







Achieving Super-Resolution Remote Sensing Images via the Wavelet Transform Combined With the Recursive Res-Net
论文地址
1、论文
通过小波变换结合递归res-net实现超分辨率遥感图像-----2019年
摘要
深度学习 (DL) 已成功应用于单图像超分辨率 (SISR),旨在从低分辨率 (LR) 图像重建高分辨率 (HR) 图像。与大多数当前在空间域执行重建的基于 DL 的方法不同,我们使用基于频域的方案来重建各个频段的 HR 图像。此外,我们提出了一种结合小波变换 (WT) 和递归 Res-Net 的方法。将 WT 应用于 LR 图像以将其划分为各种频率分量。然后,使用精心设计的具有递归残差块的网络来预测高频分量。最后通过逆WT得到重建图像。
本文有三个主要贡献:
1)在DL框架下提出了一种基于频域的SISR方案,以充分发挥在不同频段描绘图像的潜力;
2)采用全局和局部方式的递归块和残差学习来简化深度网络的训练,并去除批量归一化层以增加网络的灵活性,节省内存,提高速度;
3)将低频小波分量替换为具有更多细节的LR图像,以进一步提高性能。
为了验证所提出方法的有效性,使用 NWPU-RESISC45 数据集进行了大量实验,结果表明所提出的方法在客观评价和主观视角方面优于几种最先进的方法。
索引术语——递归网络、遥感图像、残差学习、超分辨率、小波变换(WT)。
I. 引言
单图像超分辨率(SISR)旨在恢复单个高分辨率(HR)图像,给定其低分辨率(LR)对应物[1]-[3]。由于需要包含高频信息的HR图像,因此超分辨率广泛用于许多应用,例如医疗。成像 [4]、卫星成像 [5] 以及安全和监视 [6],其中非常需要高频细节。SISR 是一个不适定的问题,因为需要预测的 HR 像素多于相应的像素左图。
这个问题通常通过使用某种先验信息来限制解决方案空间来缓解。为了利用附加信息,最近的方法采用了基于示例的策略 [7],该策略要么探索示例 [8]、[9] 的自相似性,要么使用外部样本将 LR 对应物映射到 HR 补丁[10]-[12]。假设图像可以在设计良好的字典下稀疏表示的稀疏先验是一种有效的先验,并且已经普遍应用于基于稀疏编码的方法[13],[14]。
随着深度学习的快速发展(DL)理论近年来,深度卷积神经网络(CNNs)被广泛用于解决遥感领域的各种任务;例子包括遥感图像的场景分类[15]、高光谱图像中的目标检测[16]、遥感图像的描述[17]和多光谱图像的变化检测[18]。基于 DL 的方法由于其强大的学习能力也被用于解决 SR 的不适定逆问题,并且明显提高了非基于 DL 的 SR 方法的性能 [19]-[23]。 Dong 等人提出的开创性 SRCNN 方法。 [24] 使用 CNN 来预测 LR 和 HR 图像对之间的非线性映射,并且明显优于非基于 DL 的 SR 方法。施等。 [25] 提出了一种高效的亚像素 CNN (ESPCN),它可以通过将 LR 图像作为输入并重新排列特征映射以获得 HR 图像而不是将 LR 图像的插值版本作为网络的输入来减少运行时间.董等。 [26] 提出了一种紧凑的沙漏形网络结构来加速 SRCNN。受在 ImageNet [28] 上训练的非常深的网络 [27] 的成功启发,例如 Res-Net,Kim 等人。 [29] 引入了一个非常深的超分辨率网络(VDSR),并使用具有不同放大因子的多个 HR 和 LR 图像对作为训练数据,以减少计算负担并加速训练收敛。金等人。 [30] 通过添加更多卷积层来增强感受野,并引入循环神经网络 (DRCN) 以避免在增加网络深度时引入新参数。泰等人。 [31] 提出了深度递归残差网络(DRRN),它通过应用残差学习来争取深度而简洁的网络。
关于遥感图像的超分辨率,Haut 等。 [32] 使用生成模型来学习图像的分布,并提出了一种无监督的 SISR 方法。在[33]中结合了局部和全局残差学习来重建监督遥感图像。超分辨率重建还可以帮助高光谱图像的分类 [34]。大多数当前基于 DL 的 SISR 方法在空间域中执行重建,并致力于学习 LR 像素与其在 HR 图像中的对应像素之间的关系以提高分辨率.
尽管在频域中恢复丢失的高频信息似乎更直接,但这种技术在基于 DL 的 SISR 方法中被忽略了。由于其提取细节和执行多分辨率分析的能力,小波变换 (WT)通常用于信号处理[35]-[37]。此外,WT 具有在不同级别描述图像的上下文和文本信息的能力,并且已被证明是用于表示和存储多分辨率图像的高效且高度直观的工具 [38]。关于WT在遥感中的应用有很多研究;例如,一种用于压缩遥感图像的面向二维的 WT 方法 [39],一种用于使用有限角度层析成像进行对象重建的自适应小波-Galerkin 方法 [40],一种利用 WT 作为特征提取器的土地覆盖分类方法[41],以及一种基于 WT 和神经网络相结合的图像分类方法 [42]。除了在遥感领域的各种应用外,WT 还被广泛用于提高遥感图像的空间分辨率[43]-[46]。 WT 和插值算法相结合用于遥感图像的超分辨率[47]。李等。 [48]在小波域重建红外图像序列,实现了空间分辨率的显着提高。尽管 WT 已被证明是传统超分辨率方法的有效工具,但据我们所知,很少有研究将 WT 结合到深度 CNN 中,由于它们各自的优点,有望进一步提高重建精度优点。
在本文中,我们提出了一种通过WT结合递归Res-Net(WTCRR)的三步遥感图像超分辨率方法。
首先,使用单级二维离散小波变换(DWT)将 LR 图像分解为 LR 小波分量的四个子带,并将低频子带替换为 LR 图像。四个子带的组合被馈入以下设计的网络。
然后,应用使用递归残差学习的新型深度网络来预测 HR 小波分量的四个相应子带的残差。
最后,使用逆 2D-DWT 获得重建的 HR 图像。
本文的其余部分组织如下。
在第二节中,我们简要介绍了 WT 的原理。
第三节详细介绍了所提出的方法。
实验设置在第四节中进行了描述,
第五节提供了定量和定性结果,以及关于所提出方法的讨论。
结论在第六节得出。
二、背景
本节简要介绍WT的理论,以及传统基于DWT的SISR方法的原理
A.小波变换的简要说明
WT通过按分辨率递增的层次结构分解信号来保留时间和频率信息[49]。
一维连续WT(1D-CWT)的信号 x © 定义为
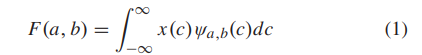
其中 ψa,b© 是母小波的扩展和平移版本,可以计算为
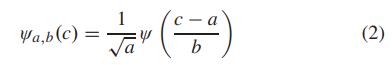
其中a和b是控制小波扩展和平移的参数。在处理离散信号时,使用的是DWT而不是CWT[50]。 离散信号x[d]的一维DWT定义为
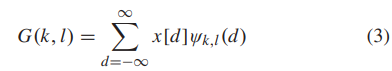
其中,ψk,l(d)是母小波ψ的扩展和平移版本,可以计算为
)
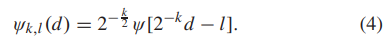
在实践中,DWT是使用滤波器组的方法实现的,其中输入信号经过低通滤波器L(e)和高通滤波器H(e)处理,然后缩小一半,以确定其近似和详细分量[51]。对于Haar小波,L(e)和H(e)定义为
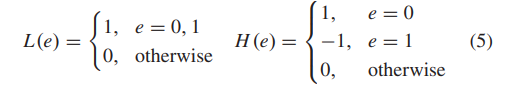
对于一个二维图像I,I(x,y)表示位于第x行和第y列的像素值。
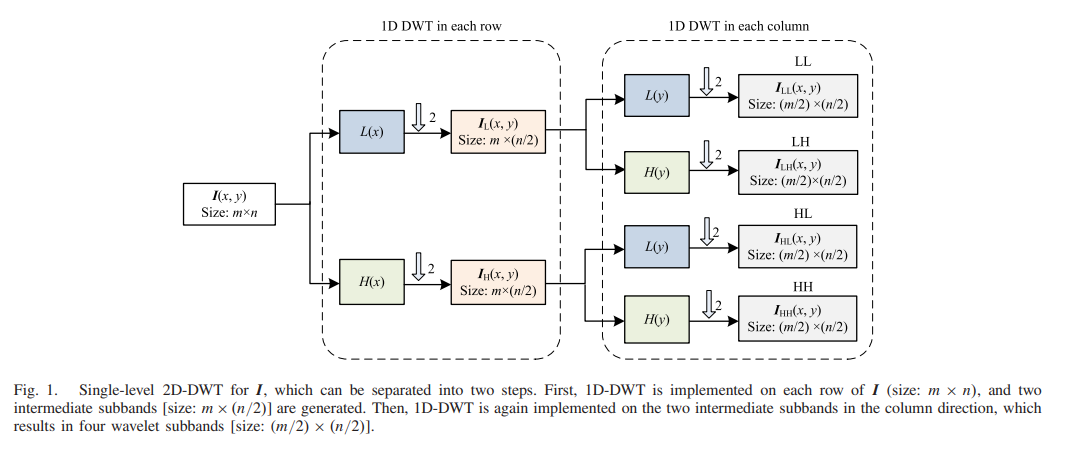
二维离散小波变换(2D-DWT)分别在每个维度上应用,
也就是说,一维离散小波变换在行和列方向上依次实现。
2D-DWT将I分解为四个子带,分别表示I的平均、垂直、水平和对角分量,并分别写为LL、LR、HL和HH。图1说明了对I进行单层2D-DWT的过程,其结果为四个子带。
B. SR Based on the DWT
基于 DWTInterpolation 的 SR 方法
在有效重建细节方面的能力有限。生成的结果是模糊的,因为在 SR 期间高频域中的信息没有很好地恢复。必须保留边缘以提高超分辨率图像的质量。
DWT 由于能够保留图像的高频分量而被采用。使用 DWT,图像被分解为低频分量的 LL 部分和高频分量的 LH、HL 和 HH 部分,这些部分也提供结构信息。传统的基于 DWT 的 SR 方法将 DWT 与非DL SR 方法。设IG表示大小为m×n的ground-truth HR图像,IL表示大小为(m/s)×(n/s)的LR图像,其中s是比例因子。 ILR 表示通过双三次插值获得的大小为 m×n 的 IL 的放大结果,令 IHR 表示大小为 m×n 的重建 HR 图像。图2显示了基于DWT的非DL SR方法的流程图,它包括三个步骤:
1)IL被2D-DWT分解为四个子带,即LL,HL,LH和HH;
2)将某种非DL SR方法应用于四个子带中的每一个,以将它们的空间分辨率提高s倍;
3)重建的HR图像IHR是通过逆离散小波变换(IDWT)得到的。

III. METHODOLOGY
如果能够准确预测相应的小波分量,那么可以从低分辨率图像恢复出具有丰富纹理细节和全局拓扑信息的高质量 HR 图像。因此,重建 HR 图像的过程可以转化为预测其小波分量的过程。然而,由于 CNN 模型具有强大的特征提取和表示能力,在 SR 方面已经取得了巨大的成功。以上两个事实促使我们将 WT 引入到基于 CNN 的 SR 方案中,并提出了 WT 结合递归 Res-Net(WTCRR)。WTCRR 的整个架构如图3所示,可分为分解部分、预测部分和重构部分,分别在第III-A至III-C节中详细说明。
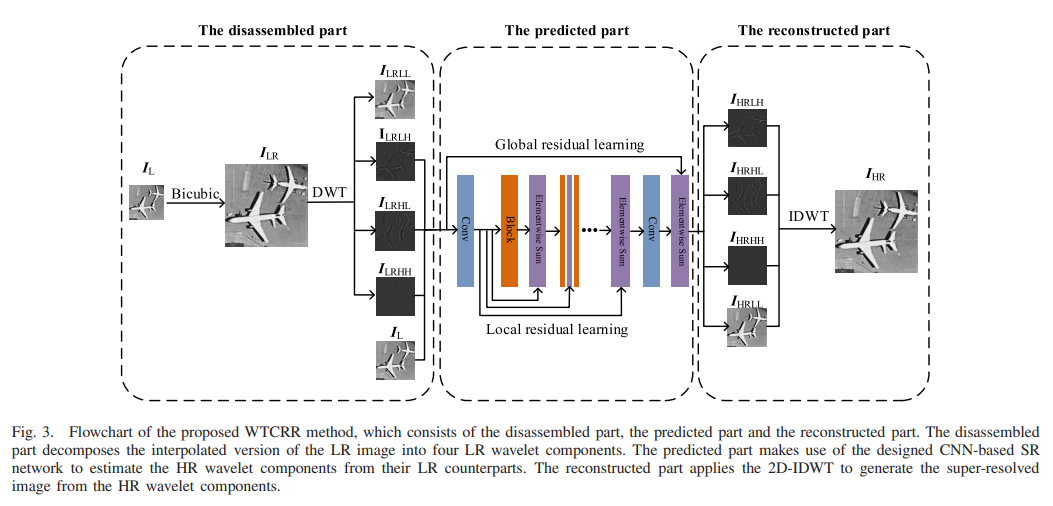
A. 分解部分
在分解部分中,将 LR 图像 IL 进行插值处理以获得 ILR,然后使用 Haar小波[52]对 ILR 进行分解,得到 ILRLL、ILRLH、ILRHL 和 ILRHH。与图2中的方案不同的是,由于 ILRLL 包含的信息比 IL 少,因此将低频部分 ILRLL 替换为 LR 图像 IL 作为网络输入,这可以进一步提高超分辨率图像的质量。总之,分解部分包括以下步骤:
1)使用缩放因子为×s的双三次插值对 IL 进行放大,以获得 ILR。
2)使用单级2D-DWT将 ILR 分解为 ILRLL、ILRLH、ILRHL 和 ILRHH。
3)将 IL、ILRLH、ILRHL 和 ILRHH 输入到设计好的递归 Res-Net 中。
B. 预测部分
在预测部分中,使用图4©所示的设计好的递归 Res-Net,从其 LR 对应物预测出 HR 图像的小波分量,分别为 IHRLL、IHRLH、IHRHL 和 IHRHH。为了比较,图4(a)和(b)展示了 VDSR 和 DRCN 的结构,为了更好地展示,省略了激活层。
在图4中,颜色相同的层属于相同类型。

我们主要从以下三个方面描述设计好的递归 Res-Net。
1)通道数:许多基于学习的SR方法仅处理亮度通道,因为人眼对亮度信息更为敏感,因此导致网络的输入和输出通道只有一个,如图4(a)和(b)所示。一些基于DL的SR方法的网络直接处理RGB图像,因此具有三个输入和输出通道。在所提出的方法中,输入为四个LR小波分量ILRLL、ILRLH、ILRHL、ILRHH,输出为相应的HR小波分量IHRLL、IHRLH、IHRHL、IHRHH;因此,所提出的网络具有四个输入和输出通道,如图4©所示。除了输入和输出层,所有其他层都具有64个通道。
2)残差学习:残差学习最初是为目标检测和分类等任务提出的,并且在从低级到低级的计算机视觉问题中表现出优异的性能。高层次的任务。他等人。 [27] 提出了一个名为 Res-Net 的网络,其中残差学习引入来解决物体识别问题。
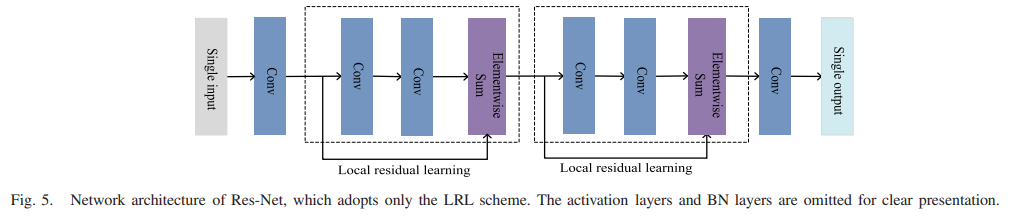
如图 5 所示,Res-Net 利用局部残差学习 (LRL) 来减轻训练深度网络的难度,综合经验证据表明,残差网络更容易优化,并且可以从相当大的角度获得准确性增加的深度。如图4(a)所示,VDSR [29]使用全局残差学习(GRL),即只需要估计HR图像和LR图像的插值版本之间的残差,这对于降低训练深度网络的难度。与 GRL 不同的是,LRL 是每隔几个堆叠层执行一次。 LRL 和 GRL 在所提出的网络中均采用,以充分利用各自的优势。残差学习结构包含两条路径:有助于学习高度复杂特征的残差路径和有助于梯度反向传播的恒等路径。与 Res-Net 中的残差单元相反,Res-Net 中的残差单元使用链式结构,不同块的身份分支具有不同的输入,如图 5 的虚线框所示。如图 4© 所示,多路径这里采用结构,以便所有残差单元共享相同的识别分支输入,这可以促进学习[53]并缓解链式结构的过度拟合问题。
3)递归块:为SR提出了DRRN [31],其中引入了递归块以避免引入新参数,同时通过在各个块之间共享权重来增加网络的深度。 DRRN 中递归块的架构如图 6(a) 所示,它由两个批量归一化 (BN) 层、两个整流线性单元 (ReLU) 层 [54] 和两个卷积层组成。
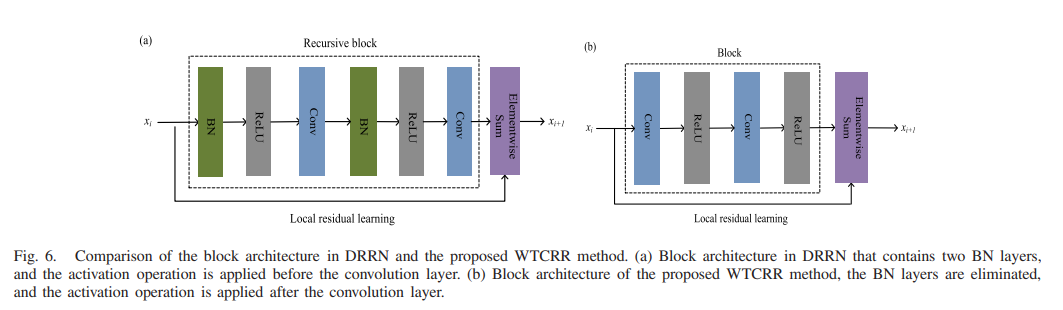
我们观察到块中的 BN 层不仅增加了网络复杂度,而且增加了计算负担。 BN 层需要与后续卷积层相同数量的内存,并将对特征进行归一化并消除网络的范围灵活性。基于上述分析,我们从递归块中删除了 BN 层。除了这个修改之外,ReLU 操作在卷积层之后(而不是之前)应用。修改后的块的结构如图 6(b)所示,在所提出的方法中递归地采用了九个这样的块。
4)所提出的递归 Res-Network 的总结:所提出的递归 Res-Net 的主要特征Net 可以总结如下。
1) 深度:一般来说,网络越深,其性能越好。所提出的递归 Res-Net 有 20 个卷积层,并且。因此,具有较大的感受野和有效的非线性映射能力。
2)递归:递归学习可以在增加网络深度时限制模型参数的数量。
3)残差:全局和局部方式都采用残差学习,可以减轻训练难度very deep networks.
4) Suitable:根据本文的具体要求,修改输入层和输出层的通道数,以适合与WT.C结合。
C. Reconstructed Part
在重建部分中,将四个重构的小波分量IHRLL、IHRLH、IHRHL和IHRHH合并,通过二维反小波变换(2D-IDWT)生成重构的高分辨率图像IHR。
四、实验
在本节中,我们将描述实验中使用的数据集,给出网络训练的实施细节,并提出四个质量评估指标来量化评估 SR 方法的性能。
A.数据集
NWPU-RESISC45 [55]是一个包含45个类别的场景分类数据集,每个类别有700张图像,每张图像大小为256×256像素。本文选取700幅飞机图像作为实验数据,将这些图像分为500幅图像的训练集、100幅图像的验证集和100幅图像的测试集。验证集用于确定何时停止训练以减轻过度拟合。为了充分利用训练数据,我们以两种方式扩充训练集中的图像。1)缩放:对训练集中的每个图像进行下采样using scale factors of 0.6, 0.7, 0.8, and 0.9.2) Rotation:将训练集中的每张图像分别旋转90°、180°和270°。与VDSR中使用的策略类似,scale augmentation也是用于训练所提出的模型,即训练集中包含各种比例因子(×2,×3,×4)的 HR 和 LR 图像对,这使我们可以仅使用一个来测试各种比例因子的 SR 方法模型.
B.训练细节
最重要的是,为了清楚起见,我们给出了相关符号的定义。令 Xi 表示第 i 个真值 HR 图像,xi−LL,xi−LH,xi−HL,xi−HH 表示 Xi 的小波分量的向量版本,xi = [xTi−L L , xTi−L H , xTi−H L , xTi−H H ]T 表示这些分量的串联。类似地,让 Hi 表示第 i 个重建的 HR 图像,hi-LL,hi-LH,hi-HL,hi-HH 表示小波分量的矢量版本
H,andh^=hT ,hT ,hT ,hT T 表示 i i i−LL i−LH i−HL i−HH 这些分量的级联。我们使用九个递归块,每个块有两个卷积层。加上残差块外的两个卷积层,提出的网络中总共有 20 个卷积层。卷积层的内核大小为 3 × 3,导致最后一个卷积层中像素的感受野为 41 × 41。因此,训练图像被分成 41×41 个块,步幅为 21。每个卷积层使用零填充,使特征图的宽度和高度保持不变。第一个卷积层包含64个大小为4×3×3的过滤器,最后一个卷积层包含四个大小为64×3×3的过滤器,其他层包含64个大小为64×3×3的过滤器.
SISR旨在学习LR图像Y和HR图像X之间的映射函数X=gw(Y),其中W代表网络的参数。
SISR aims at learning a mapping function X = gW(Y) between the LR image Y and the HR image X, where W represents the parameter of the network.
与其他基于 DL 的 SR 方法不同,后者计算真实 HR 图像和重建 HR 图像之间的平方欧几里得距离作为损失,
我们计算真实 HR 图像之间小波分量的 l2 损失以及重建的 HR 图像如下:
在这里插入图片描述
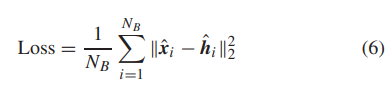
其中 NB 表示批量大小。
所提出方法的总体 object函数定义为
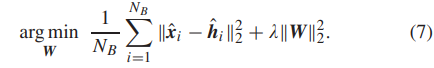
第一个项是保真度项,用于确保重建的高分辨率小波分量与真实高分辨率分量相似。第二个项是正则化项,有助于避免过拟合,并使用系数λ来平衡目标函数中的这两个项。使用Adam算法[56]来优化网络。参数W使用随机高斯分布进行初始化。学习率从0.01开始,每10个epoch减半。训练过程在Caffe框架[57]中进行,使用8 GB NIVIDIA GTX1080加速,测试过程在拥有32 GB内存的MATLAB 2016a中实现。使用一个GTX1080训练所需的时间约为7天。我们注意到,我们的方法比SRCNN [24]、VDSR [29]和DRCN [30]花费更多的训练时间。原因是我们设计的网络比上述方法中应用的网络更为复杂。然而,所提出的方法可以实现比比较方法更好的性能。
C. Quantitative Evaluation Indices
1、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR):峰值信噪比是一种基于均方误差(Mean Square Error,MSE)的图像质量评估指标,用于评估重建的高分辨率图像H和参考高分辨率图像之间的差异,可以表示为:
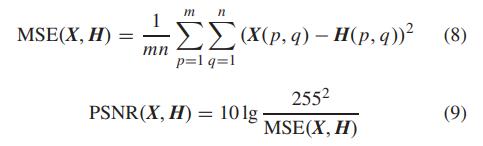
其中,m和n分别为图像的宽度和高度。PSNR值越大,表示图像质量越好。
2、结构相似性指数(Structure Similarity Index,SSIM):结构相似性指数用于评估重建的高分辨率图像H与真实高分辨率图像之间的结构相似性,可以计算为:
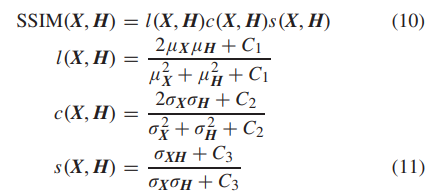
其中,μX和μH分别表示X和H的均值,σX和σH分别表示X和H的标准差,σXH表示X和H的协方差,C1、C2和C3为常量。SSIM值越高,表示图像质量越好。
3)归一化均方根误差:[32]中使用的归一化根MSE(NRMSE)可以计算如下,NRMSE的值越小,重建的HR图像质量越好√MSE(X,H)NRMSE(X,H) = 255。(12)
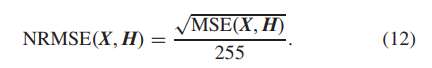
4)综合相对全球维度错误:提出ERGAS [59]通过考虑比例因子来衡量重构HR图像的质量,可以表述为:
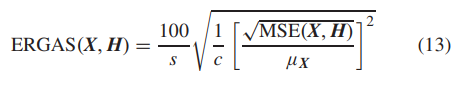
其中s表示比例因子,c表示图像的通道数,μX为X的均值。ERGAS的值越小,重建的HR图像质量越好。
五、结果
A 与最先进方法的比较
所提出的 WTCRR 方法与用作基线的双三次插值以及几种最先进的方法进行了比较,包括 SRCNN [24]、ESPCN [25]、 FSRCNN [26]、VDSR [29] 和 DRRN [31]。与 SRCNN [24] 一样,边界中的像素在评估重建 HR 图像的质量之前被裁剪。由于页面有限,我们只展示了四幅图像的重建结果,以及 PSNR、SSIM、NRMSE 和 ERGAS 值表 I-IV 中列出了具有 ×2、×3 和 ×4 的四张选定图像。这些表中还给出了整个测试集上重建结果的四个定量评价指标的平均值。
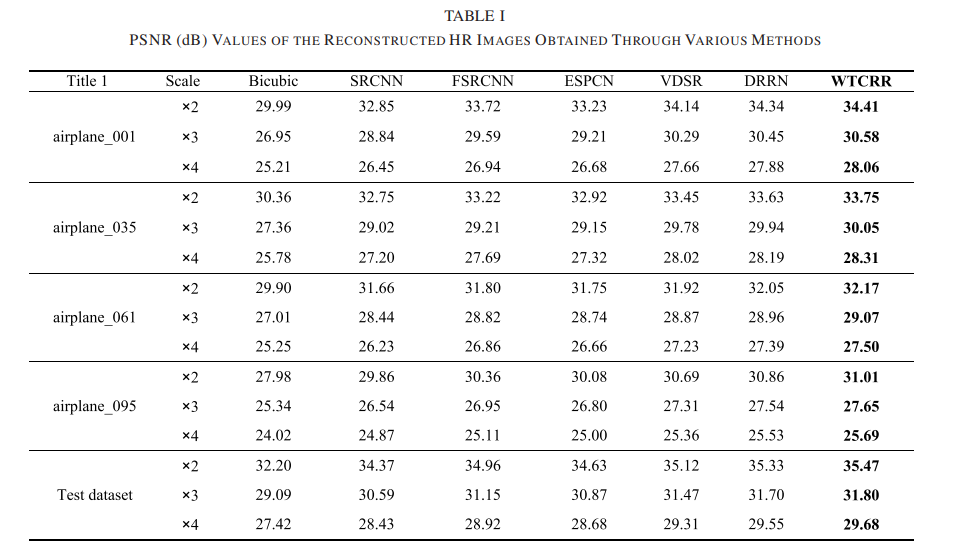
从结果可以看出,所提出的 WTCRR 方法在四个质量评价指标方面在所有尺度上都优于其他方法。在 ×2、×3 和 ×4 的比例因子下,WTCRR 在 PSNR 中将次优方法提高了 0.14、0.10 和 0.13 dB,在 SSIM 中提高了 0.0089、0.0147 和 0.0128,在 NRMSE 中提高了 0.0003、0.0003 和 0.0005,以及 ERGAS 中的 0.0446、0.0657 和 0.0221。值得指出的是,在上述结果中,DRRN 方法使用了 25 个残差块,而 WTCRR 方法仅使用了 9 个。然而,由于块和卷积层更少,WTCRR 仍然优于 DRRN。所提出的 WTCRR 方法可以通过使用更多的残差块来获得更好的结果。除了定量评估外,还对所提出的方法与其他方法进行了视觉比较。比例因子为×2、×3、×4的各种方法重建的HR结果如图1和图2所示。 7-9,并提供地面实况 HR 图像以供参考。为了更清晰的比较,在相应图像下方显示了绿色矩形标记区域的特写。“airplane_001.jpg”通过各种方法获得的重建 HR 图像的比较,放大倍数为 ×2。

图 7. 可观察
WTCRR 方法准确地重建了直线,并获得了比其他方法更清晰、更锐利的结果。 WTCRR重建的边缘是通过比较方法获得的边缘中最清晰的。图。
图8比较了通过各种方法获得的“air-plane_095.jpg”的重建HR图像,比例因子为×3,特写位于飞机的机翼。很明显,与通过所提出的 WTCRR 方法获得的重建 HR 图像中的飞机机翼边缘相比,通过其他方法获得的重建 HR 图像中的边缘更模糊或更失真。所提出的 WTCRR 方法产生了更令人信服的结果和更少的伪影,同时重建了比比较的最先进方法更多的增强边缘。
在图 9 中,我们比较了获得的“airplane_035.jpg”的重建 HR 图像通过各种方法,比例因子为 ×4。通过比较飞机尾部区域的放大部分可以看出,所提出的WTCRR方法重建的尾部清晰生动,最接近地面真值HR图像,而其他方法获得的尾部方法要么模糊要么扭曲。图。
图 10 展示了通过各种方法获得的“airplane_061.jpg”的重建 HR 图像,比例因子为 ×4。所提出的 WTCRR 方法在四个图像质量评价指标方面取得了比较方法中最好的结果。然而,通过 WTCRR 获得的重建 HR 图像仍然丢失了一些细节信息;例如,该方法未能重建左上角的斜线。
B. Discussion
1、With or Without BN layers:
为了评估去除 BN 层的效果,我们在测试集下比较了通过具有和不具有 BN 层的网络获得的重建 HR 图像的 PSNR 值,比例因子为 ×2,并且绘制出图 11 中两种情况下平均 PSNR 值随迭代次数增加的趋势。标有“+”的蓝色点和标有“◦”的红色点对应于通过
分别是没有和有 BN 层的网络。
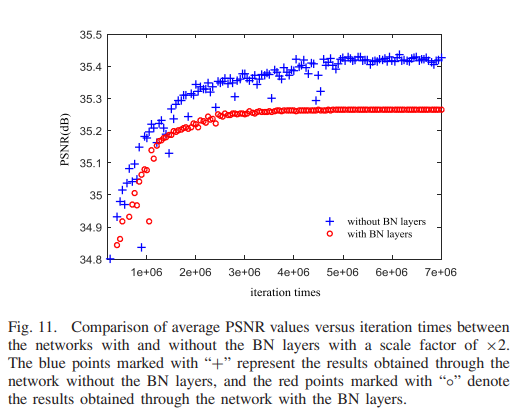
结果表明,没有 BN 层的网络比有 BN 层的网络具有更好的性能,并且通过去除 BN 层可以实现大约 0.18 dB 的改进。 图。
图 12 比较了通过具有和不具有 BN 层的网络获得的“airplane_039.jpg”的重建 HR 图像。从尾翼特写可以看出,有BN层的网络重建图像的边缘比没有BN层的网络重建图像的边缘更模糊,这验证了去除BN层可以实现更有说服力的视觉效果。此外,与使用 BN 层的情况相比,没有 BN 层的网络在训练网络时节省了大约 40% 的 GPU 内存使用量。
2)使用 ILRLL 或 IL:
我们用 IL 代替 ILRLL 作为低频分量并将 IL 馈送到以下网络中。
为了证明该方案的有效性,在图 13 中比较了以 IL 和 ILRLL 作为输入的方法在比例因子为 ×3 的测试集下的 PSNR 结果。在图 13 中,PSNR 值的趋势为绘制了两种情况下的迭代,蓝色“+”点和红色“◦”点分别对应IL和ILRLL作为输入的情况。从结果中可以看出,与使用 ILRLL 作为输入的情况相比,以 IL 作为低频输入的设计网络提高了 PSNR 值,提高了大约 0.1 dB。图 14 显示了通过以 IL 和 ILRLL 作为输入的方法获得的“airplane_073.jpg”的重建 HR 图像。比例因子为×3,提供机翼特写。
可以看出,图 14(b)中的图像
以IL为输入得到的图像,比以ILRLL为输入得到的图14(a)的图像更准确地重建了直线,边缘更清晰锐利。3)其他类型图像的结果:为了进一步为了验证所提出方法的有效性,所提出的 WTCRR 方法使用另一个数据集进行了测试,以证明其对自然图像的适用性。我们选择[60]中使用的291张图像作为训练数据,并在[61]的BSD100数据集下进行测试。图 15 显示了比例因子为 ×4 的“148026.jpg”通过各种方法获得的重建 HR 图像的比较。通过比较通过各种方法获得的重建 HR 图像的特写镜头,可以观察到除了提出的 WTCRR 方法外,其他方法都无法恢复水平条带和阴影中的反射光,这些细节都被WTCRR很好地重建了。通常,很容易收集比遥感图像具有更高分辨率且包含更详细信息的自然图像数据集。通过添加自然图像数据集作为训练数据,可以提高所提出的WTCRR方法的性能。然而,由于两种类型的图像的数据分布不同,使用自然图像数据集训练的模型直接应用于遥感图像可能不起作用。迁移学习是这个问题的潜在解决方案,将在未来的工作中研究。
VI. 结论
本文提出一种基于WTCRR的遥感影像超分辨方法。通过将WT和精心设计的深度神经网络相结合,实现了遥感图像超分辨率的最先进性能,并在广泛使用的遥感数据集下通过几组经验进行了验证。尽管WTCRR方法性能良好,但在重建过程中仍然会丢失一些详细信息。在未来的工作中,将应用其他技术,例如迁移学习技术,该技术可用于从包含非常高分辨率图像的自然图像数据集中借用高频信息,以进一步提高所提方法的性能。















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









