







根据书中内容,深度学习都在Jupyter notebook中进行。第一步,下载anaconda,打开anaconda prompt,建立新的虚拟环境,配置虚拟环境。在新建好的虚拟环境中安装keras,可以使用pip进行下载,并下载常用的包。
安装好后,在notebook中输入:
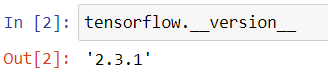
成功输出这样的结果,说明keras安装没问题,可以进行下面的演示。
第二章 MBIST数据集——手写数字辨识问题
from keras.datasets import mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()#加载数据集
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10,activation='softmax'))
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
train_images = train_images.reshape((60000,28*28))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000,28*28))
test_images = test_images.astype('float32')/255
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
network.fit(train_images,train_labels,epochs=5,batch_size=128)结果展示:
Epoch 1/5 60000/60000 [==============================] - 5s 88us/step - loss: 0.2552 - accuracy: 0.9267 Epoch 2/5 60000/60000 [==============================] - 3s 54us/step - loss: 0.1030 - accuracy: 0.9693 Epoch 3/5 60000/60000 [==============================] - 3s 53us/step - loss: 0.0681 - accuracy: 0.9797 Epoch 4/5 60000/60000 [==============================] - 4s 59us/step - loss: 0.0495 - accuracy: 0.9856 Epoch 5/5 60000/60000 [==============================] - 3s 54us/step - loss: 0.0378 - accuracy: 0.9884
查看精确度:
test_loss,test_acc = network.evaluate(test_images,test_labels)
print('test_acc:',test_acc)结果: 10000/10000 [==============================] - 0s 29us/step test_acc: 0.9819999933242798
3.4 电影评论分类:二分类问题
- 使用数据集IMDB
# 加载数据 包括训练数据和测试数据(方法为:.load_data)
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# 准备数据
# 将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
y_train = np.asarray((train_labels).astype('float32'))
y_test = np.asarray(test_labels).astype('float32')
# 构建网络
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#使用sigmoid函数是因为这是一个二分类问题,我们要输出一个概率才能确定被分类项目的所属区域
# 编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 配置优化器和损失指标
from keras import optimizers
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
#留出验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000] #y是标签
partial_y_train = y_train[10000:]
#训练
history = model.fit(partial_x_train, #训练数据集
partial_y_train, #训练数据的标签集
epochs=20, #训练轮数
batch_size=512, #批量大小
validation_data=(x_val, y_val)
)
结果:
Train on 15000 samples, validate on 10000 samples Epoch 1/20 15000/15000 [==============================] - 6s 425us/step - loss: 0.5300 - binary_accuracy: 0.7835 - val_loss: 0.4105 - val_binary_accuracy: 0.8661 Epoch 2/20 15000/15000 [==============================] - 2s 154us/step - loss: 0.3322 - binary_accuracy: 0.8984 - val_loss: 0.3207 - val_binary_accuracy: 0.8855 Epoch 3/20 15000/15000 [==============================] - 2s 123us/step - loss: 0.2423 - binary_accuracy: 0.9228 - val_loss: 0.2857 - val_binary_accuracy: 0.8892 Epoch 4/20 15000/15000 [==============================] - 2s 123us/step - loss: 0.1892 - binary_accuracy: 0.9410 - val_loss: 0.2840 - val_binary_accuracy: 0.8864 Epoch 5/20 15000/15000 [==============================] - 2s 119us/step - loss: 0.1551 - binary_accuracy: 0.9505 - val_loss: 0.2766 - val_binary_accuracy: 0.8904 Epoch 6/20 15000/15000 [==============================] - 2s 126us/step - loss: 0.1264 - binary_accuracy: 0.9615 - val_loss: 0.2879 - val_binary_accuracy: 0.8877 Epoch 7/20 15000/15000 [==============================] - 2s 128us/step - loss: 0.1041 - binary_accuracy: 0.9691 - val_loss: 0.3458 - val_binary_accuracy: 0.8710 Epoch 8/20 15000/15000 [==============================] - 2s 121us/step - loss: 0.0868 - binary_accuracy: 0.9751 - val_loss: 0.3144 - val_binary_accuracy: 0.8853 Epoch 9/20 15000/15000 [==============================] - 2s 121us/step - loss: 0.0688 - binary_accuracy: 0.9829 - val_loss: 0.3367 - val_binary_accuracy: 0.8807 Epoch 10/20 15000/15000 [==============================] - 2s 120us/step - loss: 0.0585 - binary_accuracy: 0.9846 - val_loss: 0.3752 - val_binary_accuracy: 0.8780 Epoch 11/20 15000/15000 [==============================] - 2s 119us/step - loss: 0.0457 - binary_accuracy: 0.9896 - val_loss: 0.3863 - val_binary_accuracy: 0.8750 Epoch 12/20 15000/15000 [==============================] - 2s 120us/step - loss: 0.0351 - binary_accuracy: 0.9941 - val_loss: 0.4153 - val_binary_accuracy: 0.8747 Epoch 13/20 15000/15000 [==============================] - 2s 123us/step - loss: 0.0310 - binary_accuracy: 0.9939 - val_loss: 0.4423 - val_binary_accuracy: 0.8746 Epoch 14/20 15000/15000 [==============================] - 2s 128us/step - loss: 0.0200 - binary_accuracy: 0.9970 - val_loss: 0.4754 - val_binary_accuracy: 0.8727 Epoch 15/20 15000/15000 [==============================] - 2s 124us/step - loss: 0.0165 - binary_accuracy: 0.9978 - val_loss: 0.5315 - val_binary_accuracy: 0.8682 Epoch 16/20 15000/15000 [==============================] - 2s 120us/step - loss: 0.0135 - binary_accuracy: 0.9977 - val_loss: 0.5453 - val_binary_accuracy: 0.8713 Epoch 17/20 15000/15000 [==============================] - 2s 121us/step - loss: 0.0075 - binary_accuracy: 0.9995 - val_loss: 0.5868 - val_binary_accuracy: 0.8665 Epoch 18/20 15000/15000 [==============================] - 2s 120us/step - loss: 0.0074 - binary_accuracy: 0.9991 - val_loss: 0.6202 - val_binary_accuracy: 0.8679 Epoch 19/20 15000/15000 [==============================] - 2s 119us/step - loss: 0.0039 - binary_accuracy: 0.9999 - val_loss: 0.6841 - val_binary_accuracy: 0.8619 Epoch 20/20 15000/15000 [==============================] - 2s 123us/step - loss: 0.0062 - binary_accuracy: 0.9991 - val_loss: 0.6967 - val_binary_accuracy: 0.8669
#绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values)+1)
plt.plot(epochs,loss_values,'bo',label='Training loss')
plt.plot(epochs,val_loss_values,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()绘制结果:

#绘制训练精度和验证精度图像
plt.clf()
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()绘制结果:

更改模型参数,重新进行训练:
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=6, batch_size=512)
result=model.evaluate(x_test, y_test)
输入result CTRL+ENTER 得出新模型的训练结果如下:
[0.34086217663764956, 0.8745599985122681] 总结: ① 有时候我们会对原始数据进行预处理,单词序列可以编码为二进制向量,但是也有其他的编码方式 ② 二分类问题通常使用sigmoid函数作为Dense层的最后一层,将标量输出为概率。 ③ 对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy作为损失函数 ④ rmsprop是最经常使用的优化器 ⑤ 并不是epochs越大越好,有时候会产生过拟合现象
新闻分类:多分类问题
- 使用reuters数据集
#加载数据集 此数据集也是KERAS中的数据集 直接从keras上下载 代码如下: from keras.datasets import reuters (train_data, train_labels),(test_data, test_labels) = reuters.load_data(num_words=10000) #数据处理:标签向量化 import numpy as np def vectorize_sequences(sequences,dimension=10000): results = np.zeros((len(sequences),dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) # from keras.utils.np_utils import to_categorical # one_hot_train_labels = to_categorical(train_labels) # one_hot_test_labels = to_categorical(test_labels)# one-hot编码 def to_one_hot(labels,dimension=46): results = np.zeros((len(labels),dimension)) for i, label in enumerate(labels): results[i, label] = 1. return results one_hot_train_labels = to_one_hot(train_labels) one_hot_test_labels = to_one_hot(test_labels) from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val)) #绘制训练和验证曲线 import matplotlib.pyplot as plt history_dict = history.history loss = history_dict['loss'] val_loss = history_dict['val_loss'] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss,'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() #绘制训练精度和验证精度图像 plt.clf() acc = history_dict['accuracy'] val_acc = history_dict['val_accuracy'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show() plt.show()绘制结果:


# 改进
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=9, batch_size=512, validation_data=(x_val, y_val))
result=model.evaluate(x_test, one_hot_test_labels)结果:
Train on 7982 samples, validate on 1000 samples Epoch 1/9 7982/7982 [==============================] - 1s 113us/step - loss: 2.6643 - accuracy: 0.5449 - val_loss: 1.7630 - val_accuracy: 0.6530 Epoch 2/9 7982/7982 [==============================] - 1s 101us/step - loss: 1.4250 - accuracy: 0.7154 - val_loss: 1.3085 - val_accuracy: 0.7210 Epoch 3/9 7982/7982 [==============================] - 1s 105us/step - loss: 1.0503 - accuracy: 0.7751 - val_loss: 1.1494 - val_accuracy: 0.7610 Epoch 4/9 7982/7982 [==============================] - 1s 103us/step - loss: 0.8312 - accuracy: 0.8192 - val_loss: 1.0399 - val_accuracy: 0.7810 Epoch 5/9 7982/7982 [==============================] - 1s 108us/step - loss: 0.6632 - accuracy: 0.8566 - val_loss: 0.9825 - val_accuracy: 0.7860 Epoch 6/9 7982/7982 [==============================] - 1s 110us/step - loss: 0.5308 - accuracy: 0.8850 - val_loss: 0.9421 - val_accuracy: 0.8010 Epoch 7/9 7982/7982 [==============================] - 1s 110us/step - loss: 0.4270 - accuracy: 0.9093 - val_loss: 0.9397 - val_accuracy: 0.8100 Epoch 8/9 7982/7982 [==============================] - 1s 105us/step - loss: 0.3485 - accuracy: 0.9270 - val_loss: 0.9071 - val_accuracy: 0.8190 Epoch 9/9 7982/7982 [==============================] - 1s 109us/step - loss: 0.2864 - accuracy: 0.9369 - val_loss: 0.9001 - val_accuracy: 0.8230 2246/2246 [==============================] - 1s 262us/step
输入result CTRL+ENTER 得出新模型的训练结果如下:
[0.9782243191081291, 0.7871772050857544] ~~总结~~ ① 对N个类别的多分类问题,最后一层Dense层的维度应该是N ② 对于单标签,多分类问题,最后一层使用softmax进行激活,输出概率分布 ③ 损失函数使用分类交叉熵 ④ 标签处理方法:1)one-hot编码,使用categorical_crossentropy作为损失函数 2)将标签编码为整数,然后使用sparse_categorical_crossentropy ⑤ 中间的隐藏层的维度不应该太小,否则将压缩空间使得迅捷结果变差
3.6 房价预测:回归问题
- 使用boston_housing数据集
- 回归问题的输入值 是连续的 不同于前面的离散数据
# 加载数据集 from keras.datasets import boston_housing (train_data,train_labels), (test_data, test_labels) = boston_housing.load_data() # 数据标准化,每个数据减去平均值再除以标准差 mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std #模型定义 from keras import models from keras import layers def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) return model # K折验证 # 一般数据集较小的时候会进行K折验证,以增加数据训练效果 import numpy as np k=4 #这个例子的训练数据只有400多个 所以分成4组 每组100个左右 num_val_samples = len(train_data) // k num_epochs = 100 all_scores = [] for i in range(k): print('processing fold #', i) val_data = train_data[i *num_val_samples: (i+1) * num_val_samples] val_labels = train_labels[i * num_val_samples : (i + 1) * num_val_samples] partial_train_data = np.concatenate( [train_data[:i * num_val_samples], train_data[(i + 1) * num_val_samples:]], axis=0) partial_train_labels = np.concatenate( [train_labels[:i * num_val_samples], train_labels[(i+1) * num_val_samples:]], axis=0) model = build_model() model.fit(partial_train_data,partial_train_labels, epochs=num_epochs, batch_size=1, verbose=0) val_mse,val_mae=model.evaluate(val_data,val_labels, verbose=0) all_scores.append(val_mae) # verbose的作用:参数一共3个,使 0,1,2 # * 参数0:只显示结果 参数1:显示结果和epoch状态 参数2:显示进度条和结果训练结果:
all_scores:
[1.921180248260498, 2.826927661895752, 2.680487871170044, 2.4236154556274414]
np.mean(all_scores):
2.463052809238434
让训练时间更长一点,达到500个轮次。为了记录模在每轮的表现,我们需要修改训练循环,以保存每轮的验证分数记录:
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_labels = train_labels[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_labels = np.concatenate(
[train_labels[:i * num_val_samples],
train_labels[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_labels,
validation_data=(val_data, val_labels),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mae']
all_mae_histories.append(mae_history)
# all_mae_histories中存在了4个数据,但是每个数据中都有500个epoch#计算所有轮次中的K折验证分数的平均值:
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
#绘制验证分数
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
#作用 从曲线看出最佳的epoch是多少绘制结果:

#绘制验证分数(删除前10个数据点)
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point *(1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()绘制结果:

# 训练最终模型
model = build_model()
model.fit(train_data, train_labels,
epochs=60, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_labels)最终结果如下:
>>>test_mae_score
2.69599986076355
* 总结
① 回归问题使用的损失函数与分类问题不一样,回归问题常用的是均方差(MSE)
② 同样,回归问题使用的评估指标也与分类问题不一样。常见的回归指标是平均绝对误差(MAE)
③ 输入数据特征具有不同的取值范围,应该先进行预处理,对每个特征单独进行缩放
④ 可用数据集较小时,K折验证可以可靠的评估模型
⑤ 训练数据很少,最好使用隐藏层比较少的小型网络,以避免严重的过拟合















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









