







文章目录
- disk access time & effective disk buffer access time
- 数据库系统的类型
- 存储系统(lecture3N4)
- 索引系统(indexing) lecture5
- 事务(Transaction)(lecture6N7)
- 并发控制(Concurrency Control) lecture8N9
- 如何避免依赖现象(使用锁)Lecture10
- 独立性理论(Isolation Theorems)
disk access time & effective disk buffer access time
disk access time
- 机械硬盘
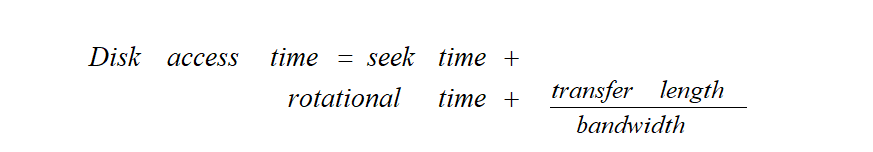
- 固态硬盘
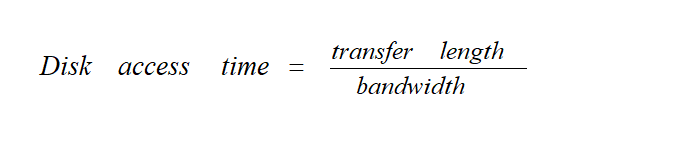
effective buffer access time

- 机械硬盘

因为 buffer (cache)是一种 on chip 的结构,因此系统对 buffer 中数据的访问速度,要比 disk 上的速度快很多,因此 hit 是数据被加载到 buffer 上的概率。因此系统总的访问时间,应该被分成两个部分然后求和
数据库系统的类型
- 单纯文件型(文本型)
- 关系型数据库
- 面向对象型数据库
- 非关系型数据库

simple file
- 对于简单(有时是专门的)应用程序,通常非常快,但是对于“复杂”应用程序,可能会很慢
- 低可靠性
- 应用程序依赖于优化
- 很难维护(并发问题)
- 几乎被淘汰
relational DB system
- 高可靠性
- 应用程序不依赖于优化,因此相对快速
- 非常适合越来越多的应用程序(由于大型主存机和ssd的使用越来越多,速度也越来越快)
- 一些RDB还支持面向对象模型,例如Oracle、DB2和XML data+queries
- 对于一些特殊的应用程序还是很慢
OO DB system
- 以对象形式直接存储,而非关系表的形式
- 可能包含数据(属性)和方法-类似于面向对象
- 在某些应用上可能比较慢
- 可靠的
- 有限的应用程序独立优化
- 非常适合需要复杂数据的应用程序
- 不幸的是,许多商业系统没有在RDB技术的威胁下存活下来,基本上从市场上消失了
NoSQL system
- 灵活的形式
- 为数据的存储和检索提供一种机制,而不是使用表关系建模的数据,通常与 “大数据” 联系密切
- 设计简单,应线性伸缩
- NoSQL折衷了一致性并允许副本——我们将在后面进一步讨论这个问题,可能会更快一些
- 大多数NoSQL数据库提供了“最终一致性”,这可能会导致从旧版本读取数据,这个问题被称为过时读取——我们将在后面了解更多
NOSQL 数据的种类
- Key-value
- 将数据存储为键值对的集合,其中每个键是唯一的,每个记录有许多不同的字段
- 为什么有用: 许多应用程序不需要事务处理和刚性的表达功能,例如网络搜索,大数据分析可以使用MapReduce技术
- 可以被视为NoSQL数据库的一种类型,用于构建非常快的,高度并行的大数据处理- MapReduce和Hadoop
- 仅在键-值对级别(行更新)进行原子更新
- Document-based
- Column-based
- Graph-based
存储系统(lecture3N4)
- 存储系统一般不会是简单的一块硬盘组成的,通常是一个包含多个硬盘(通过网络进行连接和访问)的系统
存储区域网络(Storage Area Network(SAN))

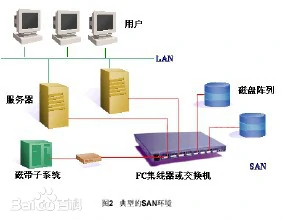
- 采用 RAID 存储阵列(Redundant Array of Inexpensive Disks)
- 采用网状通道(fibre channel)FC 技术连接服务器和存储阵列
- 采用共享硬盘文件系统( shared-disk file systems)
- 允许自动备份功能(automated back up)
- 几十年来,它一直是数据中心类型的主机系统的基本存储
- 不同的版本随着时间的推移而发展,以支持更多的数据,但基本原理即使在今天也是一样的
- 具有自己独特的网络容量(networking capacities)
- 一个磁盘的失效概率与需要设计选择的100个磁盘不同
通信开销(communication costs)
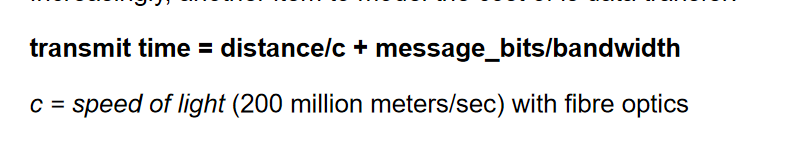
数据库体系结构

中心化数据库(centralized)
- 存储在一个位置的数据


分布式数据库(distributed)
- 数据分布在多个节点上,可以位于不同的位置

万维网数据库(WWW)
- 存储在世界各地,数个数据所有者,小规模的组织数据

网格数据库(grid)
- 类似于分布式,但每个节点有结构地管理自己的资源

点对点数据库(P2P)
- 类似于网格,但节点可以随意加入或离开网络(不像网格)

云数据库(Cloud)
- 泛化的网格数据库,但资源按需访问,由公司运行

为什么云数据库如此有竞争力和吸引力


关系数据库结构

事务处理(Transaction processing)


事务的四大性质

常见数据库系统的生命周期

数据库查询语句的开销以及优化的方法
- 通常在实践中,我们采用启发式的方式对查询语句的策略进行选择
- 启发式优化通过使用一组规则来转换查询树,这些规则通常(但不是在所有情况下)可以提高执行性能
- 提前进行 selection
- 提前进行 projection
- 在执行其他类似操作之前执行最限制性的选择和连接操作(即产生最小的result size 的策略)


- 通常对于简单的操作采用启发式的原则
- 对于昂贵的操作采用枚举成本的策略
索引系统(indexing) lecture5
- 索引文件由表单搜索键(指向数据所在位置的指针)的记录(称为索引项)组成,每个记录(record)可以称为一个 index entry。search key 指的是在原表中建立索引的属性(attribute)或属性集

索引分为两种:

顺序索引(ordered indices)
- search key 按照一定的顺序进行存储
哈希索引(hash indices)
- search key 按照某种方式均匀地分布在一个桶上
如何提高 disk 的访问速度
- 减少访问磁盘的次数
- 一次 seek 尽可能得到更多的值

B+ 树索引结构
- 可以在不断增加文件的系统中保持文件的顺序,从而可以一直可以采用二分查找的方式进行索引
B+ 树索引文件的优点
- 在插入和删除时,通过小的局部更改灵活地重新组织文件系统。
- 不需要对整个文件系统不断进行重组而保持良好的索引表现。
B+ 树索引文件的缺点
- 额外的插入和删除开销以及空间开销
B+ 树的定义

B+ 树的高度

Hash 索引结构


bitmap 索引


其他数据类型的索引







事务(Transaction)(lecture6N7)

操作的类型(Type of actions)

事务的性质(ACID)
原子性(Atomicity)
- 要么一个事务中的所有操作都完成,要么所有都不完成

一致性(consistency)
- 对于规则是一致的
- 比如 studentid 没有重复,没有负数资金的转移
- 主要是防止多个事务运行的时候产生不同的“状态”从而影响数据质量


- 图中显示的就是 季节这个“状态” 在事务开始的前后发生了改变
独立性(Isolation)

- 相当于如果有两个事务,那么他们在本质上是串行进行的,而不是严格意义上的并行发生
为什么要执行并发操作

持续性(Durability)

Duplex write(双写方法)


循环冗余校验(Cyclic Redundancy Check(CRC))




- 通过把校验码重新加入到原来的序列中进行计算,如果余数是零则证明冗余校验得到的校验码是正确的
如何定义事务


宿主变量(host variable)
- 定义宿主变量的方式是通过语句 BEGIN DECLARE SECTION 和 END DECLARE SECTION
- 访问宿主变量的时候要通过 :来访问

数据类型(data types)

错误处理(error handling)
- 通过语句 INCLUDE SQLCA 来报告运行时错误
- 通过 WHEREVER GOTO语句告诉预处理程序生成错误处理代码来处理由DBMS返回的错误(如示例所示)。

单例模式选择(Singleton SELECT)
- 只返回一行数据

构造 transaction 的例子


- 用 : 来表示的是实际的引用的 host 变量的值; 不加:的只是一个变量

事务的限制(Limitation)

- 因为 S1, S2, S3 是一个事务的三个步骤,因此如果 roll back 的话,三个步骤都会撤销
为事务增加保存的断点(SAVE POINT)
- 增加断点可以避免一次性回滚到最原始状态


嵌套事务(Nested Transaction)及其规则

commit 规则
- 子事务可以 commit 也可以终止,但 commit 生效的前提是 parent 事务 commit
- 子事务拥有 A (原子性), C(一致性), 和 I (独立性)的性质 但没有 D (持久性)即他不能在 parent 没有 commit 的情况下单独写入磁盘
- 子事务的提交使其结果仅对其父事务可用,即对磁盘是无效的,但是对父类的运算是有效的

Roll back 规则
- 一个子事务 roll back 那么他的全部子事务必须强制性 roll back
可见性规则(Visibility Rule)
- 只有子事务 commit 之后他对 parent 才是可见的
- parent 事务对于所有的子事务都是可见的
- 子事务访问对象时,parent 事务不应该更改对象

事务管理—事务处理监控(Transaction Processing Monitor)
TP监视器的主要功能是集成系统组件和管理资源
- TP监视器管理客户机和服务器之间的数据传输
- 将应用程序或代码分解为事务,并确保所有数据库都被正确更新
- 如果发生任何错误,它还会采取适当的操作

TP监控服务
- 异构性:如果应用程序需要访问不同的DB系统,单个DB系统的本地ACID属性是不够的。本地TP监视器需要与其他TP监视器交互,以确保总体ACID属性得到满足。
- 为此目的必须采用两阶段提交协议的形式(稍后将讨论)。
- 控制通信:如果应用程序与其他远程进程通信,本地TP监视器应该保持进程之间的通信状态,以便能够从崩溃中恢复

- 终端管理:由于许多终端运行客户机软件,TP监视器也应该在客户机和服务器进程之间提供适当的ACID属性
- 演示服务:这与终端管理在某种意义上类似,它必须处理不同的演示(用户界面)软件
- 上下文管理:例如维护会话等。
- Start/Restart:注意:在基于TP的系统中,Start和Restart没有区别。

TP 处理结构分类
终端(客户机)希望服务器执行某些函数,而服务器又需要从数据库中获取一些数据。对于每个终端,必须有一个最终获得输入、理解函数请求并确保函数被执行(或执行函数本身)的进程。有很多方法可以实现这一点
○ 每个终端有一个进程,执行所有可能的请求

- 非常昂贵的内存,上下文切换也会导致问题
○ 所有终端执行所有可能的请求的过程

- 这可以在多线程环境下工作,但不能进行适当的并行处理,一个错误会导致大规模的问题,不是真正分布式的,而是整体的
○ 多个通信进程和服务器

并发控制(Concurrency Control) lecture8N9
独占访问(exclusive access)
- 为了得到没有争议的结果,在一个时间点必须通过独占访问来保证数据


并发控制的方法(编程)

Dekker 算法


OS支持原语(通过中断调用)

自旋锁(Spin lock)
- 最常用的是:自旋锁(Spin lock)


自旋锁的实现细节


信号量(semaphores)实现并发控制


- 计算机信号量有一个 get()例程获取信号量(可能会等待直到它是空闲的),还有一个双重give()例程将信号量返回到空闲状态,可能会向一个等待的进程发送信号(唤醒)。

信号量举例

自旋锁与信号量的对比

死锁(deadlocks)
- T1 先请求 A 资源,对 A 上锁之后,对 A 进行写操作,同时 T2 锁住 B 并对 B 进行写操作
- T1 尚未释放 A 就去请求 B, 而 T2 也未释放 B 去请求 A, 导致他们互相等待从而形成死锁

解决办法


避免死锁的方法
- 预先声明所有必要的资源并在单个请求中分配。
- 定期检查资源依赖关系图中的周期。如果存在一个循环——回滚(即终止)一个或多个事务以消除循环(死锁)。所选择的事务应该是开销最低的(例如,它们不会消耗太多资源)。
- 允许等待锁上的最大时间,然后强制回滚。许多成功的系统(IBM、Tandem)都选择了这种方法。
- 许多分布式数据库系统只维护本地依赖关系图,并对全局死锁使用超时。

并发控制和 ACID 中的 Isolation 的关系
- 使用并发控制来确保数据库系统能够保持 Isolation 的性质



事务中可能的依赖关系

Lost update
- o 代表 object 是 T1 和 T2 的共同处理的目标
- 1,2,3分别代表不同的数据
- 丢失更新这个状态表述的是,T1 和 T2 分别对 o 写了不同的东西,导致 T1 的 写操作被覆盖了
Dirty Read
- 脏读就是读到了中间的无效数据
- T1 在两次 T2 操作的中间,读到了脏数据
Unrepeatable Read 不可重复读
- T1 两次读到的数据是不同的,因为 T2 中间写了一次数据
如何寻找依赖关系




事务中依赖关系的定义


找出依赖关系的方法


找依赖关系的意义

- 通过解决依赖关系,把原本依赖的关系转成串行的关系,可以符合 isolation 的条件

如何避免依赖现象(使用锁)Lecture10



- 共享锁对共享锁是兼容的,但是对排它锁不兼容
- 排它锁对其他的锁都不兼容


独立性理论(Isolation Theorems)
独立性理论的前期说明

锁定理(Locking theorem)+ 回滚定理(Rollback Thearoem)

- 回滚的时候 Unlock + rollback 是一个阶段不是两个阶段
串行化(Serializability)
- 用两阶段锁来完成串行化

使用锁带来的效率问题(Efficiency concerns)

- 使用大量的锁会导致效率变低
- 因此对 Isolation 进行分级,减少不必要锁的数量
解决方案:Isolation 分级
Degree3:三中依赖都不准出现
- 不能存在 更新丢失、 脏读、 重复读,因此这种 Isolation 属于最高级别,是真正的 Isolation
- 同样地,对三种类型的冲突都有效:write -> write, write -> read, read -> write

Degree2:可以出现重复读
- 只对两种冲突有效:write -> write, write -> read

Degree1:不能存在 lost update
- 可以存在脏读和重复读
- 只能解决 write -> write 冲突
- 对读操作不上锁,即只规范 write 操作

Degree0:允许任何冲突

锁的拓展(幻影锁和谓词锁(Phantom and Predicate locks))

















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











