







一、模型结构
ViT结构主要包括Patch Embedding、Position Embedding(位置编码)、Transformer Encoder与MLP Head。
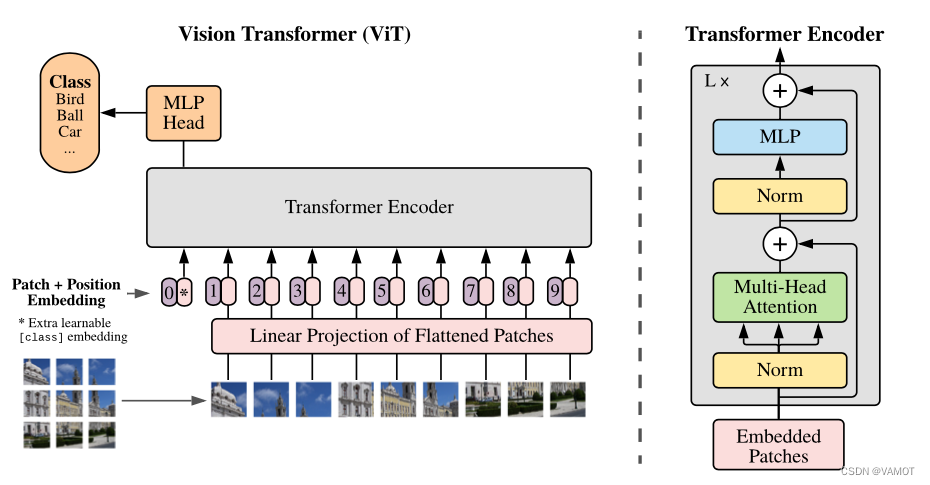
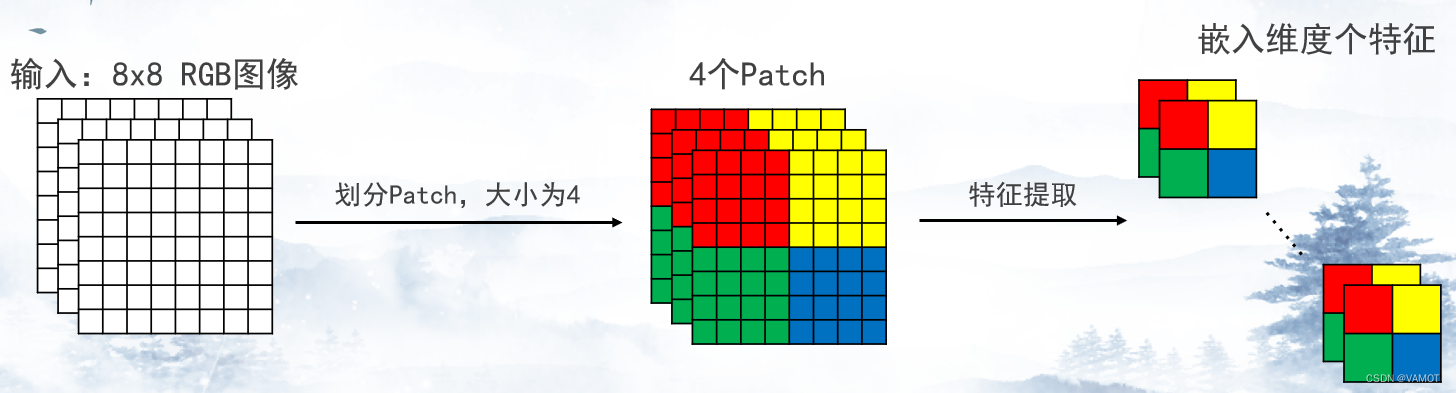
二、Patch Embedding
- 根据Patch大小,将图像分割成多个Patch。
- Patch的数量:图像的高整除Patch大小,再乘以图像的宽整除Patch大小。(H//patch_size)*(W// patch_size)
- 从每个Patch提取嵌入维度个特征。
- 使用卷积层实现,通常卷积核大小和步长均为Patch大小。
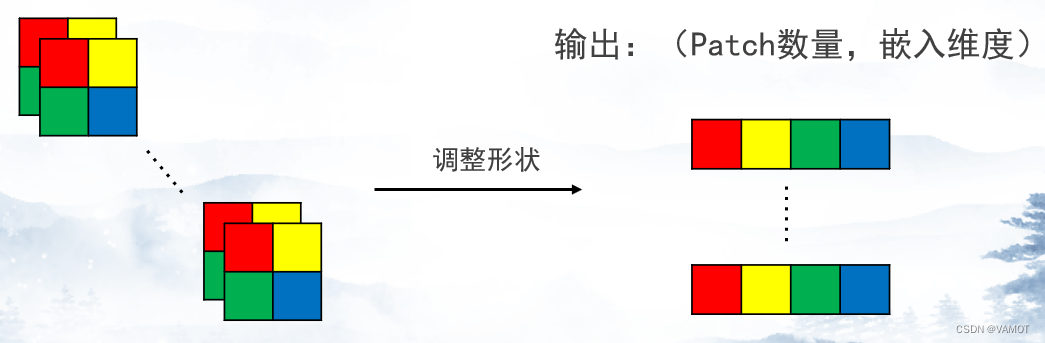
class PatchEmbedding(nn.Module):
def __init__(self, patch_size: int = 16, embedding_dim: int = 768):
super(PatchEmbedding, self).__init__()
self.patch_size = patch_size
self.embedding_dim = embedding_dim
self.cov2d = nn.Conv2d(3, embedding_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
"""
:param x: (B, C, H, W)
:return: (B, seq_len, C)
"""
o = self.cov2d(x)
o = o.reshape(o.shape[0], self.embedding_dim, -1)
o = o.permute(0, 2, 1)
return o三、[class] Embedding
本质上是一个可训练的Token,其维度等于嵌入维度。
初始化:
self.cls_token = nn.Parameter(torch.zeros(1, 1, embedding_dim))扩展与拼接 :
batch_cls_token = self.cls_token.expand(o.shape[0], -1, -1)
o = torch.cat([batch_cls_token, o], dim=1)四、位置编码
该位置编码使用标准的可学习的一维位置编码,其长度等于Patch数量加1(class token)。
seq_length = (image_size // patch_size) ** 2 + 1
self.pos_embedding = nn.Parameter(torch.empty(1, seq_length, embedding_dim))五、Transformer Encoder
- 可以粗略划分为注意力部分与MLP部分。
- 注意力部分主要包括Layer Normalisation、Multi-Head Attention与残差链接。
- MLP部分主要包括Layer Normalisation、MLP与残差链接。
- MLP包括两个线性层,使用GELU作为激活函数。
- 适当加入dropout层以提升泛化能力。
class Encoder(nn.Module):
def __init__(self, num_heads: int = 12, embedding_dim: int = 768, mlp_dim: int = 3072,
dropout: float = 0, attention_dropout: float = 0):
super(Encoder, self).__init__()
self.num_heads = num_heads
# MSA
self.norm1 = nn.LayerNorm(embedding_dim)
self.attention = nn.MultiheadAttention(embedding_dim, num_heads,
dropout=attention_dropout, batch_first=True)
self.dropout = nn.Dropout(dropout)
# MLP
self.norm2 = nn.LayerNorm(embedding_dim)
self.linear1 = nn.Linear(embedding_dim, mlp_dim)
self.gelu = nn.GELU()
self.dropout1 = nn.Dropout(dropout)
self.linear2 = nn.Linear(mlp_dim, embedding_dim)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x):
"""
:param x: (B, seq_len, C)
:return: (B, seq_len, C)
"""
o = self.norm1(x)
o, _ = self.attention(o, o, o, need_weights=False)
o = self.dropout(o)
o = o + x
y = self.norm2(o)
y = self.linear1(y)
y = self.gelu(y)
y = self.dropout1(y)
y = self.linear2(y)
y = self.dropout2(y)
return y + o六、MLP Head
预训练时使用的头部:
def pretrain(self, pretrain_dim):
self.head = nn.Sequential(nn.Linear(self.embedding_dim, pretrain_dim),
nn.Tanh(),
nn.Linear(pretrain_dim, self.num_classes))精调时使用的头部:
def finetune(self):
self.head = nn.Linear(self.embedding_dim, self.num_classes)七、ViT模型代码
class ViT(nn.Module):
def __init__(self, image_size: int, num_classes: int, pretrain_dim: int,
patch_size: int = 16, num_layers: int = 12, num_heads: int = 12,
embedding_dim: int = 768, mlp_dim: int = 3072, dropout: float = 0.0,
attention_dropout: float = 0.0):
super(ViT, self).__init__()
self.embedding_dim = embedding_dim
self.num_classes = num_classes
# patch embedding
self.patch_embedding = PatchEmbedding(patch_size, embedding_dim)
# learnable class token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embedding_dim))
# stand learnable 1-d position embedding
seq_length = (image_size // patch_size) ** 2 + 1
self.pos_embedding = nn.Parameter(torch.empty(1, seq_length, embedding_dim))
# encoders
self.encoders = nn.Sequential()
for _ in range(num_layers):
self.encoders.append(Encoder(num_heads, embedding_dim, mlp_dim, dropout, attention_dropout))
# pretrain head
self.head = nn.Sequential(nn.Linear(embedding_dim, pretrain_dim),
nn.Tanh(),
nn.Linear(pretrain_dim, num_classes))
def forward(self, x):
o = self.patch_embedding(x)
batch_cls_token = self.cls_token.expand(o.shape[0], -1, -1)
o = torch.cat([batch_cls_token, o], dim=1)
o = o + self.pos_embedding
o = self.encoders(o)
o = o[:, 0]
o = self.head(o)
return o
def pretrain(self, pretrain_dim):
self.head = nn.Sequential(nn.Linear(self.embedding_dim, pretrain_dim),
nn.Tanh(),
nn.Linear(pretrain_dim, self.num_classes))
def finetune(self):
self.head = nn.Linear(self.embedding_dim, self.num_classes)八、文献
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
















 5324
5324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











