







kafka安装及基础使用
zookeeper 简介
服务注册管理中心,ZooKeeper是一个用于维护配置信息、命名、提供分布式同步和提供组服务的集中式服务。分布式应用程序以某种形式使用所有这些类型的服务。每次实现它们时,都要做大量的工作来修复不可避免的错误和竞争条件。由于实现这类服务的困难,应用程序最初通常会对它们吝啬,这使得它们在发生变化时变得脆弱,难以管理。即使操作正确,在部署应用程序时,这些服务的不同实现也会导致管理的复杂性。
zookeeper 安装
配置 java 环境:
zookeeper依赖与Java环境,建议使用Java 1.8
java环境高版本与低版本可能会不兼容,在安装kafka和zookeeper时最好参考官网建议的java 版本

但根据版本不通使用得jdk版本也不一样,我这里使用得是zookeeper 3.4.6
java环境这里就不在赘述了,不会的自行百度
单机部署 ZooKeeper
https://archive.apache.org/dist/zookeeper/#官网下载地址
将安装包下载后上传到服务器

安装步骤:
1,解压
[root@localhost opt]# tar -zxvf zookeeper-3.4.6.tar.gz
2,修改配置文件
进入conf 文件,将实例文件复制一份,修改名称为zoo.cfg
[root@localhost opt]# cd zookeeper-3.4.6/conf/
[root@localhost conf]# cp -a zoo_sample.cfg zoo.cfg
2,解压后进入zookeeper的bin目录
[root@localhost opt]# cd zookeeper-3.4.6/bin/
3,启动
[root@localhost bin]# ./zkServer.sh start
4,配置文件详解
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中 leader 服务器与 follower 服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 # leader 与 follower 之间连接完成之后,后期检测发送和应答的心跳次数,如果该 follower 在设置的时间内(5*2000)不能与 leader 进行通信,那么此follower 将被视为不可用。
dataDir=/usr/local/zookeeper/data #该属性对应的目录是用来存放myid、 version(数据信息)、pid(服务器允许时候ID)等。 其中myid是需要人工创建的,并设置一个整数值。集群中的任何一台服务器都是唯一的。
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
maxClientCnxns=128#单个客户端 IP 可以和 zookeeper 保持的连接数
autopurge.snapRetainCount=3#3.4.0 中的新增功能:启用后,ZooKeeper 自动清除功能会将 autopurge.snapRetainCount 最新快照和相应的事务日志分别保留在dataDir 和 dataLogDir 中,并删除其余部分,默认值为 3。最小值为 3。
autopurge.purgeInterval=1 #3.4.0 及之后版本,ZK 提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个 1 或更大的整数,默认是 0,表示不开启自动清理功能
5,在bin目录下启动服务 单机情况下可不必修改配置文件保持默认即可
[root@localhost bin]# ./zkServer.sh start
6,验证zookeeper服务
[root@localhost bin]# ./zkServer.sh status
JMX enabled by default
Using config: /opt/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: standalone
至此单机部署完成
集群部署zookeeper
环境介绍
| ip | 角色 |
|---|---|
| 192.168.144.3 | master |
| 192.168.144.13 | slave |
| 192.168.144.23 | slave |
zookeeper 集群介绍
ZooKeeper 集群用于解决单点和单机性能及数据高可用等问题。需要注意,集群环境主机数必须是单数
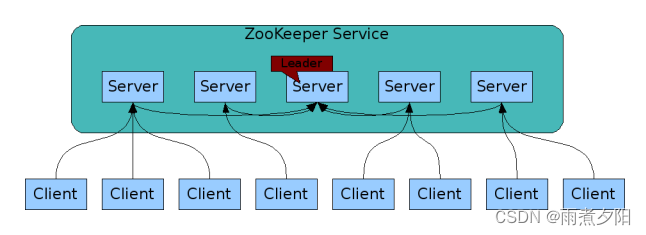
上图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
集群角色介绍
| 角色 | 主要工作描述 | |
|---|---|---|
| 领导者 | 1,事务请求的唯一调度和处理者,保证集群事务处理的顺序性。 2,集群内部各服务器的调度者 | |
| 学习者 | 跟随者 | 1,处理客户端非事务请求,转发事务请求给Leader服务器, 2,参与事务请求proposal的投票。 3,参与leader选举的投票 |
| 观察者 | Follower和 Observer 唯一的区别在于Observer 机器不参与Leader的选举过程,也不参与写操作的“过半写成功策略,因此observer 机器可以在不影响写性能的情况下提升集群的读性能 | |
| 客户端(client) | 请求发起方 | |
集群部署
1,将安装包上传到服务器,并进行解压关闭防火墙
[root@localhost opt]# tar -zxvf zookeeper-3.4.6.tar.gz
[root@localhost opt]# systemctl disable --now firewalld.service
2,修改配置文件
进入conf 文件,将实例文件复制一份,修改名称为zoo.cfg
[root@localhost opt]# cd zookeeper-3.4.6/conf/
[root@localhost conf]# cp -a zoo_sample.cfg zoo.cfg
3,创建数据存储目录
[root@localhost ~]# mkdir -p /data/zookeeper
4,集群配置
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中 leader 服务器与 follower 服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 # leader 与 follower 之间连接完成之后,后期检测发送和应答的心跳次数,如果该 follower 在设置的时间内(5*2000)不能与 leader 进行通信,那么此follower 将被视为不可用。
dataDir=/usr/local/zookeeper/data #该属性对应的目录是用来存放myid、 version(数据信息)、pid(服务器允许时候ID)等。 其中myid是需要人工创建的,并设置一个整数值。集群中的任何一台服务器都是唯一的。
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
maxClientCnxns=128#单个客户端 IP 可以和 zookeeper 保持的连接数
autopurge.snapRetainCount=3#3.4.0 中的新增功能:启用后,ZooKeeper 自动清除功能会将 autopurge.snapRetainCount 最新快照和相应的事务日志分别保留在dataDir 和 dataLogDir 中,并删除其余部分,默认值为 3。最小值为 3。
autopurge.purgeInterval=1 #3.4.0 及之后版本,ZK 提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个 1 或更大的整数,默认是 0,表示不开启自动清理功能
server.1=192.168.144.3:2888:3888 # server.服务器编号=服务器 IP:LF 数据同步端口:LF 选举端口 需要注意的是,编号必须和myid文件中的id保持一致
server.2=192.168.144.13:2888:3888
server.3=192.168.144.23:2888:3888
#以上所有步骤,所有机器操作都相同#
5,配置当前机器在集群中的id
master节点:
[root@localhost conf]# echo "1">/data/zookeeper/myid
slave1节点:
[root@localhost conf]# echo "2">/data/zookeeper/myid
slave2节点:
[root@localhost conf]# echo "3">/data/zookeeper/myid
6,启动所有节点(需要尽快启动所有节点)
[root@localhost bin]# ./zkServer.sh start
zookeeper命令行工具
#进入zookeeper命令行
[root@localhost bin]# ./zkCli.sh -server 192.168.144.3:2181
查看指定节点子节点信息:ls 节点,比如查看根节点下子节点信息(新安装的Zookeeper根节点就一个zookeeper节点)。
[zk: 192.168.144.3:2181(CONNECTED) 3] ls /
[zookeeper]
[zk: 192.168.144.3:2181(CONNECTED) 4] ls /zookeeper
[quota]
[zk: 192.168.144.3:2181(CONNECTED) 5] ls /zookeeper/quota
[]
创建节点:create 父节点path/子节点 [子节点数据],父节点path不能为空,可以是/或其他path(默认情况下创建的是持久化的节点,既不是顺序也不是临时的)。
[zk: 192.168.144.3:2181(CONNECTED) 6] create /yaoxinyuan "www.xxx.com"
Created /yaoxinyuan
[zk: 192.168.144.3:2181(CONNECTED) 7] ls /
[yaoxinyuan, zookeeper]
[zk: 192.168.144.3:2181(CONNECTED) 8] ls /yaoxinyuan
[]
获取节点数据:get 节点path,如果节点没有信息,返回null。
[zk: 192.168.144.3:2181(CONNECTED) 9] get /yaoxinyuan
"www.xxx.com"
cZxid = 0x200000002
ctime = Thu Apr 20 11:50:46 CST 2023
mZxid = 0x200000002
mtime = Thu Apr 20 11:50:46 CST 2023
pZxid = 0x200000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0
修改节点数据:set 节点path 节点数据。
[zk: 192.168.144.3:2181(CONNECTED) 11] set /yaoxinyuan "heiehiehi"
cZxid = 0x200000002
ctime = Thu Apr 20 11:50:46 CST 2023
mZxid = 0x200000003
mtime = Thu Apr 20 11:59:46 CST 2023
pZxid = 0x200000002
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 0
[zk: 192.168.144.3:2181(CONNECTED) 12] get /yaoxinyuan
"heiehiehi"
cZxid = 0x200000002
ctime = Thu Apr 20 11:50:46 CST 2023
mZxid = 0x200000003
mtime = Thu Apr 20 11:59:46 CST 2023
pZxid = 0x200000002
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 0
删除节点:delete 节点path
[zk: 192.168.144.3:2181(CONNECTED) 14] delete /yaoxinyuan
[zk: 192.168.144.3:2181(CONNECTED) 15] ls /
[zookeeper
kafka简介
Kafka 被称为下一代分布式消息系统,由 scala 和 Java 编写,是非营利性组织
ASF(Apache Software Foundation,简称为 ASF)基金会中的一个开源项目,比如
HTTP Server、Hadoop、ActiveMQ、Tomcat 等开源软件都属于 Apache 基金会的开
源软件,类似的消息系统还有 RbbitMQ、ActiveMQ、ZeroMQ。
Kafka®用于构建实时数据管道和流应用程序。 它具有水平可伸缩性,容错性,
快速快速性,可在数千家公司中投入生产。
单机部署
下载地址:https://kafka.apache.org/downloads

根据需要下载合适的版本
上传安装包到服务器,并进行解压
[root@localhost opt]# tar -zxvf kafka-2.2.1-src.tgz
修改配置文件
listeners=PLAINTEXT://192.168.144.3:9092
advertised.listeners=PLAINTEXT://192.168.144.3:9092
zookeeper.connect=192.168.144.3:2181 #此处在部分kafka版本中必须使用主机名,
启动kafka(进入bin目录执行)
[root@localhost bin]# ./kafka-server-start.sh ../config/server.properties
后台启动kafka(进入bin目录执行)
./kafka-server-start.sh -daemon ../config/server.properties
集群部署
| ip | 角色 |
| 192.168.144.3 | master |
| 192.168.144.13 | slave |
| 192.168.144.23 | slave |
安装方式和上述单机部署方法一致,只是配置文件有些差异,此处就不在赘述安装部署步骤,单独对配置需要修改的进行描述
#节点1:
broker.id=1 每个 broker 在集群中的唯一标识,正整数。
listeners=PLAINTEXT://192.168.144.3:9092 #监听地址
log.dirs=/usr/local/kafka/kafka-logs #kakfa 用于保存数据的目录,所有的消息都会存储在该目录当中
num.partitions=1 #设置创新新的 topic 默认分区数量
log.retention.hours=168 #设置 kafka 中消息保留时间,默认为 168 小时即 7 天
zookeeper.connect=zookeeper.connect=zk1:2181,zk2:2181,zk3:2181 #指定连接的 zk 的地址,zk 中存储了 broker 的元数据信息,
zookeeper.connection.timeout.ms=6000 #设置连接 zookeeper 的超时时间,默认 6 秒钟
#节点2:
broker.id=2
listeners=PLAINTEXT://192.168.144.13:9092
log.dirs=/usr/local/kafka/kafka-logs
num.partitions=1
log.retention.hours=168
zookeeper.connect=zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zookeeper.connection.timeout.ms=6000
#节点3:
broker.id=3
listeners=PLAINTEXT://192.168.144.23:9092
log.dirs=/usr/local/kafka/kafka-logs
num.partitions=1
log.retention.hours=168
zookeeper.connect=zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zookeeper.connection.timeout.ms=6000
./kafka-server-start.sh -daemon ../config/server.properties
集群安装完成。
kafka常用命令
验证集群可以通过在一个节点创建topic,在另外节点查看topic列表
#创建topic
./kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --partitions 3 --replication-factor 3 --topic test
#查看topic
./kafka-topics.sh --describe --zookeeper zk1:2181,zk2:2181,zk3:2181 --topic test
#列出kafka中的所有topic
./kafka-topics.sh --list --zookeeper zk1:2181
#通过命令行写入消息
./kafka-console-producer.sh --broker-list 192.168.144.3:9092,192.168.144.13:9092,192.168.144.13:9092 --topic test
#通过命令行消费消息
./kafka-console-consumer.sh --topic test --bootstrap-server 192.168.144.3:9092,192.168.144.13:9092,192.168.144.13:9092 --from-beginning
#删除topic
/apps/kafka/bin/kafka-topics.sh --delete --zookeeper zk1:2181,zk2:2181,zk3:2181 --topic test

















 2192
2192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











