







前言
声明:本文参考了李宏毅机器学习2020年作业例程,基本上是将代码复现了一遍,开发平台是Pycharm社区版2021。
开发环境:Anaconda3+Pycharm,python3.6.8。
一、问题描述
数据可以从Kaggle上获取。链接:Kaggle数据下载
作业要求:在收集来的资料中均是食物的照片,共有11类,Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.我们要创建一个CNN,用来实现食物的分类。
我们可以借助于深度学习的框架(例如:Tensorflow/pytorch等)来帮助我们快速实现网络的搭建,在这里我们利用Pytorch来实现。
二、实现过程
2.1 调包
需要的库函数:
pandas:一个强大的分析结构化数据的工具集。
numpy: Python的一个扩展程序库,支持大量的维度数组与矩阵运算。
os:可以对路径和文件进行操作的模块。
time:提供各种与时间相关的函数。
pytorch:深度学习框架(下载时注意有无gpu)。
opencv:开源的图像处理库。
没有库的请自行安装(Jupyter Notebook安装方法:进入自己的环境,conda install 库名字
即可;Pycharm安装方法:部分可以直接在解释器设置里搜索相应库进行安装)
# Import需要的库函数
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
2.2 数据处理
2.2.1首先读入图片数据,并进行缩放处理,使得每个图片像素数量相同。
def readfile(path, flag):
"""
:param path: 图片所在文件夹位置
:param flag: 1:训练集或验证集 0:测试集
:return: 图片数值化后的数据
"""
image_dir = os.listdir(path)#返回指定的文件夹包含的文件或文件夹的名字的列表
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8) # 因为是图片,所以这里设为uint8
y = np.zeros((len(image_dir)))
# print(x.shape)
# print(y.shape)
for i, file in enumerate(image_dir): # 遍历每一张图片
#os.path.join()函数:连接两个或更多的路径名组件
img = cv2.imread(os.path.join(path, file)) # cv2.imread()返回多维数组,前两维表示像素,后一维表示通道数
x[i, :, :, :] = cv2.resize(img, (128, 128)) # 因为每张图片的大小不一样,所以先统一大小,每张图片的大小为(128,128,3)
# cv2.imshow('new_image', x[i])
# cv2.waitKey(0)
if flag:
y[i] = int(file.split('_')[0])
if flag:
return x, y
else:
return x
2.2.2分别将 training set、validation set、testing set 用 readfile 函数读进来。
workspace_dir = './food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
2.2.3数据增强:增加数据量并把数据格式转换成张量tensor的形式。
# training 时做 data augmentation
train_transform = transforms.Compose([
transforms.ToPILImage(),
# 增强数据
transforms.RandomHorizontalFlip(), # 随机将图片水平翻转
transforms.RandomRotation(15), # 随机旋转图片15度
transforms.ToTensor(), # 将图片转成Tensor并normalize 到 [0,1] (data normalization)
])
# testing 时不需要 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
2.2.4在 PyTorch 中,我们可以利用 Dataset 及 DataLoader 来"包装" data,使后续的 training 及 testing 更为方便。
- PyTorch中的DataSet和DataLoader用来处理数据十分方便。
- DataSet可以实现对数据的封装,当我们继承了DataSet类后,需要重写len和getitem这两个方法,len方法提供了dataset的大小,getitem方法支持索引从 0 到 len(self)的数据,这也是为什么需要len方法。
- DataLoader通过getitem函数获取单个的数据,然后组合成batch。
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else: # 如果没有标签那么只返回x
return X
2.2.5接下来就可以使用下面的语句来调用上面的定义,并采用分批次训练(加快参数更新速度),设置好我们的batch_size大小,这里设置为64,然后包装好我们的数据。
batch_size = 64
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
2.3 网络搭建
利用pytorch来构建网络模型。
构建网络需要继承nn.Module,并且调用nn.Module的构造函数。
利用nn.Conv2d,nn.BatchNorm2d,nn.ReLU,nn.MaxPool2d这4个函数来构建一个5层的CNN。
- nn.Conv2d:卷积层
- nn.BatchNorm2d:归一化
- nn.ReLU:激活层
- nn.MaxPool2d:最大池化层
卷积层之后进入到一个3层全连接层,最后输出结果。
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
#卷积层
self.cnn = nn.Sequential( # 模型会依次执行Sequential中的函数
#卷积层1
nn.Conv2d(3, 64, 3, 1, 1), # output:[64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output:[64, 64, 64]
#卷积层2
nn.Conv2d(64, 128, 3, 1, 1), # output:[128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output:[128, 32, 32]
#卷积层3
nn.Conv2d(128, 256, 3, 1, 1), # output:[256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output:[256, 16, 16]
#卷积层4
nn.Conv2d(256, 512, 3, 1, 1), # output:[512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output:[512, 8, 8]
#卷积层5
nn.Conv2d(512, 512, 3, 1, 1), # output:[512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output:[512, 4, 4]
)
#全连接层
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
#前向传播
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
view(out.size(0), -1):
目的是将多维的的数据如(none,36,2,2)平铺为一维如(none,144)。作用类似于keras中的Flatten函数。只不过keras中是和卷积一起写的,而pytorch是在forward中才声明的。
2.4 模型训练
模型构建好之后,我们就可以开始训练了。
model = Classifier().cuda()#使用GPU并行计算
loss = nn.CrossEntropyLoss() # 因为是 classification task,所以 loss 使用 CrossEntropyLoss交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam,learning rate取0.001。
num_epoch = 30 #迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0 #计算每个opoch的accuracy(精度)与loss(损失)
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 train model (开启 Dropout 等...);保证BN层用每一批数据的均值和方差
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 将 model 参数的 gradient 归零
# 利用 model 进行前向传播(forward 函数) ,计算预测值
train_pred = model(data[0].cuda()) # data[0] = x, data[1] = y
batch_loss = loss(train_pred, data[1].cuda())# 计算 loss (注意 prediction 跟 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用反向传播(back propagation) 算出每个参数的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新參數值
# .data表示将Variable中的Tensor取出来
# train_pred是(50,11)的数据,np.argmax()返回最大值的索引,axis=1则是对行进行,返回的索引正好就对应了标签,然后和y真实标签比较,则可得到分类正确的数量
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()# 张量中只有一个值就可以使用item()方法读取
model.eval() # 固定均值和方差,使用之前每一批训练数据的均值和方差的平均值
with torch.no_grad():# 进行验证,不进行梯度跟踪
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
# 將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time() - epoch_start_time, \
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
之前一直迷惑为什么train_pred = model(data[0].cuda())没提到forward函数却可以正常运行?后来查询资料明白:
因为nn.Module的__call__函数中调用了forward()函数,那么__call__作用是什么呢?它允许我们把一个实例当作对象一样来调用。
运行结果: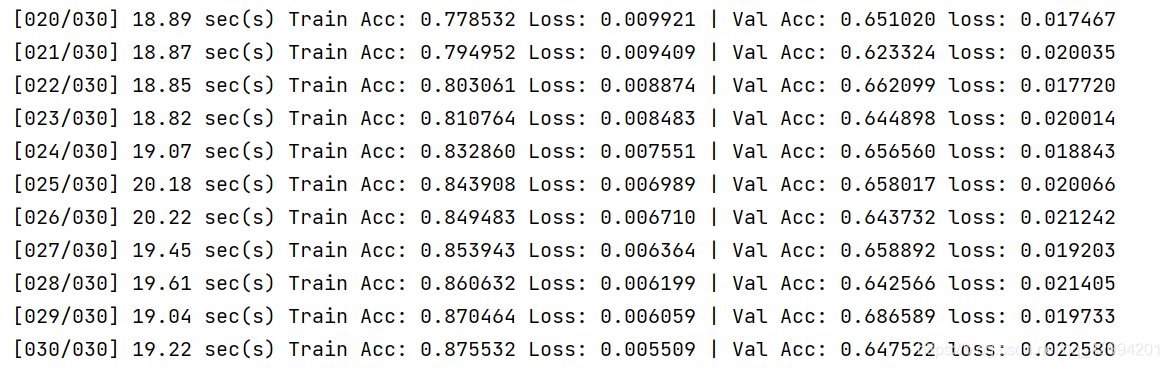
从训练结果上看,训练集精度较高,验证集精度不高。
接下来,
将训练集和验证集组成一个训练集。
train_val_x = np.concatenate((train_x, val_x), axis=0)
train_val_y = np.concatenate((train_y, val_y), axis=0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
再次训练。
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 因為是 classification task,所以 loss 使用 CrossEntropyLoss
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
运行结果: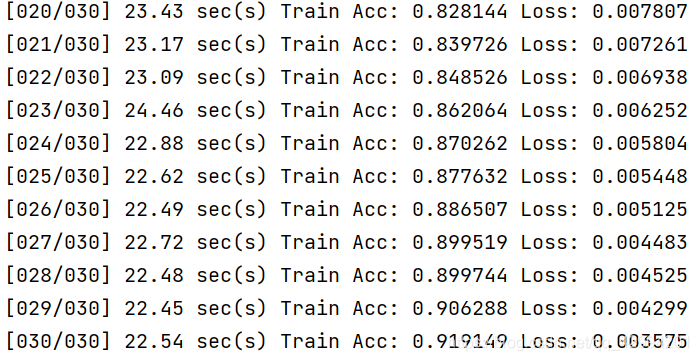
可以看出模型在训练集上的精度达到了91.9%
2.5数据预测
在测试集上跑一下,并将预测结果写入csv文件中。
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#保存预测结果
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
运行结果
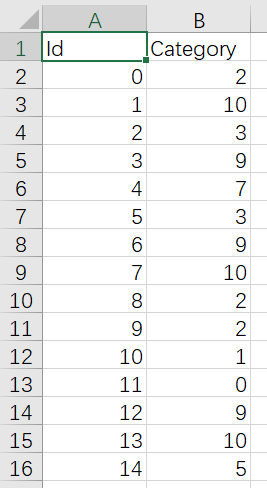
三、完整代码
3.1官方版本
# Import需要的套件
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
#Read image 利用 OpenCV (cv2) 讀入照片並存放在 numpy array 中
def readfile(path, label):
# label 是一個 boolean variable,代表需不需要回傳 y 值
image_dir = sorted(os.listdir(path))
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
# 分別將 training set、validation set、testing set 用 readfile 函式讀進來
workspace_dir = './food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
# training 時做 data augmentation
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), # 隨機將圖片水平翻轉
transforms.RandomRotation(15), # 隨機旋轉圖片
transforms.ToTensor(), # 將圖片轉成 Tensor,並把數值 normalize 到 [0,1] (data normalization)
])
# testing 時不需做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
batch_size = 64
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 因為是 classification task,所以 loss 使用 CrossEntropyLoss
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 確保 model 是在 train model (開啟 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 將 model 參數的 gradient 歸零
train_pred = model(data[0].cuda()) # 利用 model 得到預測的機率分佈 這邊實際上就是去呼叫 model 的 forward 函數
batch_loss = loss(train_pred, data[1].cuda()) # 計算 loss (注意 prediction 跟 label 必須同時在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每個參數的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新參數值
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
# 將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time() - epoch_start_time, \
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
train_val_x = np.concatenate((train_x, val_x), axis=0)
train_val_y = np.concatenate((train_y, val_y), axis=0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 因為是 classification task,所以 loss 使用 CrossEntropyLoss
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#將結果寫入 csv 檔
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
3.2另一版本
import os
import torch
import cv2
import time
import numpy as np
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
train_transform = transforms.Compose([
transforms.ToPILImage(),
# 增强数据
transforms.RandomHorizontalFlip(), # 随即将图片水平翻转
transforms.RandomRotation(15), # 随即旋转图片15度
transforms.ToTensor(), # 将图片转成Tensor
])
# testing 時不需做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__() # 需要调用module的构造函数
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
self.cnn = nn.Sequential( # 模型会依次执行Sequential中的函数
# 卷积层1
nn.Conv2d(3, 64, 3, 1, 1), # output: 64 * 128 * 128
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 64 * 64 * 64
# 卷积层2
nn.Conv2d(64, 128, 3, 1, 1), # output: 128 * 64 * 64
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 128 * 32 * 32
# 卷积层3
nn.Conv2d(128, 256, 3, 1, 1), # output: 256 * 32 * 32
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 256 * 16 * 16
# 卷积层4
nn.Conv2d(256, 512, 3, 1, 1), # output: 512 * 16 * 16
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 8 * 8
# 卷积层5
nn.Conv2d(512, 512, 3, 1, 1), # output: 512 * 8 * 8
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # output: 512 * 4 * 4
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
res_x = self.x[index]
if self.transform is not None:
res_x = self.transform(res_x)
if self.y is not None:
res_y = self.y[index]
return res_x, res_y
else: # 如果没有标签那么只返回x
return res_x
def readfile(path, flag):
"""
:param path: 图片所在文件夹位置
:param flag: 1:训练集或验证集 0:测试集
:return: 图片数值化后的数据
"""
image_dir = os.listdir(path)
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8) # 因为是图片,所以这里设为uint8
y = np.zeros((len(image_dir)))
# print(x.shape)
# print(y.shape)
for i, file in enumerate(image_dir): # 遍历每一张图片
img = cv2.imread(os.path.join(path, file)) # cv2.imread()返回多维数组,前两维表示像素,后一维表示通道数
x[i, :, :, :] = cv2.resize(img, (128, 128)) # 因为每张图片的大小不一样,所以先统一大小,每张图片的大小为(128,128,3)
# cv2.imshow('new_image', x[i])
# cv2.waitKey(0)
if flag:
y[i] = file.split('_')[0]
if flag:
return x, y
else:
return x
def training(train_loader, val_loader):
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # troch.nn中已经封装好了各类损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epoch = 30 # 迭代次数
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 保证BN层用每一批数据的均值和方差
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 清空之前的梯度
train_pred = model(data[0].cuda()) # data[0] = x, data[1] = y
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
# .data表示将Variable中的Tensor取出来
# train_pred是(50,11)的数据,np.argmax()返回最大值的索引,axis=1则是对行进行,返回的索引正好就对应了标签,然后和y真实标签比较,则可得到分类正确的数量
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item() # 张量中只有一个值就可以使用item()方法读取
model.eval() # 固定均值和方差,使用之前每一批训练数据的均值和方差的平均值
with torch.no_grad(): # 进行验证,不进行梯度跟踪
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time() - epoch_start_time, \
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
return model
def predict(test_loader, model):
model.eval()
result = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
result.append(y)
return result
def writefile(result):
f = open('result.csv', 'a')
f.write('Id,Category\n')
for i, res in enumerate(result):
f.write('{},{}\n'.format(i, res))
f.close()
if __name__ == '__main__':
train_x, train_y = readfile('./data/food-11/food-11/training', True)
val_x, val_y = readfile('./data/food-11/food-11/validation', True)
test_x = readfile('./data/food-11/food-11/testing', False)
batch_size = 50
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
test_set = ImgDataset(x=test_x, transform=test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model = training(train_loader, val_loader)
result = predict(test_loader, model)
writefile(result)
https://www.cnblogs.com/zyb993963526/p/13732487.html#_label5















 4775
4775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









