







Vision Transformer (ViT) 是一种将 Transformer 架构应用于图像分类任务的模型。它摒弃了传统卷积神经网络 (CNN) 的卷积操作,而是将图像分割成 patches,并将这些 patches 视为序列输入到 Transformer 编码器中。
ViT的处理流程
输入图像被分割成多个固定大小的patch,每个patch经过线性投影变成嵌入向量,然后加上位置编码。接着,这些嵌入向量会和类别标签(class token)拼接在一起,输入到多个Transformer块中。每个Transformer块包含多头自注意力机制和前馈网络,最后用类别标签对应的输出来进行分类。
代码的结构
VIT结构包括:
patch嵌入层、位置编码、Transformer编码器块、多头注意力机制、MLP层,以及最后的分类头
每个Transformer块的结构大致如下:
自注意力层、残差连接(输入加上自注意力的输出)、层归一化、MLP层、残差连接(层归一化后的结果加上MLP的输出)、层归一化
patch嵌入层: PyTorch中需要用卷积层或者unfold方法将图像分割成patch,然后进行展平和线性变换。比如,假设输入图像大小为224x224,patch大小是16x16,那么每个patch是16x16x3(假设是RGB图像),总共有(224/16)^2=14x14=196个patch。每个patch展平后的维度是16 * 16 * 3=768,所以线性投影层的输入是768,输出是某个隐藏维度,比如768(base模型)或者其他大小,视具体模型而定。
位置编码部分: ViT使用的是可学习的位置编码,所以是一个可训练的参数矩阵,形状为(num_patches + 1, hidden_dim),其中加1是因为有class token。位置编码会被加到patch嵌入上,然后输入到Transformer中。
class token: 这个token是一个可学习的向量,会被拼接到patch嵌入序列的前面。因此,整个序列的长度是num_patches + 1。在最后的分类时,使用这个class token对应的输出向量进行分类。
Transformer编码器:由多个块组成。每个块的结构大致是:自注意力→残差连接→层归一化→MLP→残差连接→层归一化。
多头自注意力的实现需要将输入分成多个头,然后分别计算注意力,最后合并结果。
每个头的维度通常是hidden_dim / num_heads。例如,如果hidden_dim是768,num_heads是12,那么每个头的维度是64。
MLP部分通常是两个全连接层,中间有一个激活函数(如GELU),第一个层的输出维度是hidden_dim的4倍,第二个层再投影回hidden_dim。例如,hidden_dim=768的话,中间层是3072维。
一、ViT 模型架构
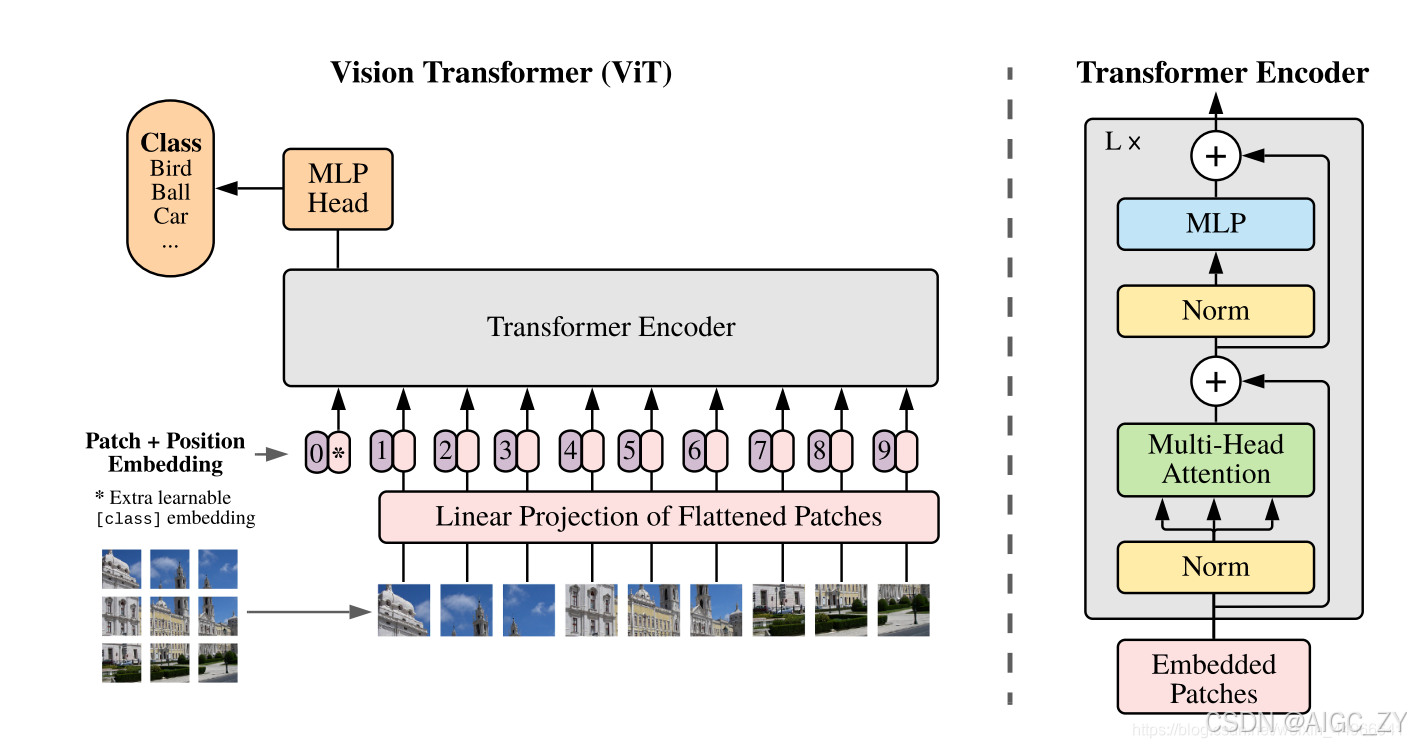
1. 图像分块与嵌入 (Patch Embedding)
- 输入图像 (H×W×C) 分割为 N 个大小为 P×P 的小块,每个块展平后维度为 P²C。
- 通过线性投影(全连接层或卷积)将每个块映射到 D 维嵌入空间,输出维度为 N×D。
- 示例:224×224 图像分割为 16×16 块,得到 N=(224/16)²=196 个块,D=768 时输出为 196×768。
2. 类别标记与位置编码 (Class Token & Position Embedding)
- 类别标记 (cls_token):可学习的向量 (1×D),与图像块嵌入拼接,用于最终分类。
- 位置编码:可学习的参数 (N+1×D),与嵌入相加以保留位置信息。
3. Transformer 编码器
- 由多个 Transformer Encoder 层堆叠而成
- 多头自注意力 (Multi-Head Self-Attention):并行多个注意力头,捕获全局依赖。
- 前馈网络 (Feed-Forward Network):两层全连接,中间激活函数为 GELU,对每个 patch 的特征进行非线性变换。
- 层归一化 (LayerNorm) 与残差连接:提升训练稳定性。
4. 分类头
- 将 Transformer Encoder 输出的 [CLS] token 的特征向量映射到类别概率分布。
二. PyTorch 代码实现
以下是一个简化版的 ViT 模型的 PyTorch 实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, E, H/P, W/P)
x = x.flatten(2) # (B, E, N)
x = x.transpose(1, 2) # (B, N, E)
return x
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, N, E = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, E)
x = self.proj(x)
return x
class FeedForward(nn.Module):
def __init__(self, embed_dim, hidden_dim):
super().__init__()
self.net = nn.SSequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, embed_dim),
)
def forward(self, x):
return self.net(x)
class TransformerEncoderLayer(nn.Module):
def __init__(self, embed_dim, num_heads, hidden_dim):
super().__init__()
self.attn = MultiHeadAttention(embed_dim, num_heads)
self.ffn = FeedForward(embed_dim, hidden_dim)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, hidden_dim=3072):
super().__init__()
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)
self.pos_embed = nn.Parameter(torch.zeros(1, self.patch_embed.num_patches + 1, embed_dim))
self.encoder = nn.Sequential(*[TransformerEncoderLayer(embed_dim, num_heads, hidden_dim) for _ in range(depth)])
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, num_classes),
)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_token = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_token, x), dim=1)
x = x + self.pos_embed
x = self.encoder(x)
x = x[:, 0]
x = self.mlp_head(x)
return x
# Example usage
model = VisionTransformer()
x = torch.randn(1, 3, 224, 224)
y = model(x)
print(y.shape) # torch.Size([1, 1000])
四. 代码解析
PatchEmbedding: 将图像分割成 patches 并进行线性投影。
MultiHeadAttention: 实现多头自注意力机制。
FeedForward: 实现前馈神经网络。
TransformerEncoderLayer: 包含一个多头自注意力层和一个前馈神经网络层。
VisionTransformer: 整合所有模块,构建完整的 ViT 模型。
常见问题:
为什么使用正余弦函数计算位置编码?
- 这种编码方式的好处在于,它能够为不同的位置生成唯一的编码,并且具有平滑性和周期性。通过这种方式,模型可以利用位置编码中的相对位置关系。
- 由于正弦和余弦函数的性质,模型可以通过简单的线性变换来捕捉到位置之间的相对关系。例如,两个位置之间的距离可以通过它们的编码向量之间的差异来表示。
为什么在进行多头注意力的时候需要对每个head进行降维?
- 降低特征学习的难度:在经过维度的“分割”之后,在多个低维空间相比原有的高维空间,能降低特征学习的难度。
- 不增加时间复杂度:在不增加时间复杂度的前提下,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。
- 并行计算:通过降维,可以在多个低维空间并行计算,提高计算效率。
多头注意力:
多头自注意力通过并行处理多个注意力头来增强模型对不同上下文信息的捕捉能力。自注意力机制关注序列内部的相互作用,而多头注意力机制则在此基础上进一步丰富了模型的表达能力,使其能够同时关注来自不同子空间的信息。
作者:grooter
链接:https://zhuanlan.zhihu.com/p/8592744288
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
参考文献:
Vision Transformer(ViT)PyTorch代码全解析(附图解)
28、Vision Transformer(ViT)模型原理及PyTorch逐行实现
11.2 使用pytorch搭建Vision Transformer(vit)模型
手把手带你从零推导旋转位置编码RoPE

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









