







1.在Hadoop根目录创建目录
hdfs dfs -mkdir -p /cpm/input2.上传文件到/cpm/input
hdfs dfs -put [文件目录,如./test.txt] /cpm/input/3. 在Hadoop根目录运行Word Count程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount [刚刚上传的文件路径,如/cpm/test.txt] [输出目录,不能是存在的,他自己会自动创建,如/cpm/output]4. 查看运行结果,Windows打开连接查看
http://192.168.43.21:50070/explorer.html#/cpm/output
5.使用命令查看运行结果
hdfs dfs -cat /cpm/output/part-r-000006.输出如下
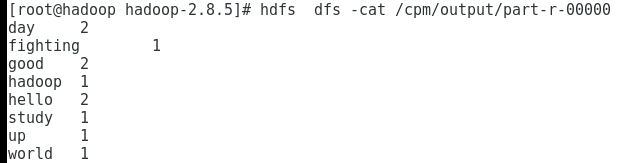
















 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











