







文章目录
一、引言:像素级分类v.s.掩膜分类:
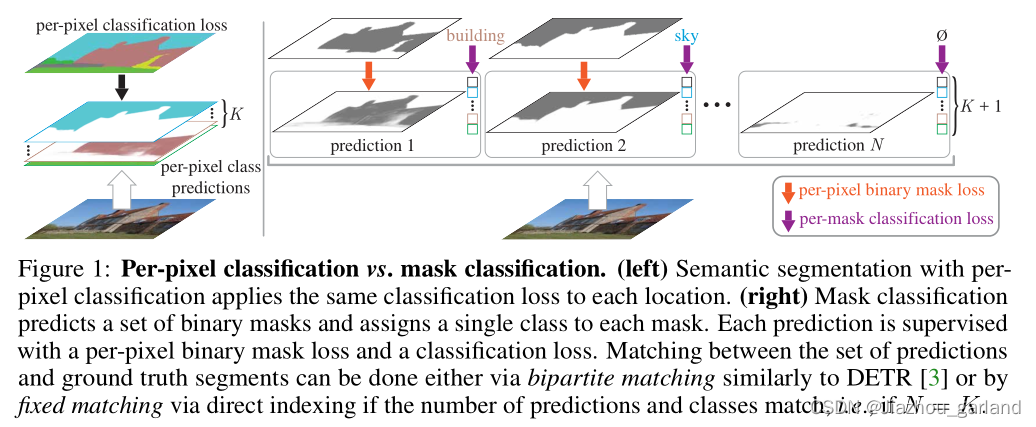
分割领域有两个大框架,一方面是像素级分类(per-pixel classification)统治语义分割领域,另一方面是以Mask-FCN为首的掩膜分类(mask classification)统治实例分割、全景分割领域。
像素级分类(per-pixel classification):分类损失应用于每个输出像素,将预测图像划分为不同类别的区域;
掩膜分类(mask classification):基于mask的方法不对每个像素进行分类,而是预测一组二进制掩码,每个掩预测一个单一的类别。
二、论文概述
参考资料:作者知乎亲自写的简介、《MaskFormer:使用Mask分类实现语义分割》
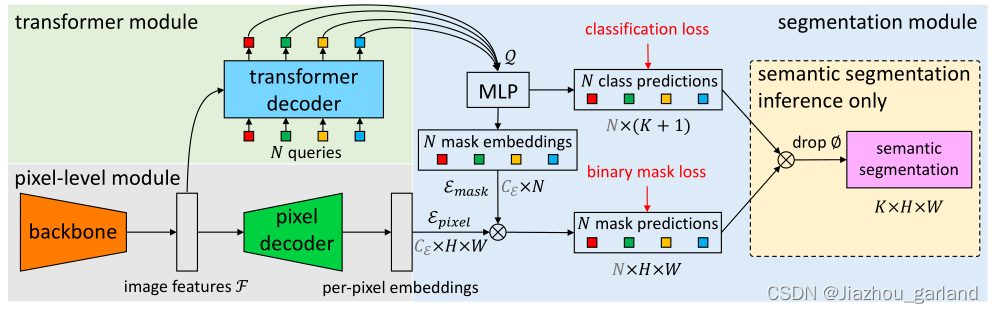
MaskFormer的结构如上图所示,主要可以分为三个部分:
- pixel-level module:用来提取每个像素embedding(灰色背景部分)
- transformer module:用来计算N个segment的embedding(绿色背景部分)
- segmentation module:根据上面的per-pixel embedding和per-segment embedding,生成预测结果。(蓝色背景部分)
三、代码实现
pixel-level module
基于pytorch的Swim Transformer代码实现与讲解
Swin Transformer中的mask机制
transformer module
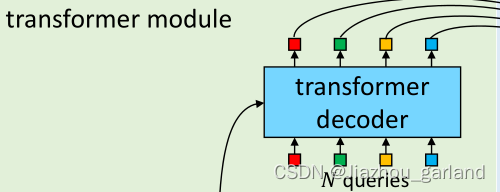
这一部分从torch.nn.Transformer复制粘贴,具体实现在此, 位置编码实现在此,并进行以下修改:
- 在MultiheadAttention中使用位置编码
- 删除了编码器末尾的额外LN
- 解码器返回所有解码层的激活后的特征
即实现了下图所示部分:
参数细节:

segmentation module
- 分类
即实现下图所示部分:
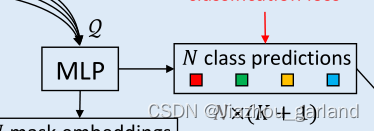
在看了源代码之后,怀疑这里图画错了,分类这里直接用的transformer module产出特征图,并没有过MLP。
鉴于自己水平不高,另有高见的朋友麻烦告诉我一下。
# hs是transformer module出来的特征,维度大小是[batche_size, queries, embed]
if self.mask_classification 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4219
4219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









