






论文名称:Mask R-CNN
论文下载地址:https://arxiv.org/abs/1703.06870
在阅读本篇博文之前需要掌握Faster R-CNN、FPN以及FCN相关知识。
Faster R-CNN视频讲解:FasterRCNN_哔哩哔哩_bilibili
FPN视频讲解:1.1.2 FPN结构详解_哔哩哔哩_bilibili
FCN视频讲解:FCN网络结构详解(语义分割)_哔哩哔哩_bilibili
Mask R-CNN视频讲解:Mask R-CNN网络详解_哔哩哔哩_bilibili
————————————————
版权声明:本文为太阳花的小绿豆原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本博客属于个人根据该博客和博主在b站的讲解以及自己理解写出的一些笔记和注释
原文链接:https://blog.csdn.net/qq_37541097/article/details/123754766
0 前言
Mask R-CNN是2017年发表的文章,一作是何恺明大神,没错就是那个男人,除此之外还有Faster R-CNN系列的大神Ross Girshick,可以说是强强联合。该论文也获得了ICCV 2017的最佳论文奖(Marr Prize)。并且该网络提出后,又霸榜了MS COCO的各项任务,包括目标检测、实例分割以及人体关键点检测任务。在看完这边文章后觉得Mask R-CNN的结构很简洁而且很灵活效果又很好(仅仅是在Faster R-CNN的基础上根据需求加入一些新的分支)。
注意,阅读本篇文章之前需要掌握Faster R-CNN、FPN以及FCN的相关知识,如果不了解可以参考我之前在哔哩哔哩上做的相关视频。
1 Mask R-CNN
The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition.
Mask R-CNN是在Faster R-CNN的基础上加了一个用于预测目标分割Mask的分支(即可预测目标的Bounding Boxes信息、类别信息以及分割Mask信息)。

Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework.
Mask R-CNN不仅能够同时进行目标检测与分割,还能很容易地扩展到其他任务,比如再同时预测人体关键点信息。

注:
1.Keypoint detection:关键点检测
2.segmentation masks predicted:预测分割掩码
3.ResNet-50-FPN 是一个深度神经网络模型的名称,它结合了几种现代神经网络设计的要素:
① **ResNet-50**: 这是一个经典的深度残差网络(Residual Network),由 Microsoft Research 提出。ResNet-50 是 ResNet 系列中的一个具体模型,具有 50 层深度,使用残差连接(residual connections)来解决深层神经网络训练中的梯度消失问题,使得能够训练更深的网络而不会出现退化问题。
② **FPN (Feature Pyramid Network)**: FPN 是由 Facebook AI 提出的一种用于目标检测和语义分割的特征金字塔网络。它通过构建自底向上的特征金字塔,从网络中间层获取高语义信息,从而解决了不同尺度物体检测的问题。FPN 可以在网络中不同层次的特征图之间建立连接,形成金字塔结构,使得网络可以同时关注多个尺度的特征。
综合起来,ResNet-50-FPN 就是将 ResNet-50 的架构与 FPN 的特征金字塔结构相结合的一个模型。这种结合使得 ResNet-50-FPN 在目标检测等任务中表现出色,能够有效处理不同尺度和大小的目标物体,同时保持高效的特征提取和利用能力。
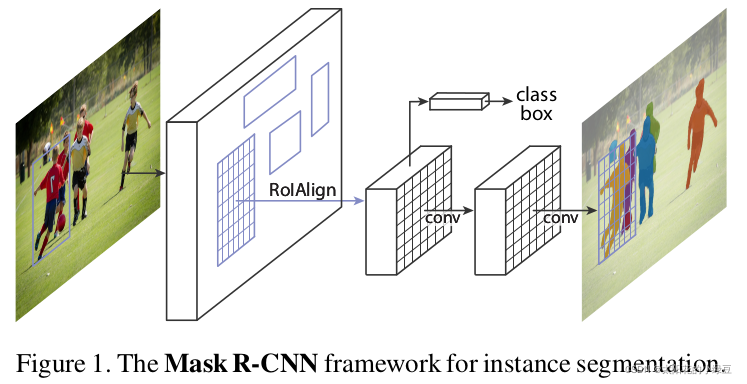
Our method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting segmentation masks on each Region of Interest (RoI), in parallel with the existing branch for classification and bounding box regression (Figure 1). The mask branch is a small FCN applied to each RoI, predicting a segmentation mask in a pixel-to-pixel manner.
Mask R-CNN的结构也很简单,就是在通过RoIAlign(在原Faster R-CNN中是RoIPool)得到的RoI基础上并行添加一个Mask分支(小型的FCN)。见下图,之前Faster R-CNN是在RoI基础上接上一个Fast R-CNN检测头,即图中class, box分支,现在又并行了一个Mask分支。
1.maskrcnn就是在fastrcnn(class+box)的基础上并了一个mask
注意带和不带FPN结构的Mask R-CNN在Mask分支上略有不同,对于带有FPN结构的Mask R-CNN它的class、box分支和Mask分支并不是共用一个RoIAlign(右图)。在训练过程中,对于class, box分支RoIAlign将RPN(Region Proposal Network)得到的Proposals池化到7x7大小(右图上面),而对于Mask分支RoIAlign将Proposals池化到14x14(右图下面)大小。详情参考原论文中的图4.
右边常用

2 .RoI Align
Faster R-CNN was not designed for pixel-to-pixel alignment between network inputs and outputs. This is most evident in how RoIPool, the de facto core operation for attending to instances, performs coarse spatial quantization for feature extraction.
2.maskrcnn把faskrcnn的ROIPOOL换成了ROIAlign
To fix the misalignment, we propose a simple, quantization-free layer, called RoIAlign, that faithfully preserves exact spatial locations.
为了解决这个问题,作者提出了RoIAlign方法替代RoIPool,以获得更加精确的空间定位信息。
为了解决misalignment(定位不够准确)的问题-->作者提出ROIAlign
RoIAlign has a large impact: it improves mask accuracy by relative 10% to 50%, showing bigger gains under stricter localization metrics. Second, we found it essential to decouple mask and class prediction: we predict a binary mask for each class independently, without competition among classes, and rely on the network’s RoI classification branch to predict the category.
作者在文中提到,将RoIPool替换成RoIAlign后,分割的Mask准确率相对提升了10%到50%(见下图d),并且将预测Mask和class进行了解耦,解耦后也带来了很大的提升(见下图b),这个在后面会细讲。

右半部分针对目标检测而言的,数据变大了很多
左半部分是实例分割的结果

2.1ROIPool

ROIPool的目的:
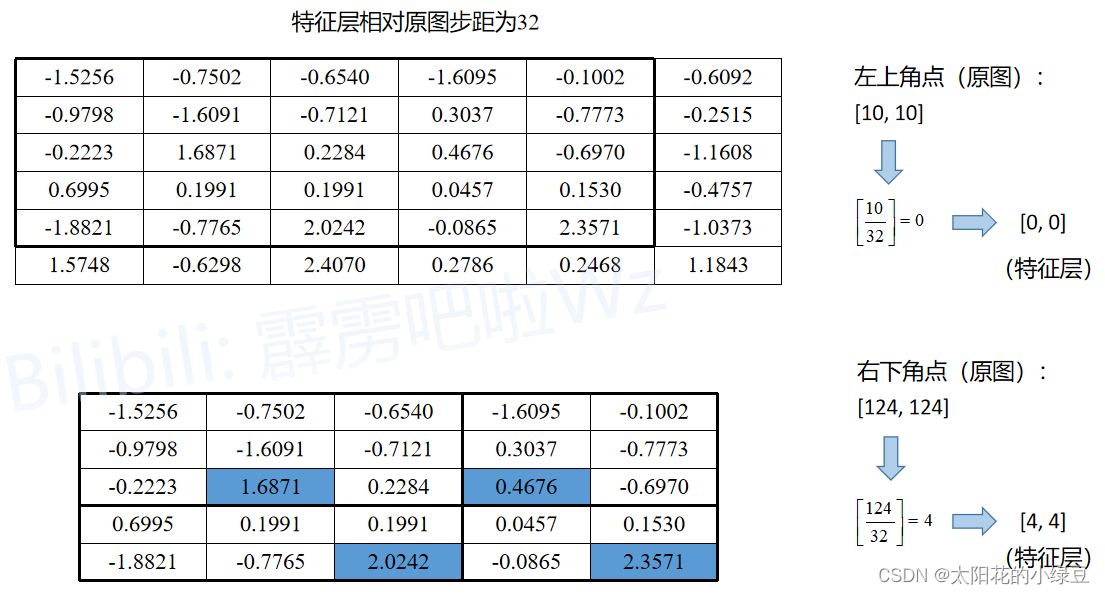
把通过RPN得到的一个Proposal,它在原图上的左上角坐标是( 10 , 10 ) ,右下角的坐标是( 124 , 124 ),对应要映射的特征层相对原图的步距为32,通过RoIPool期望的输出为2x2大小
特征层相对于原图的步距是假设的
ROIPool主要就是很常用四舍五入为了使得到的数字都是整数,就会产生很多误差
步骤:
①把proposal映射到特征层上:
左上角坐标(10,10)除以特征层相对于原图的步距-->(0,0),右下角-->(4,4)
②期望输出2*2大小:
把黑色矩形框均分成4块(均分不了所以四舍五入)
③对每个区域maxpool:取最大值-->输出
下面是使用Torchvision库中实现的RoIPool方法
import torch
from torchvision.ops import RoIPool
""" 用torchvision里提供的ROIPool进行实验"""
def main():
torch.manual_seed(1)
"""固定一下随机数种子"""
x = torch.randn((1, 1, 6, 6))
"""生成一个x假设为我们刚才的得到的特征层"""
print(f"feature map: \n{x}")
proposal = [torch.as_tensor([[10, 10, 124, 124]], dtype=torch.float32)]
"""左上角的点是(10,10)右下角的点是(124,124)"""
"""数字都跟上图一样"""
roi_pool = RoIPool(output_size=2, spatial_scale=1/32)
"""实例化一个ROIPool,输出大小设置成2*2,下采样设置成32"""
roi = roi_pool(x, proposal)
"""把特征层和目标传入ROIPool"""
print(f"roi pool: \n{roi}")
"""得到四个值"""
if __name__ == '__main__':
main()
终端输出:
feature map:
tensor([[[[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002, -0.6092],
[-0.9798, -1.6091, -0.7121, 0.3037, -0.7773, -0.2515],
[-0.2223, 1.6871, 0.2284, 0.4676, -0.6970, -1.1608],
[ 0.6995, 0.1991, 0.1991, 0.0457, 0.1530, -0.4757],
[-1.8821, -0.7765, 2.0242, -0.0865, 2.3571, -1.0373],
[ 1.5748, -0.6298, 2.4070, 0.2786, 0.2468, 1.1843]]]])
roi pool:
tensor([[[[1.6871, 0.4676],
[2.0242, 2.3571]]]])
"""和上图得到的结果一样,把proposal输出成2*2大小"""
2.2ROIAlign
不进行取整
步骤:
为了方便把特征层上的每一个元素抽象成一个黑点,比如左上角第一个黑点就是 -1.5256
①把proposal映射到特征层上:
蓝色矩形框的左上角坐标就是(0.3125,0.3125),右下角坐标就是(3.875,3.875)
②期望输出2*2大小:
把蓝色矩形框均分成4块
③对每个子区域求它的输出,在每个区中设置采样点个数,这里设置一个采样点(sampling radio =1),对于每个区就计算中心点的坐标.(具体怎么求看下面的图)
(每个区中的采样点个数==sampling ratio的平方,当采用多个采样点的时候,每个子域的输出取所有样点的均值)


主要是用到了双线性插值
图解:
①x和y是第一个中心点的坐标
0.3125(左上角的点)+(3.875-0.3125)/4(整个蓝色框的长度/4==第一个中心点离边框的距离)
②f1234是四个点的数值,u,v标在图里了 -->f(-0.8546): 2*2输出里的第一个数

下面是使用Torchvision库中实现的RoIAlign方法
import torch
from torchvision.ops import RoIAlign
"""torchvision导入官方实现好的ROIAlign"""
def bilinear(u, v, f1, f2, f3, f4):
return (1-u)*(1-v)*f1 + u*(1-v)*f2 + (1-u)*v*f3 + u*v*f4
def main():
torch.manual_seed(1)
x = torch.randn((1, 1, 6, 6))
"""特征层"""
print(f"feature map: \n{x}")
proposal = [torch.as_tensor([[10, 10, 124, 124]], dtype=torch.float32)]
"""目标"""
roi_align = RoIAlign(output_size=2, spatial_scale=1/32, sampling_ratio=1)
"""实例化ROIAlign"""
roi = roi_align(x, proposal)
"""输入特征层,目标"""
print(f"roi align: \n{roi}")
"""这块就是展示了一下使用了双线性插值bilinear"""
u = 0.203125
v = 0.203125
f1 = x[0, 0, 1, 1] # -1.6091
f2 = x[0, 0, 1, 2] # -0.7121
f3 = x[0, 0, 2, 1] # 1.6871
f4 = x[0, 0, 2, 2] # 0.2284
print(f"bilinear: {bilinear(u, v, f1, f2, f3, f4):.4f}")
if __name__ == '__main__':
main()
终端输出:
feature map:
tensor([[[[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002, -0.6092],
[-0.9798, -1.6091, -0.7121, 0.3037, -0.7773, -0.2515],
[-0.2223, 1.6871, 0.2284, 0.4676, -0.6970, -1.1608],
[ 0.6995, 0.1991, 0.1991, 0.0457, 0.1530, -0.4757],
[-1.8821, -0.7765, 2.0242, -0.0865, 2.3571, -1.0373],
[ 1.5748, -0.6298, 2.4070, 0.2786, 0.2468, 1.1843]]]])
roi align:
tensor([[[[-0.8546, 0.3236],
[ 0.2177, 0.0546]]]])
bilinear: -0.8546
We note that the results are not sensitive to the exact sampling locations, or how many points are sampled, as long as no quantization is performed.
最后作者在论文中有提到,关于最终的采样结果对采样点位置,以及采样点的个数并不敏感。
3 Mask Branch(FCN)
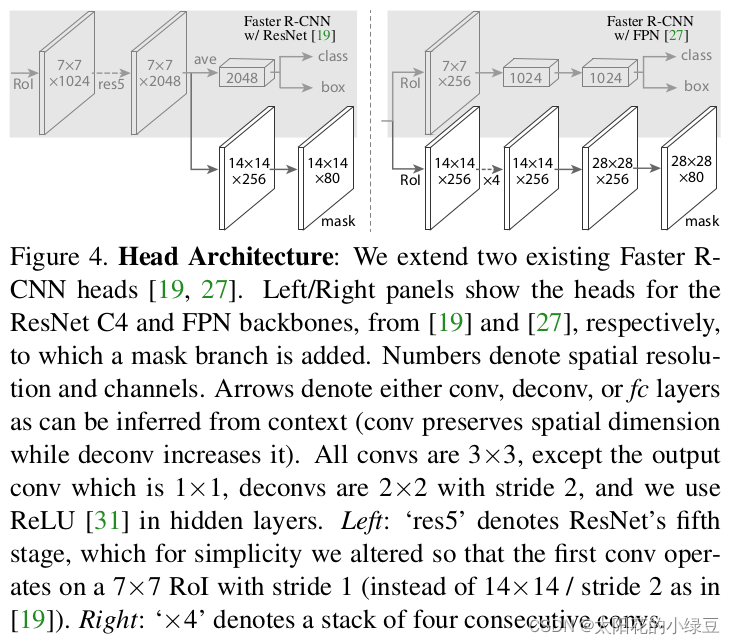
前面有提到,对于带有FPN和不带有FPN的Mask R-CNN,他们的Mask分支不太一样。下图左边是不带FPN结构的Mask分支,右侧是带有FPN结构的Mask分支(灰色部分为原Faster R-CNN预测box, class信息的分支,白色部分为Mask分支)。
1.maskrcnn就是在fastrcnn(class+box)的基础上并了一个mask
右图下面的分支保留了更多的细节
由于在我们日常使用中,一般都是使用的带有FPN的网络,所以我自己又手绘了一幅针对带有FPN结构的Mask分支:
下图图解:
输入的目标:H*W*256大小
--ROIAlign-->14*14*256大小
--四个卷积层-->14*14*256大小
--转置卷积+ReLU-->28*28*256(将输入的高宽进行翻倍)
--1*1的卷积层-->28*28*num(classes) (针对每个类别都预测了一个蒙版,并且蒙版大小都是28*28)

之前在讲FCN的时候有提到过,FCN是对每个像素针对每个类别都会预测一个分数,然后通过softmax得到每个类别的概率(不同类别之间存在竞争关系),哪个概率高就将该像素分配给哪个类别(那么其中有的类别概率高,有的类别概率就会小)。但在Mask R-CNN中,作者将预测Mask和class进行了解耦,即对输入的RoI针对每个类别都单独预测一个Mask,最终根据box, cls分支预测的classes信息来选择对应类别的Mask(不同类别之间不存在竞争关系)。作者说解耦后带来了很大的提升。下表是原论文中给出的消融实验结果,其中softmax代表原FCN方式(Mask和class未解耦),sigmoid代表Mask R-CNN中采取的方式(Mask和class进行了解耦)。

在训练网络的时候输入Mask分支的目标是由RPN提供的,即Proposals(正样本)(正样本是faskrcnn分支进行正负样本匹配时得到的)(也就是把proposal放进右边上部分的class,box部分)
但在预测的时候输入Mask分支的目标是由Fast R-CNN提供的(即预测的最终目标)。
RPN(Region Proposal Network) 是 Fast R-CNN 的一部分:是的,RPN 是 Faster R-CNN 模型中的一个组成部分,负责生成候选区域。
并且训练时采用的Proposals全部是Fast R-CNN阶段匹配到的正样本。这里说下我个人的看法(不一定正确),在训练时Mask分支利用RPN提供的目标信息能够扩充训练样本的多样性(因为RPN提供的目标边界框并不是很准确,一个目标可以呈现出不同的情景,类似于围着目标做随机裁剪。从另一个方面来看,通过Fast R-CNN得到的输出一般都比较准确了,再通过NMS后剩下的目标就更少了)。在预测时为了获得更加准确的目标分割信息以及减少计算量(通过Fast R-CNN后的目标数会更少),此时利用的是Fast R-CNN提供的目标信息。
4 其他细节

比faskrcnn的损失就多了一个mask的损失


4.3 Mask Branch预测使用
这里再次强调一遍,在真正预测推理的时候,输入Mask分支的目标是由Fast R-CNN分支提供的。


版权声明:本文为太阳花的小绿豆原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_37541097/article/details/123754766















 2866
2866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









