimate the total error of the whole set: E=∑i=1n(yi−yiˉ)2=∑i=1n(yi−α0−α1xi)2E = \sum_{i=1}^n (y_i-\bar{y_i})^2=\sum_{i=1}^n (y_i-\alpha_0 - \alpha_1x_i)^2E=i=1∑n(yi−yiˉ)2=i=1∑n(yi−α0−α1xi)2 or E=∣∣Y−XTw∣∣2E = ||Y-X^Tw||^2E=∣∣Y−XTw∣∣2And this is obviously a quadratic function. Thus to minimize the error, we need to manipulate α0\alpha_0α0 and α1\alpha_1α1, or www matrice, taking derivative until it reaches 0. Thus we have: ∂E∂α0=2∑i=1n(yi−α0−α1xi)=0\frac{\partial E}{\partial \alpha_0}=2\sum_{i=1}^n (y_i-\alpha_0 - \alpha_1x_i)=0∂α0∂E=2i=1∑n(yi−α0−α1xi)=0 ∂E∂α1=2∑i=1n(yi−α0−α1xi)xi=0\frac{\partial E}{\partial \alpha_1}=2\sum_{i=1}^n (y_i-\alpha_0 - \alpha_1x_i)x_i=0∂α1∂E=2i=1∑n(yi−α0−α1xi)xi=0
or for the matrix expression:E=∣∣Y−XTw∣∣2=(Y−XTw)T(Y−XTw)=wTXXTw−wTXY−YTXTw+YTYE = ||Y-X^Tw||^2=(Y-X^Tw)^T(Y-X^Tw)\\ =w^TXX^Tw-w^TXY-Y^TX^Tw+Y^TYE=∣∣Y−XTw∣∣2=(Y−XTw)T(Y−XTw)=wTXXTw−wTXY−YTXTw+YTY
Then ∂E∂w=2XXTw−2XY=0w=(XXT)−1Y\frac{\partial E}{\partial w}=2XX^Tw-2XY=0 \\w=(XX^T)^{-1}Y∂w∂E=2XXTw−2XY=0w=(XXT)−1Y
Correlation is not Causality
We now know how to analyze a linear regression to predict y by x. In real life practices, two variables may have a strong correlation in the linear model, but this does not necessaryly mean x is the cause of y. For example, in a searching engine, items of higher ranking would recieve higher click rates, like the following figure showing.
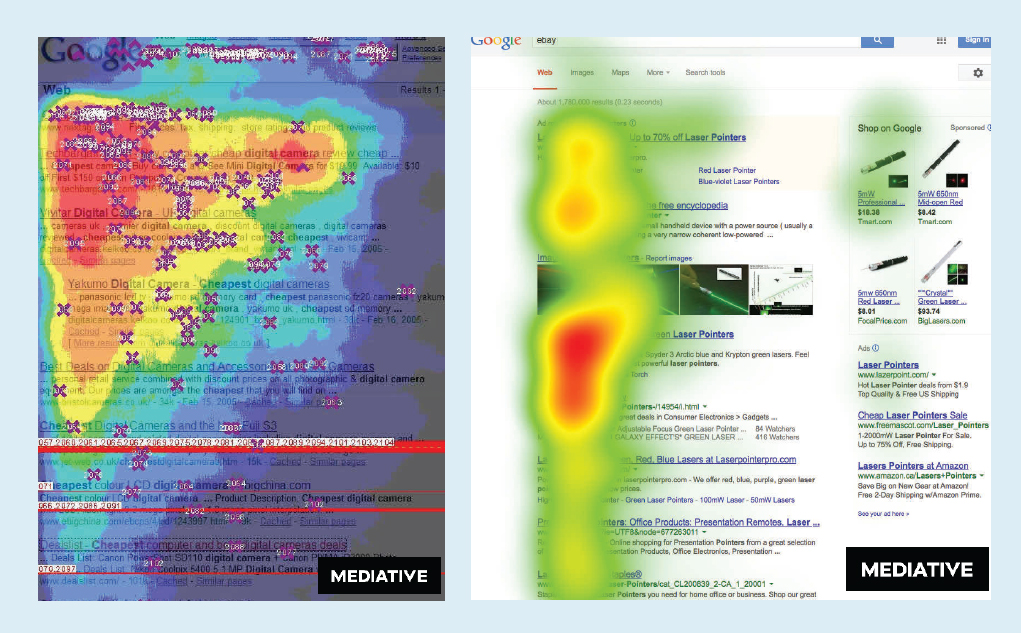
You may find a linear relation between ranking and click rates, but this does not lead to the conclusion that users like items of higher ranking more than items of lower ranking. This is the typical position bias in recommender system, and the causality inspired machine learning problems are getting increasing focus these days, trying to find real causes behind linear or nonlinear correlations.

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









