






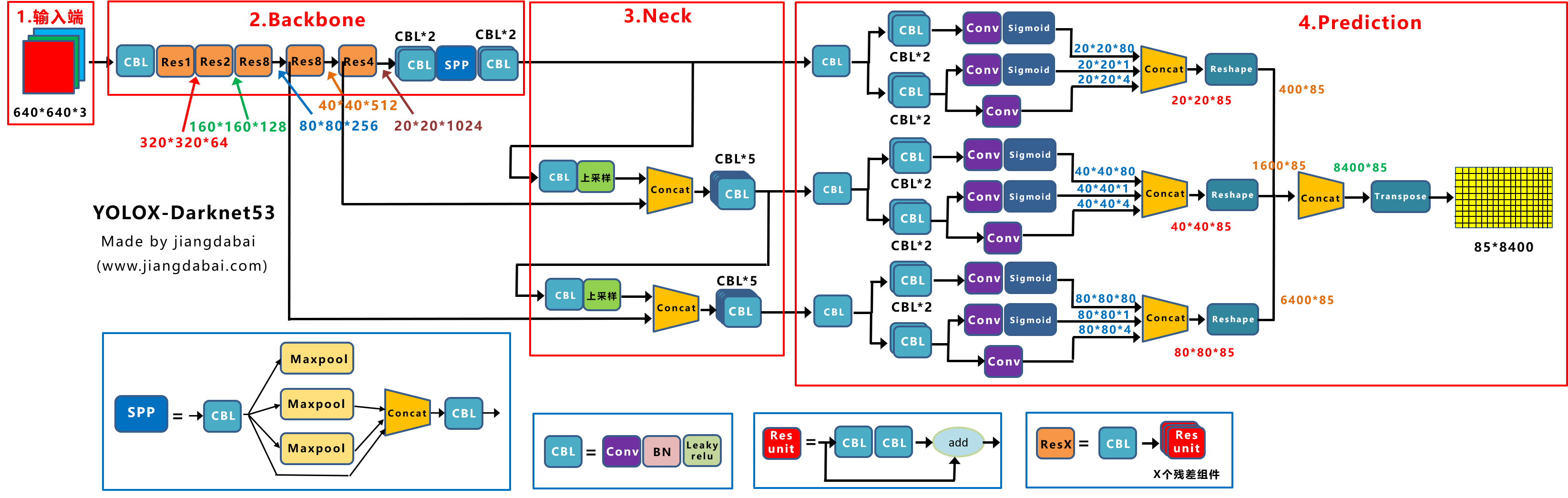
yolox技术要点
1. 数据增强:mosaic+mixup
-
mosaic:随机缩放、随机裁剪、随机排布,4张融合成1张图片
-
mixup:2张图片往外扩到相同size,加权融合(叠加)
注意:在训练的最后15个eopch,关闭数据增强
2. backbone和Neck都与yolov3一样:采用darknet,与FPN
3. **Decoupled Head:**解耦头,将类别、位置信息(x,y,w,h),前背景拆分开
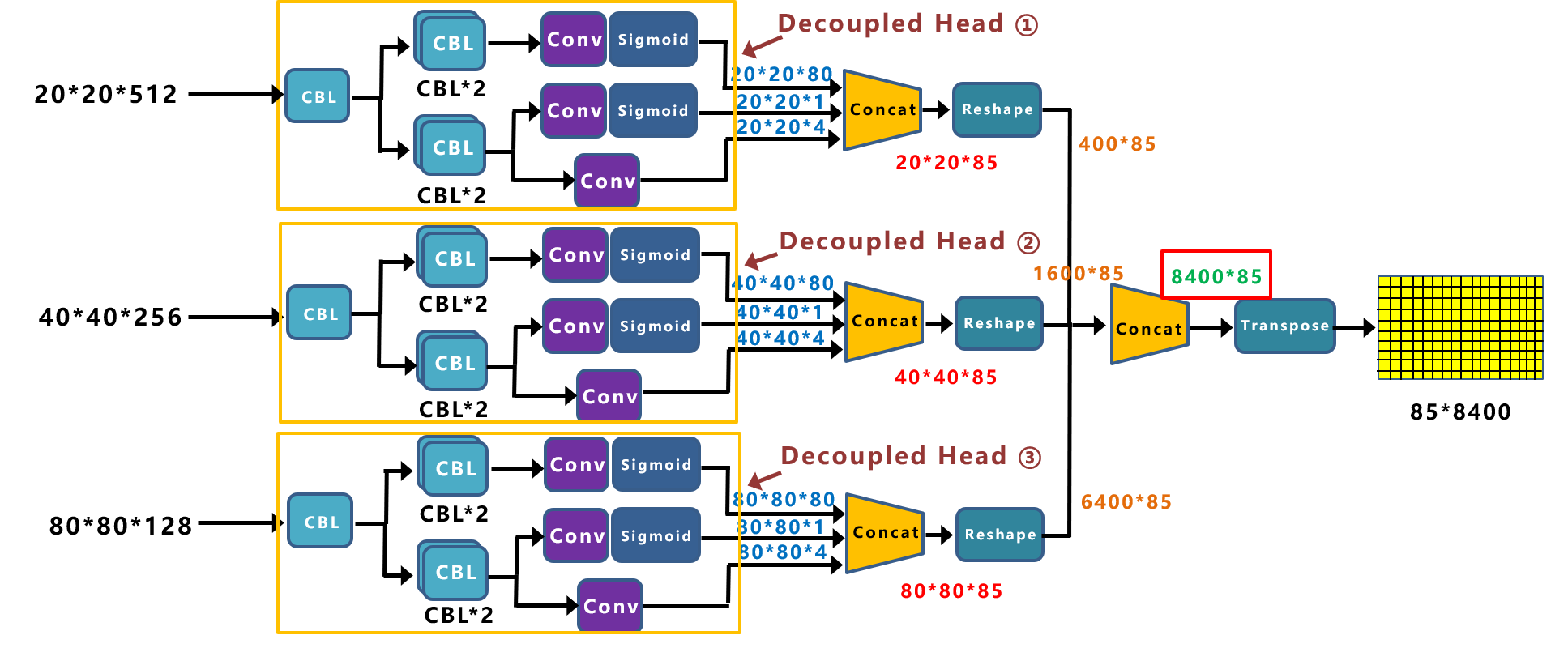
**(1)cls_output:**主要对目标框的类别,预测分数。COCO数据集共80个类别,经过Sigmoid激活函数处理后,变为20*20*80大小。
**(2)obj_output:**主要判断目标框是前景还是背景,因此经过Sigmoid处理好,变为20*20*1大小。
**(3)reg_output:**主要对目标框的坐标信息(x,y,w,h)进行预测,因此大小为20*20*4。
最后三个output,经过Concat融合到一起,得到20*20*85的特征信息。其余2部分同理。最终得到85*400的二维向量。8400代表:框的数量,85代表:类别+位置信息+是否前景
4. Anchor-free与Anchor-base
- Anchor-base:
- 会引入更多需要优化的超参数
- 对于新的检测任务,需要调整anchor
- 需要计算大量anchor的iou,占用较大显存
- Anchor-free
- 比anchor-base计算的参数量少2/3
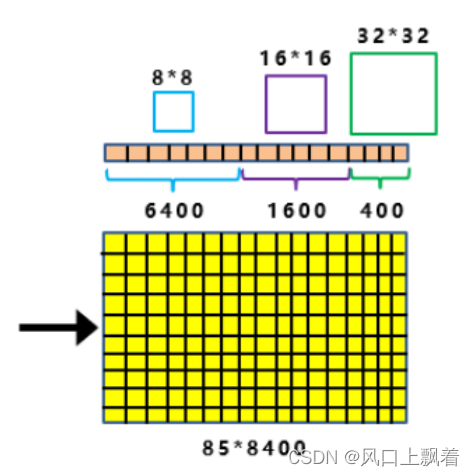
如何将8400个预测框和图片上的目标框关联起来,挑选出正样本锚框,需要使用初步筛选与SimOTA实现标签分配
-
初步筛选(根据中心点判断、根据目标框判断)
满足下面条件之一的通过初步筛选,成为候选框anchor
-
**根据中心点判断:**寻找anchor box中心点,落在gt范围的所有anchors(计算中心点到gt左上、右下的距离,都大于0则为正样本)
-
**根据目标框判断:**以gt中心点为基准,设置边长为5的正方形,挑选锚框中心点在正方形内的所有锚框
-
-
精细化筛选(SimOTA)
-
初筛正样本信息提取
- 上述方法筛选(锚框的中心点里gt左上、右下的距离/中心点是否落在gt内)
-
Loss函数计算
- 位置信息loss:-log(bbx_iou)
- 类别信息loss:cross_entroy(cls_preds=cls*obj, F.ont_hot(tg_classes) )
-
cost成本计算
- cost=Lcls(分类loss) + λLreg(回归loss)
-
simOTA求解
-
设置候选框数量k: 挑选top10的iou作为候选框,然后计算10个iou加权求和取整,得到k。
-
通过cost挑选候选框(cost最小的框):按照维度1挑选k个anchor-box作为正样本
(过滤共用的候选框:重复框选取cost更小的:按照维度0挑选)
-
-

















 9331
9331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









