







文章目录
参考
回顾
- 建议先看上一篇文章:AI(人工智能:一种现代的方法)学习之:无信息搜索(uninformed search)算法——广度优先搜索、深度优先搜索、Uniform-cost search
- 找到解的过程是通过不同的搜索策略对所有 state 进行探索的过程;
- 在上一篇文章的例子中,不同的城市就是不同的 state
- 在使用搜索算法的过程中,不同的搜索算法其实只决定了对于当前处于 fringe 状态的 state,选择何种方式进行扩展;
- 无论使用哪种策略(深度、广度优先、uniform cost),都可以通过 在概念上 对所有处在 fringe 中的 state 构造优先级队列来达到目的。他们的区别就是,在深度优先中,将 fringe 的优先级队列的优先级设为深度;而广度有限遍历则是将优先级队列的优先级设为广度;在uniform cost 中将优先级设为 cost 即可。在 实现过程中 通常深度和广度有限是分别使用 stacks 和 queue 来完成的,只有 uniform cost 是采用优先级队列。
启发式搜索
- 在搜索过程中加入包含目标的位置信息,使得搜索的方向能够更加有目的性。这种方式叫做启发式。

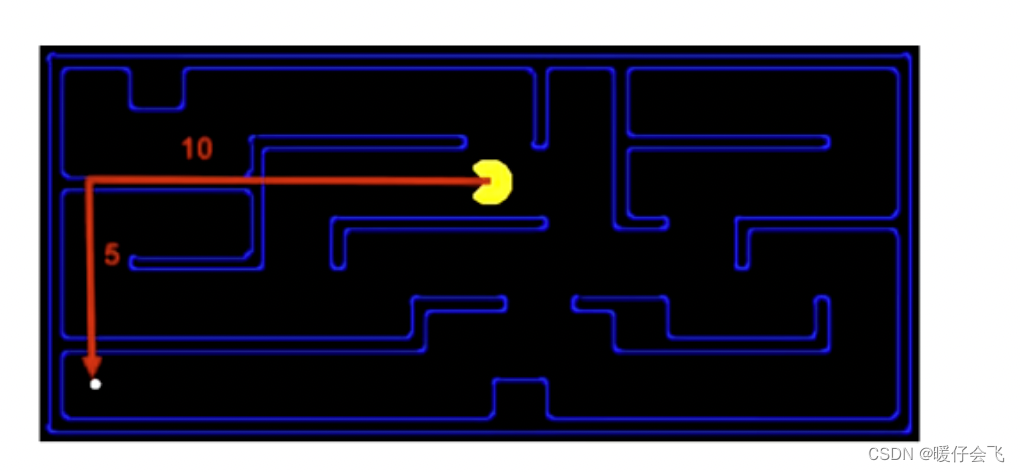
曼哈顿距离
- 两点之间沿着坐标轴方向的累积距离
d
=
(
x
1
−
x
2
)
+
(
y
1
−
y
2
)
d=(x_1-x_2) + (y_1-y_2)
d=(x1−x2)+(y1−y2)
欧几里得距离
- 两点之间的直线距离
d
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
d = \sqrt{(x_1-x_2)^2 +(y_1-y_2)^2}
d=(x1−x2)2+(y1−y2)2
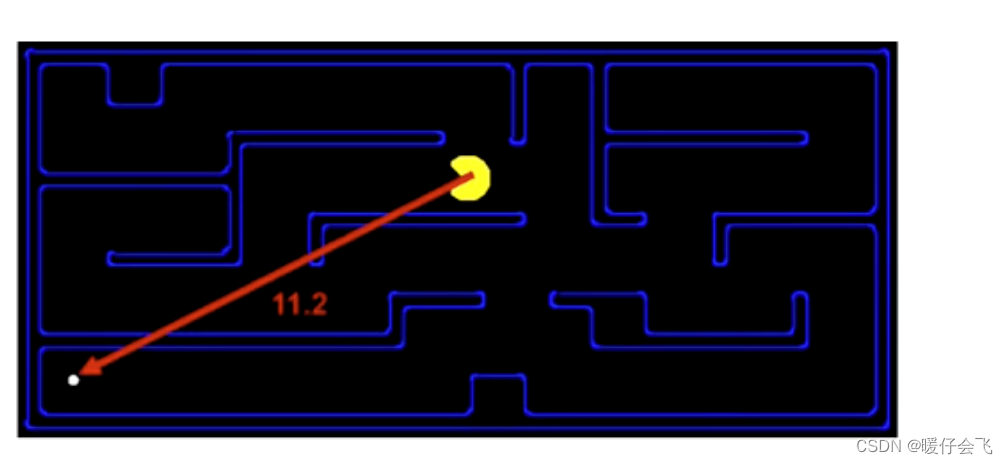
- 但是在这个情景中,欧几里得距离很显然不太适合,因为吃豆人不能对角移动,因此这样衡量的距离不能代表你离目标的真实距离。
问题情境
- 从 Arad 找一条最优的路径去 Bucharest
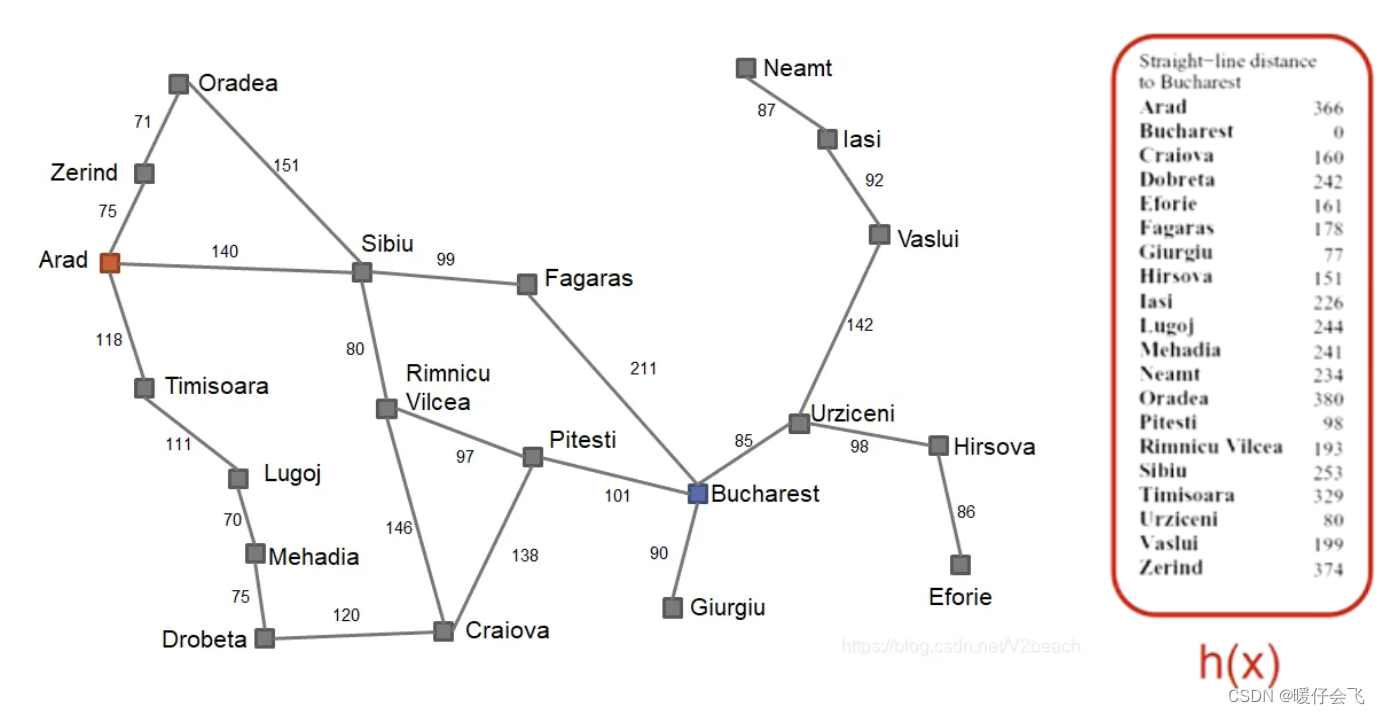
- 右侧表中列出了所有城市到目标城市的 直线 距离,也就是我们使用的 启发式 距离
贪婪算法
- 选择当前离目标点最近的 fringe 作为扩展
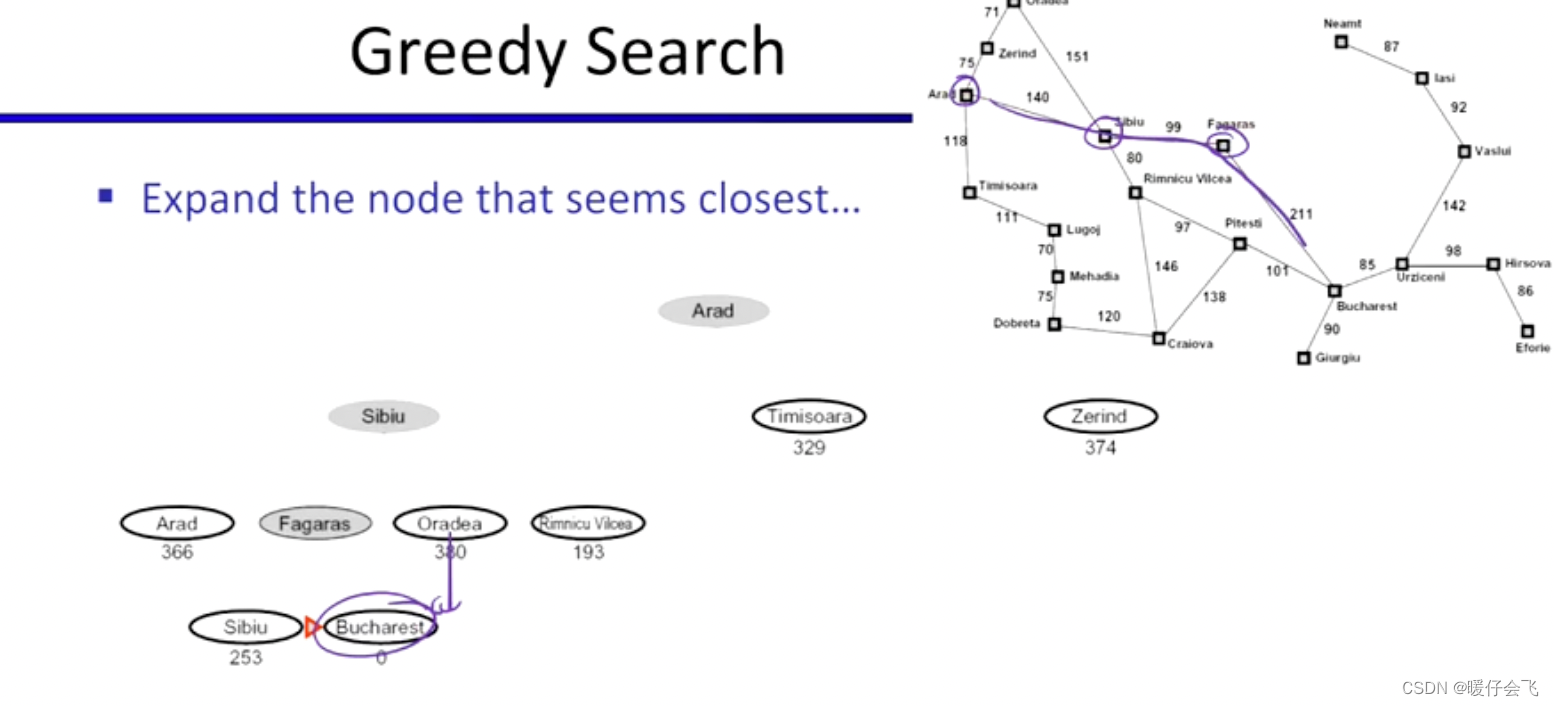
- 第一次扩展只有 Arad,现在 fringe 有 Sibiu,Timisoara, Zerind
- 根据贪婪算法,选择最短的 Sibiu 进行探索,现在 fringe 变成了 Arad, Fagaras, Oradea, Rimnicu Vilcea, Timisoara, Zerind;继续选择最短的 Fagaras 进行扩展…
- 最终形成了 Arad, Sibiu, Fagaras, Bucharest 的路径。
- 但是这个路径不是最优的,很显然红线的轨迹更优:
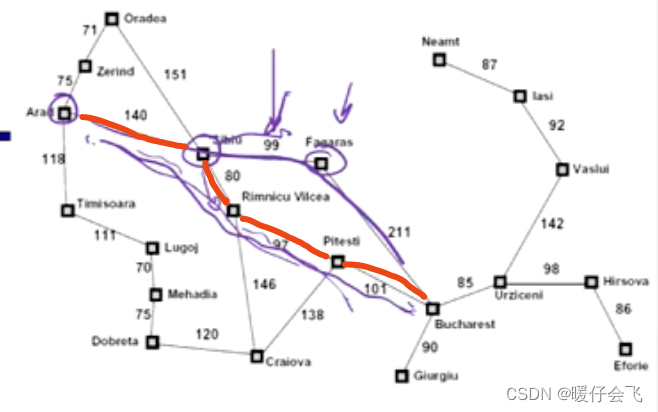
- 但是由于在 Sibiu 的时候,由于我们使用启发式函数评估的 Fagaras 的距离是 178,而 Rimnicu Vilcea的距离是 193,所以就选择了前者,但是真实的结果并不如此。
- 因此贪婪算法总是寻找局部最优解,但是并不能保证全局最优解。
贪婪算法 V.S. Uniform-cost Search

-
如果把 uniform-cost search 比喻成一只乌龟,缓慢的、按部就班地依次对所有当前最短的 cost 进行搜索,最终能够得到最优解,但是比较缓慢。
-
那么 greedy 算法就是兔子,跑的很快,但是容易最终找不到最优的答案
-
对于下面的例子:左边是各个 city 的状态图,右边是根据状态图构建的搜索树。
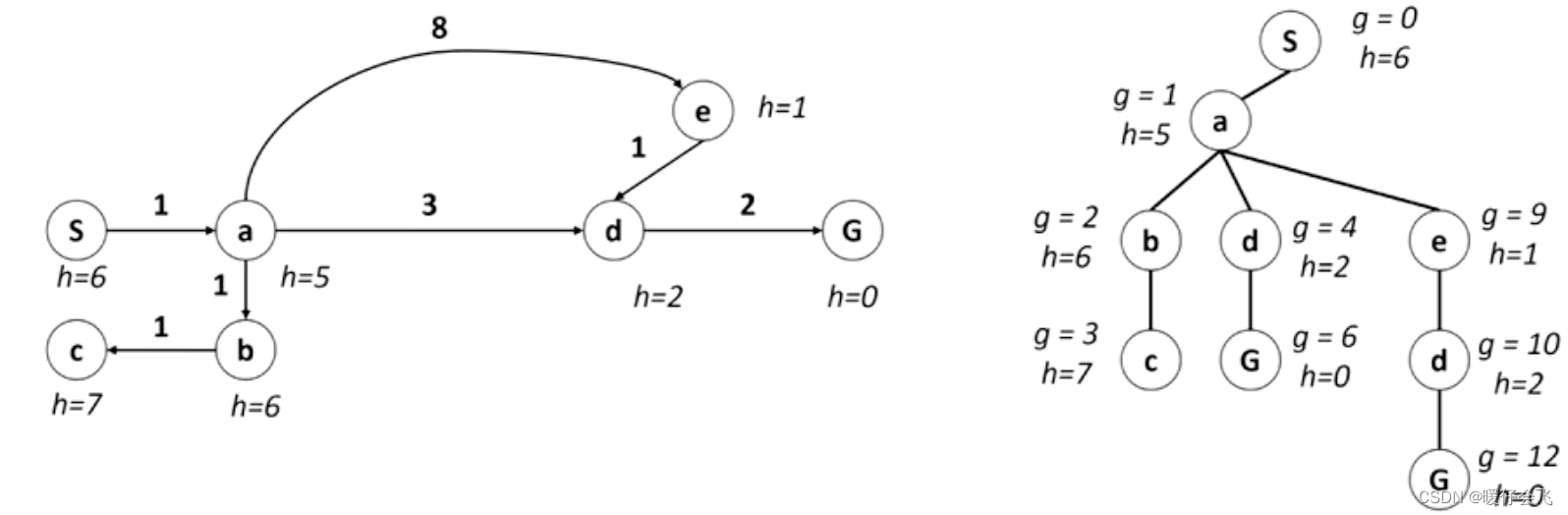
-
对于这样一颗搜索树,其中 g 是从起点到当前 fringe 的累积 cost(也就是 uniform 使用的 cost);如果按照 uniform 的思路,会依次扩展 s - a - c - d - g 然后得到最优解
-
如果对于 greedy 算法,则依据的是当前 fringe 到 goal 的距离,然后选择最短的一条,因此他会依次扩展:s- a - e - d - g 很显然,这并不是最优的。
-
而 A* 算法就是结合了 greedy 和 uniform-cost 的优点。
A* 算法
- 将 g+h 作为启发式函数(代价)来完成下面步骤:
- 注意:将节点压入 fringe 集合的时候如果符合 goal test 的条件,搜索不能马上结束。而应该等到这个 fringe 从数据结构中弹出才能进行 goal test 判断是否结束。也就是说,确定采用当前这个 fringe 当做解的一部分,才算数。
- 首先扩展 S
- 扩展 a,现在 b,d,e 作为 fringe
- 根据 g+h 最小选择 d 作为新的扩展节点进行扩展,fringe 中的节点更新为:b, e, g
- 对 g 进行扩展(加入到解中),进行 goal test ,程序结束。A* 算法完成。
A* 的终止条件
- 再次强调,当 fringe 中出现了 g+h 最小的节点(将节点加入 fringe 的时候),不能马上 return 结果,而是要等到这个 fringe 确定加入解集合之后,在进行 goal test。
例如:
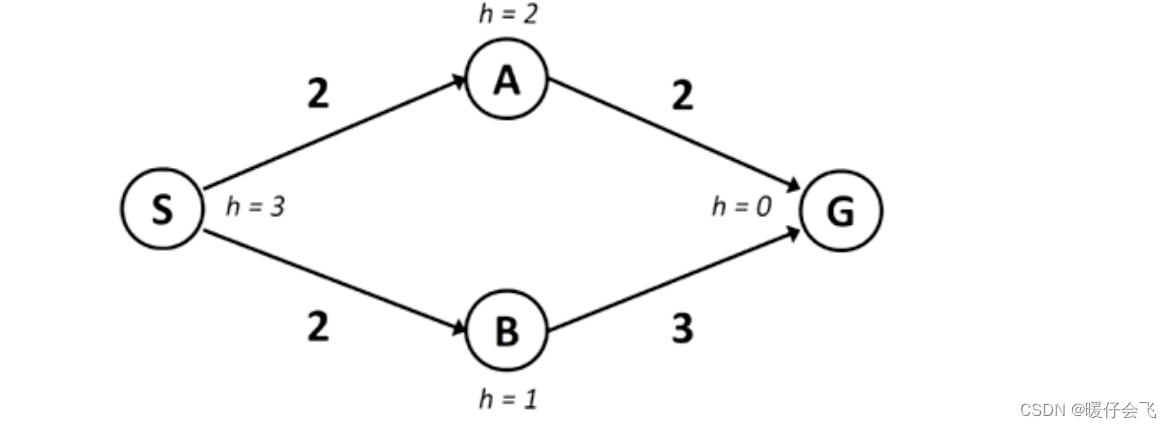
- 在本图中,首先扩展 S, fringe 中加入 A, B,根据 A* 的 g+h 得出应该扩展 B(B: g=2, h=1; A: g=2, h=2);这个时候 fringe 更新为 A, G
- 如果这时候仅凭 G 是否出现在 fringe 中判断是否返回,那么现在就 return 结果了,但是这时候 S-A-G 这条路的总 cost = 5 ;
- 如果按照规定的流程,应该比较 G 和 A 哪个应该被扩展,A 此时的 g+h=4 ; G 的 g+h=5,因此应该选择 A 进行扩展,而这时候 fringe 更新为 G,G;从 A 那边到达的 G 的 g+h=4,因此应该选择扩展 A-G。
保证 A* 最优解——admissible heuristic
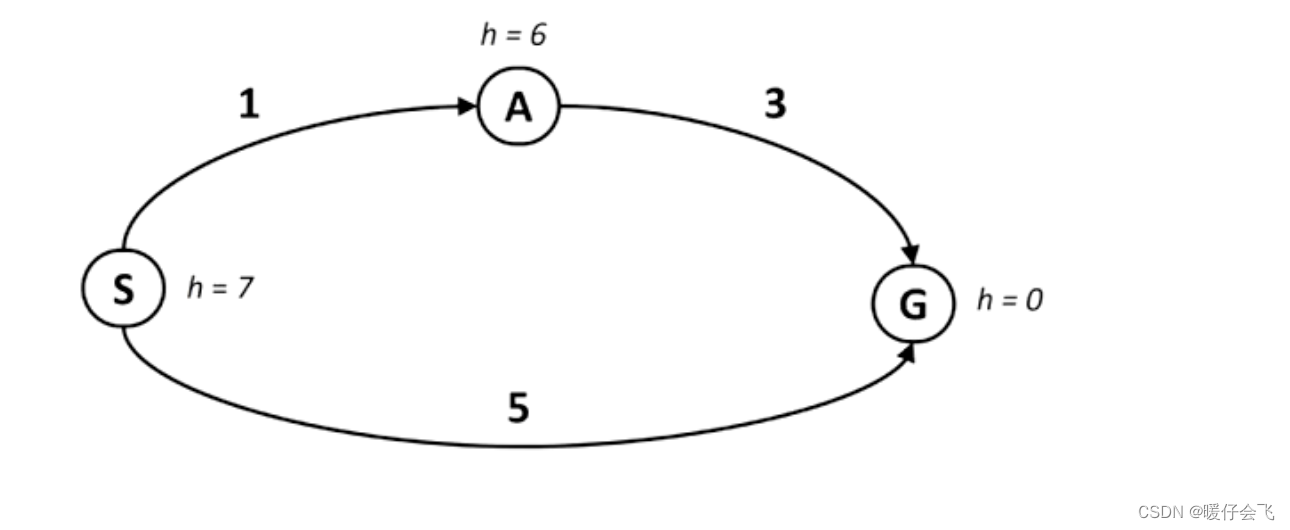
- 在这个图中 S 扩展之后,A 的 g+h=7,G 的 g+h=5 因此会对 G 进行扩展,但事实并非如此,因为 S-A-G 的实际 cost 仅为 1+3=4,也就是说当启发式函数给出的预估值 > 真实的 cost 的时候,启发式函数就不能保证 A* 找到最优解。
- 因此我们想要得到最优解的保证,就要使启发式函数的预估值 < 到目标 state 的真实值;这也叫做乐观启发式 (optimistic heuristic)。

证明 admissible heuristic 是最优性的保证
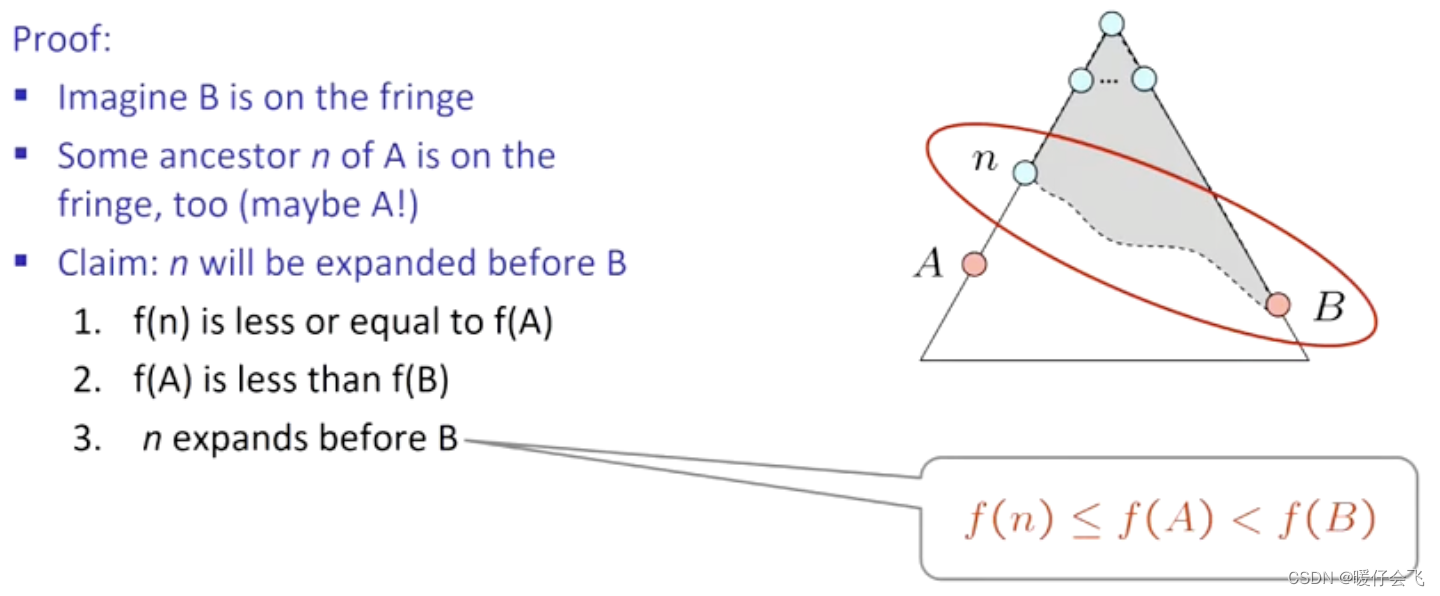
- 假设 A 是最优解, B 是次优解
- 要证明的是: A 或者 A 的某个祖先节点 n n n 和 B 同时都是 fringe, 那么 n n n 或者 A A A 一定会在 B 之前被 explore
- f ( n ) ≤ f ( A ) f(n) \leq f(A) f(n)≤f(A) 因为如果 n 是 A 的 祖先,那么 f ( n ) = g ( n ) + h ( n ) < f ( A ) = g ( A ) + h ( A ) f(n)=g(n)+h(n) < f(A)=g(A)+h(A) f(n)=g(n)+h(n)<f(A)=g(A)+h(A),即 f ( n ) ≤ g ( A ) f(n) \leq g(A) f(n)≤g(A) 因为在目标节点 A 的 h ( A ) = 0 h(A)=0 h(A)=0 也就是 g ( A ) = f ( A ) g(A)=f(A) g(A)=f(A);
- 又因为 A 是最优解,所以 f ( A ) + g ( A ) = f ( A ) < f ( B ) = g ( B ) + h ( B ) , h ( B ) = 0 f(A)+g(A) = f(A) < f(B)=g(B)+h(B), h(B)=0 f(A)+g(A)=f(A)<f(B)=g(B)+h(B),h(B)=0;因此结论是 f ( A ) < f ( B ) f(A)<f(B) f(A)<f(B)
- 因此可以推出 f ( n ) ≤ f ( A ) < f ( B ) f(n)\leq f(A) <f(B) f(n)≤f(A)<f(B) 因此 n n n 只要是 A 的祖先或者 A 自己,那么他就一定先于 B 被扩展,也就证明了只要 heuristic function 是 admissible 的,那么就一定找得到最优解。
A* V.S. Uniform-cost
uniform-cost

A*

五种搜索算法的对比
- 图中浅蓝色的区域代表浅水区,在浅水区探索的代价比深蓝色的深水区要低
BFS

DFS

Greedy
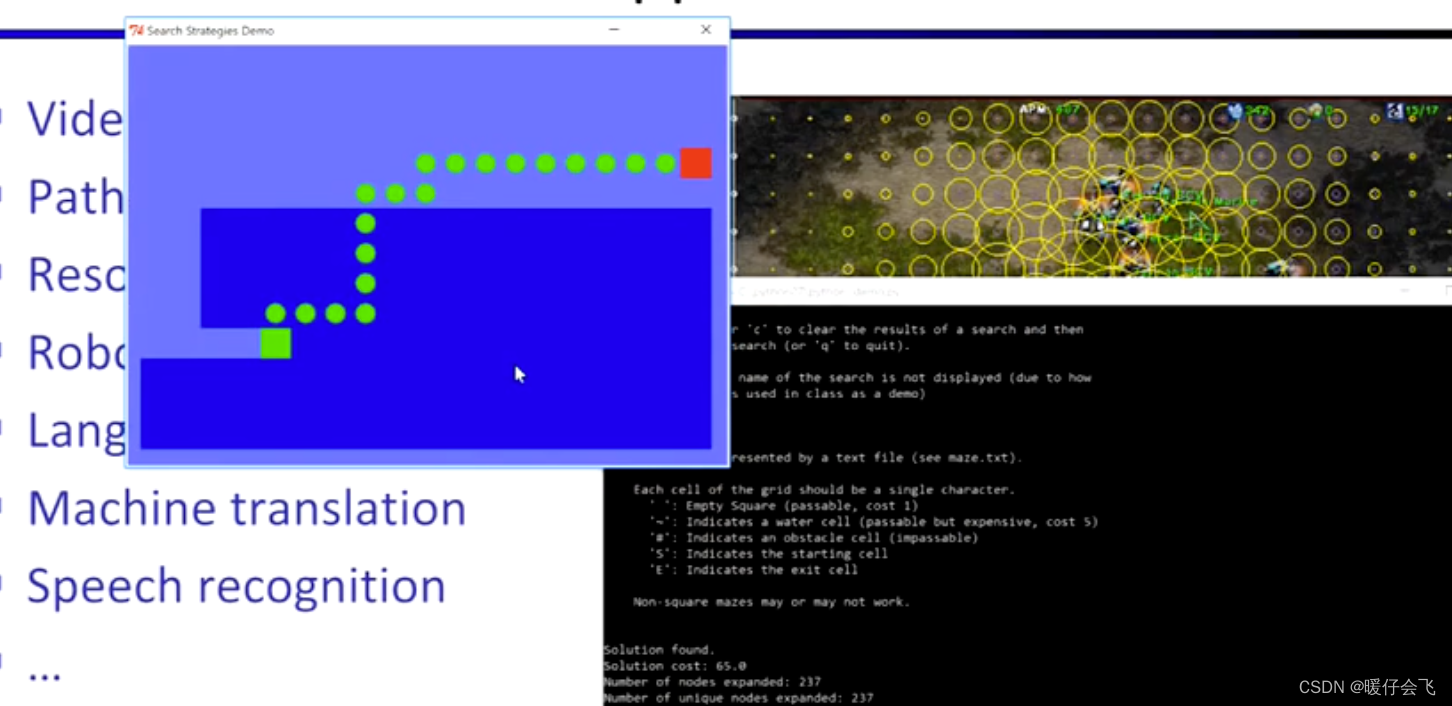
Uniform-cost
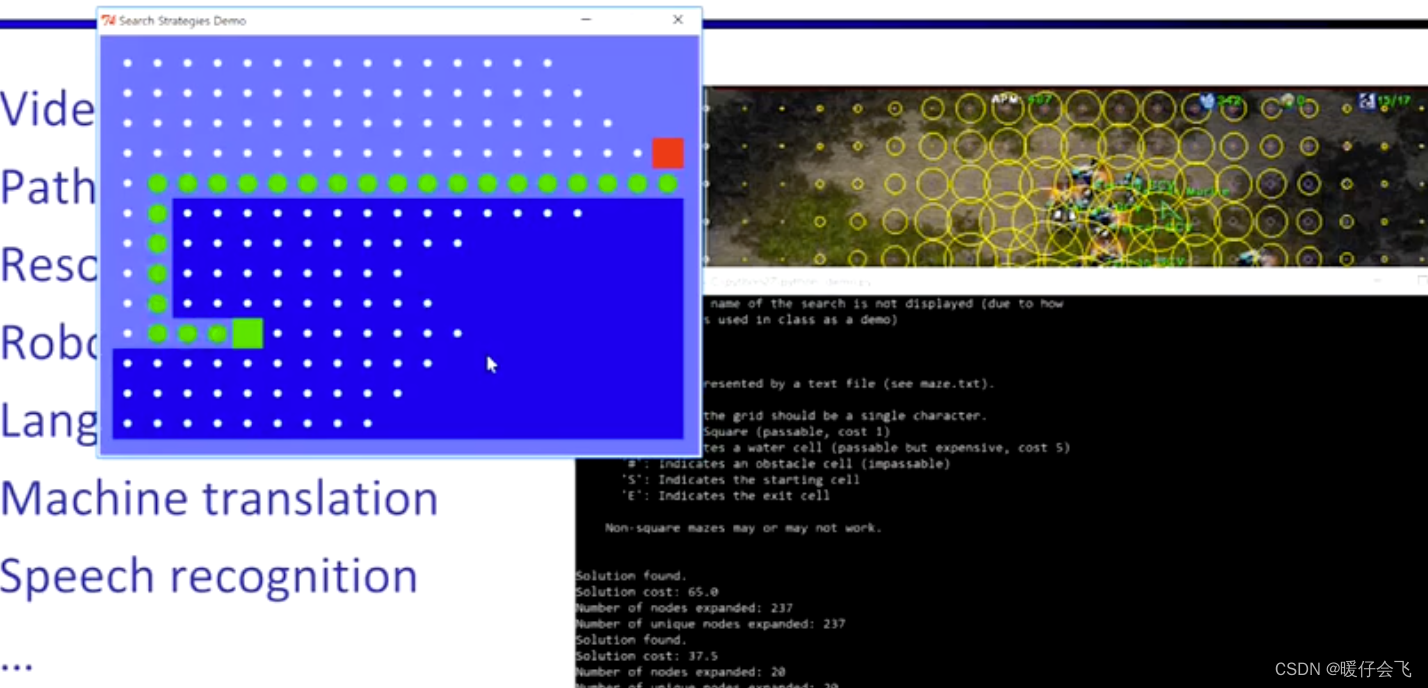
A*
启发式函数设计练习
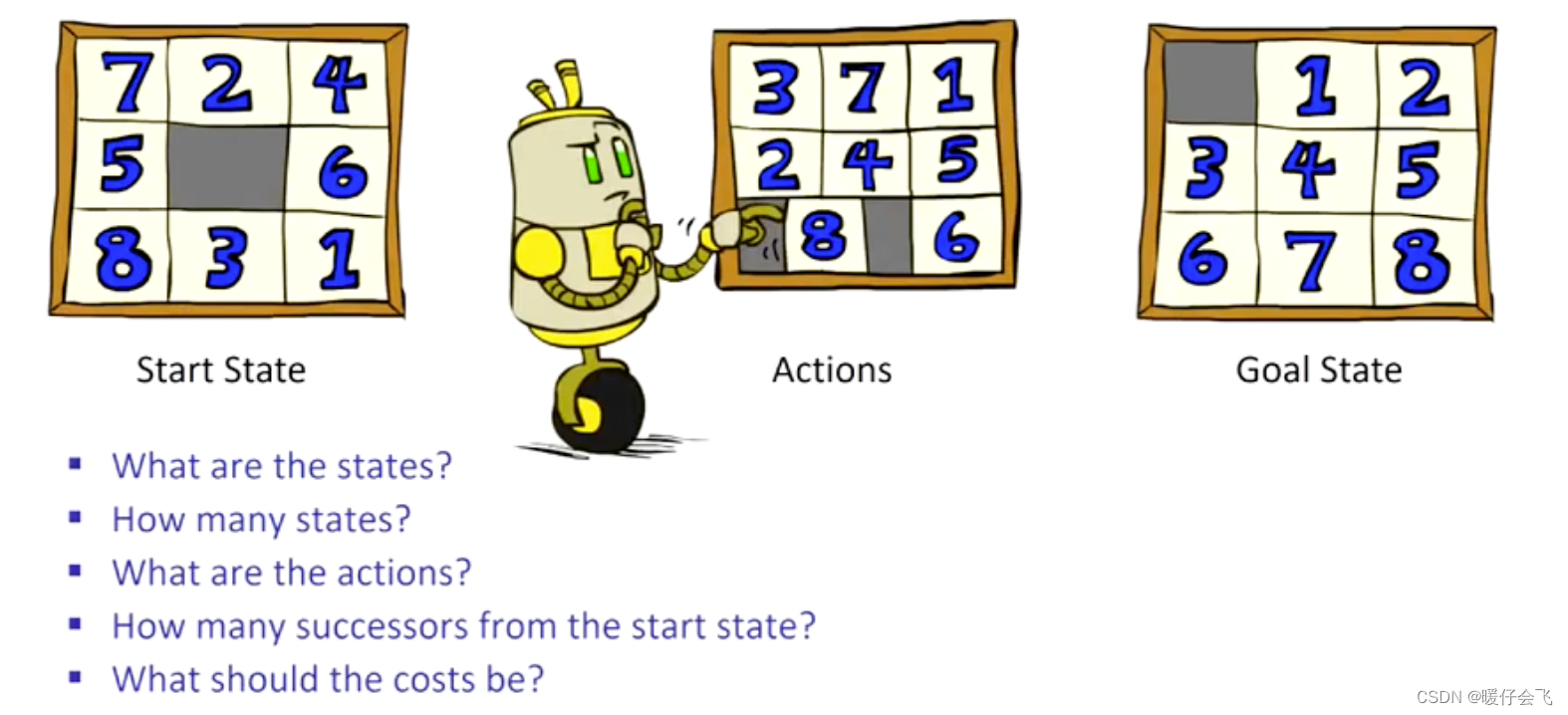
- state 数量: 9 ! 9! 9! 因为第一个块有 9 种选择,第二个有 8 种…
- actions:将 tile 移动到空白位置
- 起始状态有多少个后继:有 4 个 tile 可以移动到中间空白处,所以有 4 个 后继
- cost 如何设计:每次移动 tile 都是一个 cost
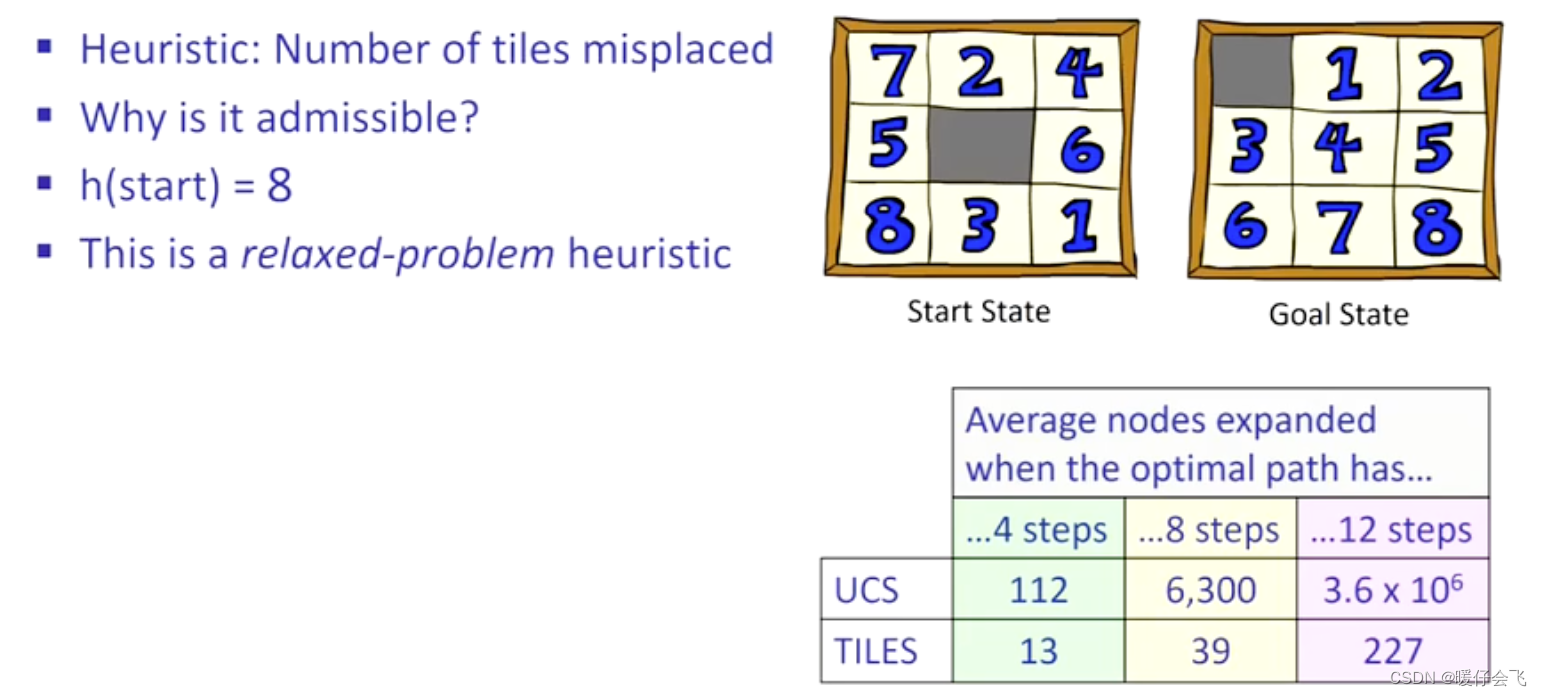
- 如何设计启发式函数:1)处于错误位置的 tiles
- 更加合理的启发式函数:2)当前时刻所有 tile 到最终状态的曼哈顿距离之和
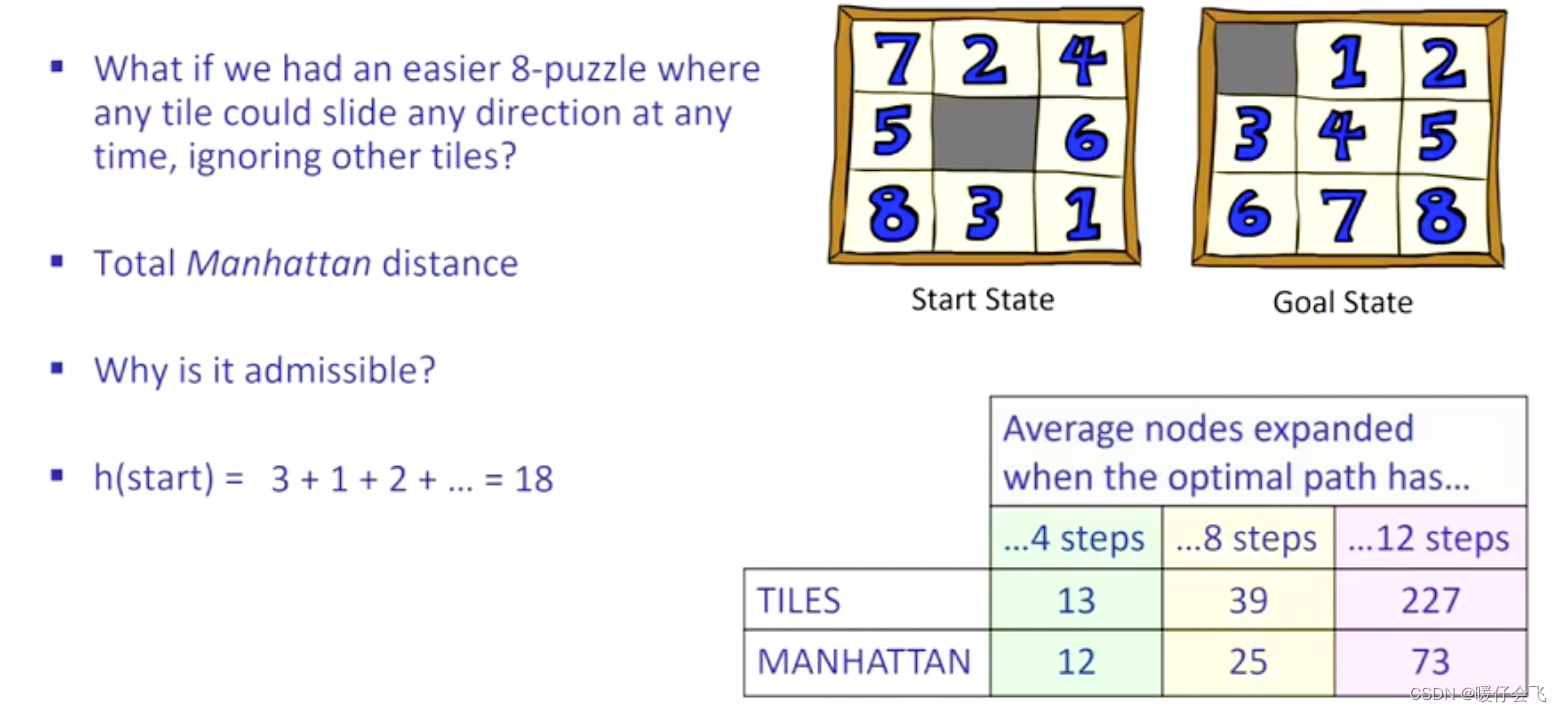

- 当然可以用实际距离来作为启发式函数的距离
- 因为在保证启发式是 admissible 的范围内,越接近真是的距离,越节省计算量
- 关键问题是我们无法得知真正的距离。。。。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











