






1.从尾到头打印链表
输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。
思路:(1)利用栈先入后出的特性完成; (2)第二就是存下来然后进行数组翻转。
(3)利用递归。
代码:
//利用c++中自带的翻转函数reverse实现
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> value;
ListNode *p = head;
while(p != nullptr)
{
value.push_back(p->val);//vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。push_back将p->val加入到value这个vector中
p = p->next;
}
reverse(value.begin(),value.end());//c++中自带的逆置函数
return value;
}
};
//利用栈先入后出的特性
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> v;
stack<int> s;
int p;
while(head != nullptr)
{
s.push(head->val);
head = head->next;
}
while( !s.empty())
{
p = s.top();//取出栈顶元素给p
s.pop(); //出栈
v.push_back(p);
}
return v;
}
};
// 递归思路
class Solution {
public:
vector<int> value;
vector<int> printListFromTailToHead(ListNode* head) {
ListNode *p = nullptr;
p = head;
if(p != nullptr){
if(p->next != nullptr){
printListFromTailToHead(p->next);
}
value.push_back(p->val);
}
return value;
}
};
2. 链表中倒数第k个结点
输入一个链表,输出该链表中倒数第k个结点。
思路:
方法1,遍历两次,第一次计算总长度,第二次找length-k+1个即可。(略)
方法2,遍历一次,用两个指针,第一个指针指向第i个,第二个指针指向i+k-1个即可,当第二个指针指向最后一个时,第一个指针指向的是倒数第k个。注意考虑空指针,k为0的情况(k为无符号,无符号-1很大的)
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
if(pListHead == nullptr || k == 0) return nullptr;
ListNode *p1 = pListHead, *p2 = pListHead;
for(int i = 0; i < k-1; i++)
if(p1->next != nullptr)
p1 = p1->next;
//考虑列表的长度小于k值
else
return nullptr;
while(p1->next != nullptr)
{
p1 = p1->next;
p2 = p2->next;
}
return p2;
}
};
3. 反转链表
输入一个链表,反转链表后,输出新链表的表头。
思路:遍历时,新链表newhead指向当前遍历结点,newhead->next指向上一个遍历的结点。为了防止断链,需要加临时变量存储当前的next。
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
if(pHead == nullptr) return nullptr;
ListNode *p = nullptr, *pNode = pHead, *r = nullptr;
while(pNode != nullptr)
{
ListNode *s = pNode->next;
p = pNode;
p->next = r;
r = pNode;
pNode = s;
// pNode = pNode->next; //不能省去第一个s赋值直接将pNode->next赋值给pNode。
}
return p;
}
};
4. 合并两个排序链表
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
代码1(递归):
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2)
{
if(pHead1 == nullptr) return pHead2;
if(pHead2 == nullptr) return pHead1;
ListNode *p = nullptr;
if(pHead1->val <= pHead2->val)
{
p = pHead1;
p->next = Merge(pHead1->next, pHead2);
}
else
{
p = pHead2;
p->next = Merge(pHead1, pHead2->next);
}
return p;
}
};
代码2(非递归):
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2)
{
if(pHead1 == nullptr) return pHead2;
if(pHead2 == nullptr) return pHead1;
ListNode *p = nullptr, *r = nullptr;
while(pHead1 != nullptr && pHead2 != nullptr)
{
if(pHead1->val <= pHead2->val)
{
if(p == nullptr) p = r = pHead1;
else{
r->next = pHead1;//有疑问???
r = r->next;
}
pHead1 = pHead1->next;
}
else
{
if(p == nullptr) p = r = pHead2;
else{
r->next = pHead2;
r = r->next;
}
pHead2 = pHead2->next;
}
}
if(pHead1 != nullptr) r->next = pHead1;
if(pHead2 != nullptr) r->next = pHead2;
return p;
}
};
5. 复杂链表的复制
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
思路:
way1:复制原始链表上的每一个结点,并通过pNext连接起来;然后再设置每个结点的pSibling指针。
假设原始链表中某个结点N的pSibling指针指向结点S,那么就需要从头到尾遍历查找结点S,如果从原始链表的头指针开始,经过m步之后达到结点S,那么在复制链表中的结点N’的pSibling指针指向的结点也是距离复制链表s步的结点。通过这种办法就可以为复制链表上的每个结点设置pSibling指针。
时间复杂度:O(N^2)
way2:方法1是通过链表查找来得到pSibling指针所指向的结点,实际上我们可以通过空间换取时间,将原始链表和复制链表的结点通过哈希表对应起来,这样查找的时间就从O(N)变为O(1)。具体如下:
复制原始链表上的每个结点N创建N’,然后把这些创建出来的结点用pNext连接起来。同时把<N,N’>的配对信息方法一个哈希表中;然后设置复制链表中的每个结点的pSibling指针,如果原始链表中结点N的pSibling指向结点S,那么在复制链表中,对应的N’应该指向S’。
时间复杂度:O(N)
代码:
/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead)
{
if(pHead == nullptr) return nullptr;
RandomListNode* newHead = new RandomListNode(pHead->label);//建立复制链表
RandomListNode *p = pHead, *np = newHead;// 流动链表节点
map<RandomListNode*, RandomListNode*> M; //map功能:自动建立Key - value的对应。key 和 value可以是任意你需要的类型。
M[pHead] = newHead;
//第一步:复制主干
while(p->next !=nullptr)
{
np->next = new RandomListNode(p->next->label);
np = np->next;
p = p->next;
M[p] = np;
}
p = pHead, np = newHead;
//第二步:复制随意节点
while(p != nullptr)
{
//RandomListNode* r = p->random; 采用该种方式进行判断p->random是否为空,反而会降低时间效率
if(p->random != nullptr) np->random = M[p->random];
np = np->next;
p = p->next;
}
return newHead;
}
};
方法3:在不使用辅助空间的情况下实现O(N)的时间效率。
第一步:根据原始链表的每个结点N创建对应的N’,然后将N‘通过pNext接到N的后面;
第二步:设置复制出来的结点的pSibling。假设原始链表上的N的pSibling指向结点S,那么其对应复制出来的N’是N->pNext指向的结点,同样S’也是结点S->pNext指向的结点。
第三步:把长链表拆分成两个链表,把奇数位置的结点用pNext连接起来的就是原始链表,把偶数位置的结点通过pNext连接起来的就是复制链表。
代码:
/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead)
{
if(pHead == nullptr) return nullptr;
RandomListNode *p = pHead, *newHead, *t;
//第一步:在每个节点后面复制相同节点并连接成一个链表
while(p != nullptr)
{
t = new RandomListNode(p->label);
t->next = p->next;
p->next = t;
p = t->next;
}
//第二步:复制随意节点
p = pHead;
while(p != nullptr)
{
t = p->random;
if(t != nullptr) p->next->random = t->next;
p = p->next->next;
}
//第三步:分离
p = pHead, newHead = pHead->next;
t = newHead;
while(t->next != nullptr)
{
p->next = p->next->next;
t->next = t->next->next;
p = p->next;
t = t->next;
}
p->next = nullptr; //去除这一步测试错误???
return newHead;
}
};
6. 二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
思路:原先指向左子结点的指针调整为链表中指向前一个结点的指针,原先指向右子结点的指针调整为链表中指向下一个结点的指针。由于是排序双链表所以采用中序遍历。详见代码
代码:
/*struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
TreeNode* Convert(TreeNode* pRootOfTree)
{
TreeNode *pLastNode = nullptr;
ConvertNode(pRootOfTree, &pLastNode);//传递的是pLastNode的地址
//pLastNode 指向尾结点,此时一直往左走找到头结点返回
while(pLastNode != nullptr && pLastNode->left != nullptr)
pLastNode = pLastNode->left;
return pLastNode;
}
void ConvertNode(TreeNode* pRoot, TreeNode **pLast)//注意是二维指针
{
if(pRoot == nullptr)
return;
//遍历左子树
if(pRoot->left != nullptr)
ConvertNode(pRoot->left, pLast);
//根结点:左子树的最后一个结点为根结点的左结点,根结点是左子树最后一个结点的右节点
pRoot->left = *pLast;
if(*pLast != nullptr)
(*pLast)->right = pRoot;
//遍历右子树
*pLast = pRoot;
if(pRoot->right != nullptr)
ConvertNode(pRoot->right, pLast);
}
};
7. 两个链表的第一个公共点
输入两个链表,找出它们的第一个公共结点。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
思路:两个有公共节点而部分重合的链表,其拓扑形状看起来像一个Y,如图所示:
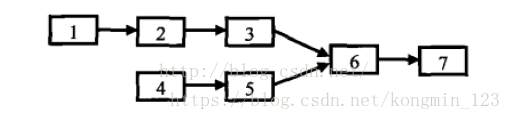
way1:蛮力法解决:在第一个链表上顺序遍历每一个节点,每遍历到一个节点,就在第二个链表上顺序遍历每个节点。如果在第二个链表上有一个节点与第一个链表上的节点一样,则说明两个链表在这个节点上重合,于是就找到了他们的公共节点。如果第一个链表的长度为m,第二个链表的长度为n,那么,显然该方法的时间复杂度是O(mn)。
way2:如果我们从两个链表的尾部开始往前比较,那么最后一个相同的结点就是我们要找的结点。可问题是,在单向链表中,我们只能从头结点开始按顺序遍历,最后才能到达尾节点。最后到达的尾节点却要最先被比较,这听起来是不是像“后进先出”?于是我们就能想到用栈的特点来解决这个问题:分别把两个链表的结点放入两个栈里,这样两个链表的尾节点就位于两个栈的栈顶,接下来比较两个栈顶的结点是否相同。如果相同,则把栈顶弹出接着比较下一个栈顶,直到找到最后一个相同的节点。
在上述思路中,我们需要用两个辅助栈。如果链表的长度分别为m和n,那么空间复杂度是O(m+n)。这种思路的时间复杂度也是O(m+n)。和最开始的蛮力法相比,时间效率得到了提高,相当于是用空间消耗换取了时间效率。
way3:首先遍历两个链表得到他们的长度,就能知道哪个链表比较长,以及长的链表比短的链表多几个结点。在第二次遍历的时候,在较长的链表上先走若干步,接着同时在两个链表上遍历,找到的第一个相同的结点就是他们的第一个公共结点。way3和way2相比时间复杂度为O(m+n),但我们不在需要辅助栈,因此提高了空间效率。
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
int lenA = 0, lenB = 0;
ListNode *a = pHead1;
while(a != nullptr)
{
lenA ++;
a = a->next;
}
a = pHead2;
while(a != nullptr)
{
lenB ++;
a = a->next;
}
if(lenA < lenB)
{
int t;
t = lenA; lenB = lenA; lenB = t;
a = pHead1; pHead1 = pHead2; pHead2 = a;
}
int d = lenA - lenB;
while(d --) pHead1 = pHead1->next;
while(pHead1 != nullptr)
{
if(pHead1 == pHead2) return pHead1;
pHead1 = pHead1->next;
pHead2 = pHead2->next;
}
return nullptr;
}
};
8. 链表中环的入口结点
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
思路:
第一步,找环中相汇点。分别用p1,p2指向链表头部,p1每次走一步,p2每次走二步,直到p1==p2找到在环中的相汇点。
第二步,找环的长度。从环中的相汇点开始, p2不动, p1前移, 当再次相遇时,p1刚好绕环一周, 其移动即为环的长度K,使用一快一慢两个指针(比如慢指针一次走一步,慢指针一次走两步),如果走的过程中发现快指针追上了慢指针, 说明遇见了环,而且相遇的位置一定在环内, 考虑一下环内, 从任何一个节点出现再回到这个节点的距离就是环的长度, 于是我们可以进一步移动慢指针,快指针原地不动, 当慢指针再次回到相遇位置时, 正好在环内走了一圈, 从而我们通过计数就可以获取到环的长度
第三步, 求换的起点, 转换为求环的倒数第N-K个节点,则两指针p1和p2均指向起始, p2先走K步, 然后两个指针开始同步移动, 当两个指针再次相遇时, p2刚好绕环一周回到起点, p1则刚好走到了起点位置
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* EntryNodeOfLoop(ListNode* pHead)
{
if(pHead == NULL || pHead->next == NULL || pHead->next->next ==NULL)
return NULL;
//第一步:求是否存在环
ListNode* p1 = pHead->next->next;
ListNode* p2 = pHead->next;
while (p1 != p2)
{
if (p1->next != NULL && p1->next->next != NULL)
{
p1 = p1->next->next;
p2 = p2->next;
}
else
return NULL;
}
//第二步:寻找环的长度
int count = 1;
while(p2->next != p1)
{
p2 = p2->next;
count++;
}
//第三步:寻找环的入口结点
p1 = pHead;
p2 = pHead;
for (int i=0; i<count; i++)
p2 = p2->next;
while(p1 != p2)
{
p1 = p1->next;
p2 = p2->next;
}
return p2;
}
};
9. 删除链表中重复的结点
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
思路:首先,检查边界条件(链表有0个节点或链表有1个节点)时,返回头结点;其次,避免由于第一个节点是重复节点而被删除,新建一个指向头结点的节点;再次,建立三个指针pre/p/next,分别指向当前节点的前序节点、当前节点、当前节点的后续节点;最后循环遍历整个链表,如果节点p的值和节点next的值相同,则删除节点p和节点next,pre和下一个没有重复的节点连接。如果节点p的值和节点next的值不同,则三个指针向后移动一个指针。
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead)
{
// 链表有0个/1个节点,返回第一个节点
if(pHead == nullptr || pHead->next == nullptr)
return pHead;
// 新建一个头节点,防止第一个结点被删除
ListNode* newpHead = new ListNode(-1);
newpHead->next = pHead;
// 建立索引指针
ListNode* p = pHead; // 当前节点
ListNode* pre = newpHead;// 当前节点的前序节点
ListNode* next= p->next;// 当前节点的后序节点
while(p != nullptr && p->next != nullptr)
{
if(p->val == next->val)
{
// 循环查找,找到与当前节点不同的节点
while(next != nullptr && next->val == p->val)
{
ListNode* tmp = next;
next = next->next;
// 删除内存中的重复节点
delete tmp;
tmp = nullptr;
}
pre->next = next;
p = next;
}
//如果当前节点和下一个节点值不等,则向后移动一位
else
{
pre = p;
p = p->next;
}
next = p->next;
}
//返回头结点的下一个节点
return newpHead->next;
}
};
附加题:
删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次
例如:
给出的链表为1->2->3->3->4->4->5 处理后为 1->2->3->4->5
代码:
class Solution {
public:
/**
*
* @param head ListNode类
* @return ListNode类
*/
ListNode* deleteDuplicates(ListNode* head) {
// write code here
if(head == nullptr || head->next == nullptr)
return head;
ListNode *p = head;
while(p)
{
ListNode *next =p->next;
while(p->val == next->val && next != nullptr)
{
ListNode *tmp = next;
next = next->next;
free(tmp);
}
p = p->next = next;
}
return head;
}
};
10. 判断一个链表是否为回文结构
给定一个链表,请判断该链表是否为回文结构。
示例1
输入
[1,2,2,1]
输出
true
思路: 回文结构即判断该链表是否是对称的,或者说其倒序和正序的序列应该是一样,所以可以采用栈来判断其是否为回文结构。
代码:
class Solution {
public:
/**
*
* @param head ListNode类 the head
* @return bool布尔型
*/
bool isPail(ListNode* head) {
// write code here
if(head == nullptr)
return false;
stack<int> stk;
ListNode *p = head;
while(p)
{
stk.push(p->val);
p = p->next;
}
p = head;
while(p)
{
if(!stk.empty() && stk.top() == p->val)
{
stk.pop();
p = p->next;
}
else
return false;
}
return true;
}
};
















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









