









利用labelme创建边缘检测数据集(安装与使用)
第一步:安装Ananconda
这个很简单,百度搜索官网下载安装就可以
具体可以参考博客的第一部分:博客地址
第二步:创建环境,安装labelme以及相关依赖库
视频教程:视频地址
其中涉及的命令行指令如下,相对于视频中的有修改,第三四行请按照下方为准:
1. conda create --name=labelme python=3.6
2. conda activate labelme
3. pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyqt5
4. pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme
可能出现的报错:
输入命令行第一步,有如下报错:
(base) C:\Users\zjz>conda create --name labelme python=3.6
Collecting package metadata (current_repodata.json): failed
UnavailableInvalidChannel: The channel is not accessible or is invalid.
channel name: simple
channel url: https://pypi.tuna.tsinghua.edu.cn/simple
error code: 404
因为清华源不支持anaconda下载了,然而你的电脑下载源是清华源,为此我们需要恢复默认源,使用如下命令行代码,再输入一次命令行第一行,应该就可以了。
conda config --remove-key channels
第三步:用labeleme做岩石颗粒的边缘标记
教程视频:[视频地址]
其中涉及的操作如下:
- 创建边缘标记:左下角倒数第二个按键→右键选择 create linestrip
- 编辑边缘标记:左下角倒数第一个按键
- 保存:ctrl + s
- 撤销上一步:ctrl + z
注意事项:
- 尽可能的使边缘标记,形成收尾相连的闭环
- 图片边界不需要标记成物体边缘
- 记得随时保存,labelme不太稳定,容易崩
- 标记时, 仅需对单一图片进行主观的边缘判断,进行标记,不需要参考其它图片对比判断是否为边缘。
- 保存文件命名格式说明:(岩石编号+文件夹编号+文件名)
如:139号岩石1号60.jpg图片标注保存命名为139_01_60.json
第四步:json文件转换成png标签或voc格式的数据集
- 使用labelme在命令行将json文件转化为dataset
1.activate TF2.1-gpu
2.cd C:\Users\zjz\Desktop(程序所在目录)
3.labelme_json_to_dataset 1.json(程序名)
- 使用labelme在命令行导出数据集voc数据集
1.activate TF2.1-gpu
2.cd C:\Users\zjz\Desktop\labelme-master\examples\semantic_segmentation (程序在的目录)
3.python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
其中label.txt文件内容必须包括以下前两行,否则报错:

最终输出data_dataset_voc文件夹:
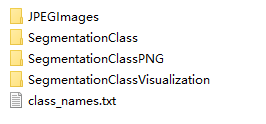
可能出现的报错:
Traceback (most recent call last):
File "labelme2voc.py", line 105, in <module>
main()
File "labelme2voc.py", line 64, in main
label_file = labelme.LabelFile(filename=filename)
File "E:\Anaconda\envs\TF2.1-gpu\lib\site-packages\labelme\label_file.py", line 31, in __init__
self.load(filename)
File "E:\Anaconda\envs\TF2.1-gpu\lib\site-packages\labelme\label_file.py", line 121, in load
raise LabelFileError(e)
labelme.label_file.LabelFileError: 'gbk' codec can't decode byte 0xb9 in position 50170: illegal multibyte sequence
原因是json文件有中文,无法编译:

解决方法:txt打开,删除中文,留下文件名即可:
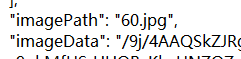















 4190
4190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









