







文章目录
- 功能模型(functional)和非功能(non-functional)模型
- 体系结构模型(Architectural Model)
- 进程间的通信
- 问题(Question)
功能模型(functional)和非功能(non-functional)模型

功能模型
- 关注的是分布式系统如何实现具体的功能
- 功能模型关注的部分是 tangible(明确的,切实的,有形的) 的,即容易直接感受到其变化的
- 功能模型是 time-independent (不随时间改变) 的;即在整个分布式系统的生命周期内都是一致的
非功能模型
- intangible 的
- 时间、可靠性、安全性 这些问题是 非功能模型所关注的,即无形的,不容易直观感受到的
体系结构模型(Architectural Model)
- 体系结构模型关注的是:
- 这个系统中的实体和通信组件(不同的进程),以及他们扮演的角色(Achitectural elements),
- 他们之间是如何进行通信的(Architectural pattern);
- 是如何处理常见问题的(Associated Middleware solutions)
按照这些标准来划分可以有多种不同的分布式系统体系结构。
体系结构中进程扮演的角色(Process Role)
用户接口的进程(User Interface Process)
- 让其他的进程可以通过 用户接口进程 访问服务器

用于缓冲数据的进程(Data Cache Process)
- 用于高速的数据缓冲,可以让其他进程快速访问数据

用于通信中继的进程(Communication Relay Process)
- 一个进程可以通过中继与其他的进程进行 间接 通信

工作管理进程(Job Manager Process)
- 一个可以调度 分布式系统 中其他进程的进程

索引或注册服务器进程(Index or Registry Server Process)
- 一个进程,帮助定位分布式系统中资源的位置

数据库服务器进程(Database Server Process)
- 一个在分布式系统架构中专门提供数据库服务的进程

服务器认证进程(Authentation Server Process)
- 专门用来辨别用户是否可以访问服务器的进程

体系结构中的中间件(Middleware)
- 如果分布式系统中的某个进程可以扮演上述的多个角色(Process Role),从而形成一个子系统(Sub-system),那么这个具有集成功能的子系统我们将它称为中间件(Middleware),下述都是中间件:
- 可靠的通用容错 Key-value 存储系统:Reliable Key-value Storage
- 集群资源管理系统:Cluster Resource Mangement
- 企业用户管理系统:Enterprise User Mangement
- 高性能信息系统:High Performance Messaging

- 一个分布式系统可以根据自己的需要选择合适的多种中间件。
体系结构中机器扮演的角色(Machine Role)
- PC 端 (Desktop / PC):可能有公网 ip
- 移动终端 (Mobile Device):通常没有公网 ip
- 前端(Front End Server ):有公网 ip
- 后端(Back End Server):使用私网 ip
- 虚拟机(Virtual Machine / Server)

接口和 IPC 机制
接口
- 分布式进程不能够直接调用其他进程的内部方法,因此参数传递需要重新思考;因为分布式的进程之间不共享内存,无法通过引用来调用;所以需要定义接口来完成远程的功能调用工作
不同的 IPC 机制
- 可以被选择的 IPC 机制如下:
- 直接的 IPC (Direct IPC): 分布式系统中进程间通信的相对底层(可能是最低层)支持,例如共享内存、套接字、多播通信
- 远程调用(Remote invocation): 基于分布式系统中通信实体之间的双向交换,并导致调用远程操作、过程或方法,例如请求-应答协议、远程过程调用、远程方法调用
- 间接通信(Indirect communication):
- 空间解耦(space uncoupling): 发送者不需要知道他把信息发给谁
- 时间解耦(time uncoupling): 发送者和接受者不需要同时存在
为分布式系统中的不同设备分配任务(进程)

进程建模、进程和设备的分配
- 假设 m m m 台机器,每个进程在一个机器上运行,
- 一共有 n n n 个进程 i ∈ N = { 1 , 2 , . . . , n } i \in N = \{1,2,...,n\} i∈N={1,2,...,n}
- P i = j , j ∈ M = { 1 , 2 , . . . , m } P_i=j, j \in M=\{1,2,...,m\} Pi=j,j∈M={1,2,...,m} 代表第 i i i 个进程在设备 j j j 上
- 我们简化过程,假设 m = n m=n m=n ;很多分布式系统采用这种方式进行建模,比如 peer-to-peer (p2p)文件共享系统;参与的每个用户运行一个进程,没有其他的进程或者设备参与
进程的资源要求和设备的容量的建模
- 继续扩展模型,如果 L j = ∣ { i ∣ p i = j } ∣ L_j=|\{i|p_i=j\}| Lj=∣{i∣pi=j}∣,其中 L j L_j Lj代表放置在设备 j j j 上的进程的数量。 (因为 P i = j P_i=j Pi=j 代表进程 i i i 放置在机器 j j j 上,所以如果 i i i 有多个的话,在 j j j 上的进程就是一个集合)
Note: 负载 是进程消耗设备资源的一阶度量(first order measure),一台设备上的进程开销就是设备的负载
- 如果我们假设分布式系统中所有设备的容量都为 K > = 1 K>=1 K>=1,即一台设备上不能超过 K K K 个进程;我们就说这个系统中的设备是 homogeneous (容量均匀的)的;
- 与之相反的,如果每个设备的容量都不一样,我们就可以称这些设备的容量是 heterogeneous (不均一的);例如我们假设整个系统中的设备容量表示为 C j ∈ Z > 0 C_j \in Z^{>0} Cj∈Z>0,其实 homogeneous 是 hetergeneous 的一种特殊的情况,即 所有的 C j C_j Cj 都相等
- 在上述的 heterogeneous 的情况下,如果 C j ∈ R > 0 C_j \in R^{>0} Cj∈R>0 也就是说容量是 非整数个进程的情况下 比如 C 1 = 5.5 C_1 = 5.5 C1=5.5 就说明他可以处理 5 个完整的进程,但是不能负载第 6 个进程了
- 我们可以用 C j , r e s o u r c e C_{j,resource} Cj,resource 来表示第 j j j 个机器上的某种资源的容量。比如,我们可以用 C j , c p u C_{j, cpu} Cj,cpu 来表示在第 j j j 个机器上的 cpu 容量
- 对网络资源进行建模时,我们也倾向于谈论上传和下载的比特率(bitrate)
- 我们对一个进程消耗的资源进行评估,我们使用 P i , r P_{i,r} Pi,r 代表第 i i i 个进程消耗的资源 r r r 的数量,我们要取进程中消耗这种资源的最大值来进行评估;进而我们可以得到下面的公式:
L j , r = ∑ i ∣ P i = j P i , r L_{j,r}=\sum_{i|P_i=j}P_{i,r} Lj,r=i∣Pi=j∑Pi,r
- j j j 是一个给定的设备
- r r r 是一种给定的资源(cpu 或其他)
- i i i 是设备 j j j 上的第 i i i 个进程
负载均衡(load balancing)分析和配置问题(placement problems)-
- 我们可以制定一些规则,使得每个 设备不能负载超过本身资源的容量。即
L j , r < = C j , r f o r a l l r ∈ R L_{j,r}<=C_{j,r} ~for ~all ~r \in R Lj,r<=Cj,r for all r∈R - 我们或许可以找到一种分配进程的方式来实现某种目标,例如最小化消耗最大的资源
r
r
r,即
arg min { P 1 , P 2 , . . . , P n } max j { U j , r } \argmin_{\{P_1,P_2,...,P_n\}} \max_{j}\{U_{j,r}\} {P1,P2,...,Pn}argminjmax{Uj,r} - 或是最小化所有机器上的平均资源消耗,即:
arg min { P 1 , P 2 , . . . , P n } max j { 1 ∣ { R } ∣ ∑ r U j , r C j , r } \argmin_{\{P_1,P_2,...,P_n\}} \max_{j}\{\frac{1}{|\{R\}|}\sum_r\frac{U_{j,r}}{C_{j,r}}\} {P1,P2,...,Pn}argminjmax{∣{R}∣1r∑Cj,rUj,r} - 或是寻找一种分配方式,最小化设备的总数量,即
arg min { P 1 , P 2 , . . . , P n } max { P i } \argmin_{\{P_1,P_2,...,P_n\}} \max \{P_i\} {P1,P2,...,Pn}argminmax{Pi}
进程间的通信
- 在构建体系结构模型的过程中,进程间通信(IPC)是不可或缺的模块;通过将通信定义为 两个进程之间的有向边,我们可以将模型扩展为包括IPC的概念。
- i , i ′ ∈ N i,i^{'} \in N i,i′∈N 可以写成一个 tuple 元组 ( i , i ′ ) (i,i^{'}) (i,i′),因此所有的进程间通信可以表示成 i , i ′ ∈ ε n i,i^{'} \in \varepsilon_n i,i′∈εn(如果 i , i ′ i,i^{'} i,i′是能通信的)
- 如果对于两个进程 a , b ∈ N a,b \in N a,b∈N 之间是不能直接进行通信的,那么 ( a , b ) ∉ ε n (a,b) \notin \varepsilon_n (a,b)∈/εn 并且 ( b , a ) ∉ ε n (b,a) \notin \varepsilon_n (b,a)∈/εn,有时我们也用无向边来表示(当通信的方向不重要的时候,或者任意一方都可以初始化通信的时候(即,任一方都可以做客户端的时候)),写作 { i , i ′ } \{i,i^{'}\} {i,i′}。这种情况下 { i , i ′ } = ( i , i ′ ) , ( i ′ , i ) ∈ ε n \{i,i^{'}\}=(i,i^{'}),(i^{'},i) \in \varepsilon_n {i,i′}=(i,i′),(i′,i)∈εn
进程间的通信模式(connection patterns)/ (Architectural Pattern)

中心化模式(Centralized Pattern)

- 一个 server 占据整个系统的中心,其他的 client 不会跟同级的 client 进行交互,他们只能和 server 进行交互
- 特点:
- 容易实现
- 所有数据在 server 中存储和维护
- server 坏,整个分布式系统都崩 即,单点故障
- 由于客户端不会和同级的客户端进行交互,因此避免了隐私暴露(privacy),保障了信息安全(security)
- 一个 client 坏了,不影响其他 client 的访问,也不影响服务器的工作
- 一个服务器不能够支持太多的 client 访问,存在 scalability bottleneck (伸缩性瓶颈)
- 依赖于服务器对于 client 的地理位置,不同地方的 client 的性能不同,可能有很大差异
去中心化的模式(Decentralized Pattern)

- 去中心化的典型代表就是 “peer-to-peer” 架构(P2P)
- 特点:
- 同级的服务器之间可以相互访问
- 比中心化的模式更难实现,进程需要既充当 client 又充当 server
- 数据均匀地(evenly)分布在不同的 peer 节点上
- 这种分布式系统对于进程故障的鲁棒性很好,因为任何一个 peer 发生故障都不会比其他的 peer 发生故障有更差的结果
- peer 之间通过网络连接,他们的 ip 相互暴露,因此他们的隐私都是安全的
- 系统中的资源会因为新节点的加入而增加,可伸缩性很好(scalability)
多服务器模式(Multi-Server Pattern)

- 当一个 server 不能支持大量的 client 访问的时候,通过增加 server 来提高网络的容量
- 特点:
- 每个 client 都可以和任意的 server 进行通信,同级的 client 之间不能通信
- 每个服务器上的数据都是一份拷贝,因此单个的服务器故障不会影响整个系统
- 多服务器架构向客户端暴露了更多的服务器 ip 这样容易导致潜在的安全问题
- 可以根据不同的客户端匹配适合的服务器,减少了客户端之间因为距离产生的差异
多层模式(Multi-tier Pattern)

- 多层模式的功能是水平的,而分布却是垂直的
- 离客户端最远的一层往往是数据存储层,它维护分布式系统的所有数据: 永远不会发生与客户端的直接通信,这增加了安全性
- 离客户端最近的层通常不会在自身之间通信:这提供了隔离并减少了同步的开销。该层访问数据存储层,为客户端获取数据。
- 每一层的服务器进程都像是对下一层服务器的客户端进程(服务器的不同层之间的通信就类似服务器和客户端之间的通信)
- 比多服务器更复杂,延迟随着层数的增加而增加
代理模式(Proxy Pattern)

- 代理是一个位于客户端和服务器之间的进程,中转请求和响应
- 特点:
- 客户端不与服务器进行直接通信,这就产生了额外的延迟(Extra latency)
- 所有的数据都经过代理进行转发和响应,容易出现单点故障(single point of failure)和瓶颈 (bottleneck),代理坏了整个分布式系统就不工作了,平时转发和相应的数据太多,代理不堪重负会有 bottleneck
- 服务器端使用的代理可以将请求转发到相应的服务器,例如web代理可以转发到 web 服务器和 websocket 服务器
- 可以组织和管理服务器和客户端之间的通信,安全性很好
移动编码和移动代理(Mobile code and mobile agents)

- 在移动代码模式中,服务器提供的进程在客户端机器上执行,反之亦然。在移动代理模式中,数据会随移动代码一起复制
- 特点:
- 对于移动代码,将工作迁移到到客户端可以减少服务器上的负载,或是在服务器上运行客户端代码可以避免客户机上的负载。这两种情况都避免了一些网络通信。
- 移动代理是移动代码,它还维护用代理代码复制的状态。
- 移动代理可以从一个服务器移动到另一个服务器,运行任务并收集数据。例如,如果客户端需要进行复杂的查询,最好使用在拥有该数据的服务器上执行的移动代理,因为在客户端进行查询可能会占用过多的网络资源。
- 执行不受信任方提供的代码具有很高的安全风险
- 不均衡的资源是一个挑战(Heterogeneous resources are a challenge)
进程间通信属性(Process communication attributes)
- ϵ n \epsilon_n ϵn 表示进程之间必要的通信
- IPC 上的应用程序需求可以被描述为进程间通信的 edge 属性;对于每个 ( i , i ′ ) ∈ ϵ n (i,i^{'})\in \epsilon_n (i,i′)∈ϵn
- 使用 w i , i ′ w_{i,i^{'}} wi,i′ 表示应用程序 i i i 和 应用程序 i ′ i^{'} i′ 之间必须的通信比特速率(bitrate)
- τ i , i ′ \tau_{i,i^{'}} τi,i′ 表示从 i i i 到 i ′ i^{'} i′ 发包允许的最大延迟 τ i , i ′ \tau_{i,i^{'}} τi,i′ 不一定等于 τ i ′ , i \tau_{i^{'},i} τi′,i
-
ρ
i
,
i
′
ρ_{i,i^{'}}
ρi,i′ 表示从
i
i
i 到
i
′
i^{'}
i′ 发包允许的最大丢包率;
ρ
i
,
i
′
ρ_{i,i^{'}}
ρi,i′ 不一定等于
ρ
i
′
,
i
ρ_{i^{'},i}
ρi′,i

机器通信属性(Machine communication attributes)
- ϵ m \epsilon_m ϵm 表示进程之间必要的通信
- 在许多情况下,我们通过描述所有机器之间信道的总体特征来建模底层网络。
- 对于每个 ( j , j ′ ) ∈ ϵ m (j,j^{'})\in \epsilon_m (j,j′)∈ϵm
- 使用 w j , j ′ w_{j,j^{'}} wj,j′ 表示应用程序 i i i 和 应用程序 i ′ i^{'} i′ 之间必须的通信比特速率(bitrate)
- τ j , j ′ \tau_{j,j^{'}} τj,j′ 表示从 i i i 到 i ′ i^{'} i′ 发包允许的最大延迟 τ j , j ′ \tau_{j,j^{'}} τj,j′ 不一定等于 τ j ′ , j \tau_{j^{'},j} τj′,j
- ρ j , j ′ ρ_{j,j^{'}} ρj,j′ 表示从 j j j 到 j ′ j^{'} j′ 发包允许的最大丢包率; ρ j , j ′ ρ_{j,j^{'}} ρj,j′ 不一定等于 ρ j ′ , j ρ_{j^{'},j} ρj′,j
用图论建模
图论建模通信系统的节点和边
- 每个进程之间的通信可以使用一个 graph 来表示 G = ( V , E ) G=(V,E) G=(V,E)
- 顶点的集合为 N N N, 边的结合为 ϵ n \epsilon_n ϵn 因此可以用图论来定义分布式结构的属性
- 分布式系统的拓扑结构关系到其结构的 graph 的性质
- 对于进程
i
i
i 来说,从他出发进入其他进程的 edge 我们记作:
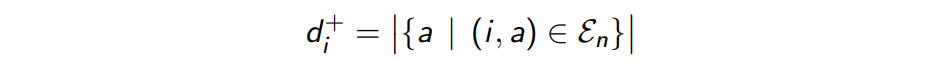
而进入它的 edge 我们记作:
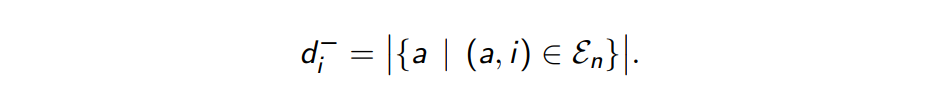
- 大多数情况下,我们想要考虑每个进程连接的进程的数量;即 graph 中节点的度;或者其邻接节点的数量
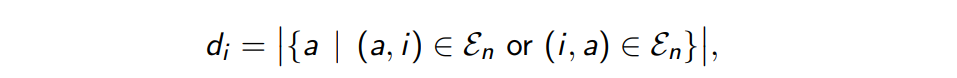
- 我们定义 d = m a x { d i } d=max\{d_i\} d=max{di} 作为一个图的度(degree of graph)或者一个节点可以拥有的最大的邻接节点的数量。
- 我们可以进一步把 d d d 记作进程数量 n n n 的函数 d ( n ) d(n) d(n)。现在我们有了一个拓扑函数,它对理解任何规模的分布式系统都非常有用;例如,如果 d ( n ) = n − 1 d(n) = n−1 d(n)=n−1,那么系统中就会有某个进程与其他每个进程都通信;然而,如果 d ( n ) = n d(n) =\sqrt n d(n)=n,或者 d ( n ) = l o g n d(n) = log n d(n)=logn,或者 d ( n ) = 2 d(n) = 2 d(n)=2 那么我们就有了一种非常不同的分布式系统的拓扑结构。
图论其他性质的应用
- 至此,我们除了使用顶点和边来建模分布式系统中的进程,我们还可以使用图论中的其他知识来总结和了解分布式系统可能具有的其他性质。
- 例如:图的直径(diameter)。如果 Φ i , i ′ = < i , … , i ′ > Φ_{i,i^{'}} =< i,…,i ' > Φi,i′=<i,…,i′>是通过 G G G 从 i i i 节点到 i ′ i^{'} i′ 节点的最短路径,路径长度为路径中经过的边数,则 G G G 的 直径 为所有进程对之间最短路径长度的最大值: m a x i , i ′ ∈ N Φ i , i ′ max_{i,i^{'}∈N} Φ_{i,i^{'}} maxi,i′∈NΦi,i′
- 通过图论的知识对分布式系统进行建模,允许我们通过对图论中性质的理解进而探索分布式系统的丰富的概念空间,从而帮助我们开发具有易于理解的(可预测的)行为的分布式系统
进程和设备(machine)的状态
- 每个进程维护的数据是进程的状态,包括存储在进程地址空间中的所有数据,假设
S
i
p
S_i^p
Sip是进程
i
i
i 的状态,包括下面的内容:

- 每台机器也维护数据,数据是机器的状态,假设
S
j
m
S_j^m
Sjm是机器
j
j
j 的状态,在我们的模型中,机器的状态将包括操作系统的状态,以及机器上所有的永久存储:

- 所有进程的状态 + 所有设备状态 = 整个分布式系统的状态
问题(Question)






















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











