







一、知识点梳理
GPU线程调度是一个黑盒,我们无法得知其中到底发生了什么,所以CUDA为每个系统函数提供了一个返回值,我们只需要定义专有变量接收函数返回值并对照文档对各个返回值的定义进行输出,就能快速获知到问题的发生的现场在哪。另外,CUDA提供"事件(event)"机制,通过简单的函数调用,就可以监测CUDA程序的时间性能。并且,CUDA可以利用独特的共享储存单元优化应用。
二、实验例程
1.错误检测
//错误码变量类型
cudaError_t error_code;示例代码
//检测函数示例
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)在使用中,只需像如下这样就可以判断了。
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));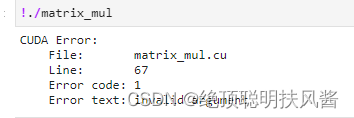
就像这样
2.监测时间性能
CPU程序使用CPU自身的定时器来监测程序时间性能,而这种方式并不适用于GPU,但是GPU可以利用自身的时间戳来监测程序时间性能。
/*******Event相关的函数********/
//声明
cudaEvent_t event;
//创建
cudaError_t cudaEventCreate(cudaEvent_t* event);
//销毁
cudaError_t cudaEventDestroy(cudaEvent_t* event);
//添加事件到当前执行流
cudaError_t cudaEventRecord(cudaEvent_t event,cudaStream_t stream = 0);
//等待事件完成,设立flag
cudaError_t cudaEventSynchronize(cudaEvent_t event); //阻塞
cudaError_t cudaEventQuery (cudaEvent_t event); //非阻塞
//记录执行的事件
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start,cudaEvent_t stop);示例代码
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
cudaMallocHost((void **) &h_a, sizeof(int)*m*n);
cudaMallocHost((void **) &h_b, sizeof(int)*n*k);
cudaMallocHost((void **) &h_c, sizeof(int)*m*k);
cudaMallocHost((void **) &h_cc, sizeof(int)*m*k);
cudaEvent_t start,stop; //声明event
cudaEventCreate(&start); //创建event
cudaEventCreate(&stop);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_c, sizeof(int)*m*k);
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
//添加事件到当前执行流
cudaEventRecord(start);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
cudaEventRecord(stop);
//等待事件完成,设立flag
cudaEventSynchronize(stop);
//记录时间
float timeout;
cudaEventElapsedTime(&timeout,start,stop);
printf("Timeout is %g ms,\n",timeout);
//销毁event
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
//cudaThreadSynchronize(&timeout,start,stop);
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
}利用共享储存单元优化应用
CUDA硬件划分了多种储存单元,按照读取速度由高到低分别为,Register file,Shared Memory,Constant Memory,Texture Memory,Local Memory and Global Memory。在这里我们用到Shared Memory,所以只着重说一下这个。
Shared Memory访问速度仅次于Register file,并且Shared Memory是最快的可以让多个线程沟通的地方,所以线程对Shared Memory的访问就很频繁,为了提升效率,CUDA将Shared Memory分为32个(逻辑块)banks。
同常量内存一样,当一个warp中的所有线程访问同一地址的共享内存是,会触发广播(broadcast)机制到warp中所有线程,这是最高效的,例如:

如果同一个half-warp/warp中的线程访问同一个bank中的不同地址是将发生bank conflict,例如:
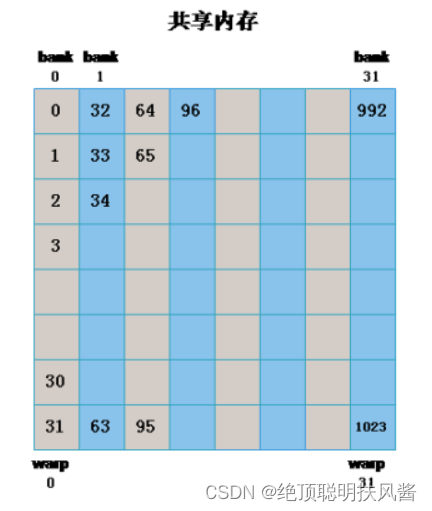
我们要在代码的编写中避免bank conflict的产生。
//Shared Memory申请关键字
__shared__ int sm[SIZE][SIZE];大家应该注意到,Shared Memory是有大小的,他的宽度一般为32bit,所以,可能不能覆盖到全部数据,所以,在实际计算中,Shared Memory,是会“滑动”的。例如:
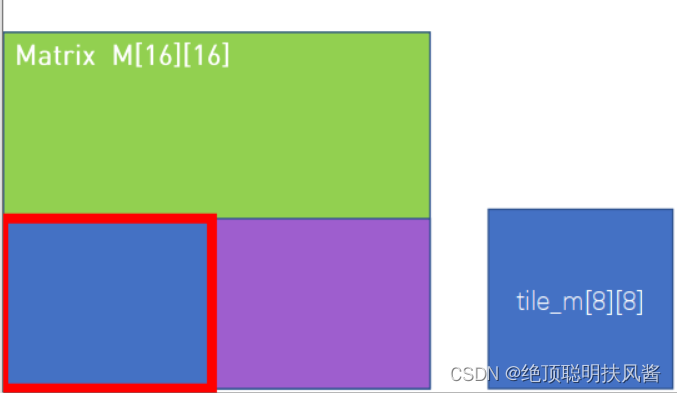
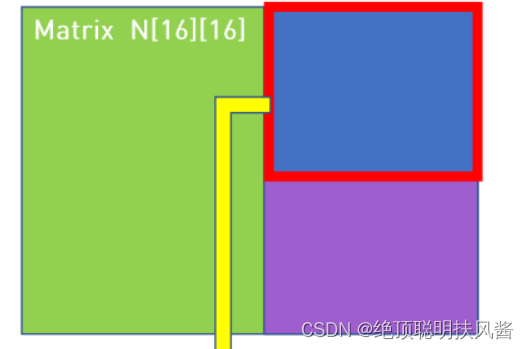
在两个16x16的矩阵M,N中,分别设置一块8x8的Shared Memory,这两块共享内存在调用的时候会将16x16的矩阵分为4块,以“滑动”的方式分别计算。
使用共享内存会对程序的时间性能有一定的提升,下面举例说明:
//未使用共享内存的代码
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
cudaMallocHost((void **) &h_a, sizeof(int)*m*n);
cudaMallocHost((void **) &h_b, sizeof(int)*n*k);
cudaMallocHost((void **) &h_c, sizeof(int)*m*k);
cudaMallocHost((void **) &h_cc, sizeof(int)*m*k);
cudaEvent_t start,stop; //声明event
cudaEventCreate(&start); //创建event
cudaEventCreate(&stop);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_c, sizeof(int)*m*k);
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
//添加事件到当前执行流
cudaEventRecord(start);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
cudaEventRecord(stop);
//等待事件完成,设立flag
cudaEventSynchronize(stop);
//记录时间
float timeout;
cudaEventElapsedTime(&timeout,start,stop);
printf("Timeout is %g ms,\n",timeout);
//销毁event
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
//cudaThreadSynchronize(&timeout,start,stop);
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
}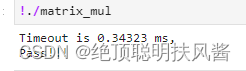
未使用共享内存时,程序所用时间
//使用共享内存的代码
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub)
{
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
cudaMallocHost((void **) &h_a, sizeof(int)*m*n);
cudaMallocHost((void **) &h_b, sizeof(int)*n*k);
cudaMallocHost((void **) &h_c, sizeof(int)*m*k);
cudaMallocHost((void **) &h_cc, sizeof(int)*m*k);
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_c, sizeof(int)*m*k);
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
cudaEventRecord(start);
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float timeout;
cudaEventElapsedTime(&timeout,start,stop);
printf("Timeout is %g ms,\n",timeout);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
//cudaThreadSynchronize(&timeout,start,stop);
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
}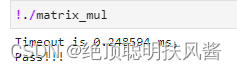
使用共享内存时,程序所用时间
可以看到,在这里使用共享内存使程序获得了大约 30%的提升,这是从GPU储存单元的角度对程序优化的手段。
三.总结
CUDA已经提供了很成熟的框架,在这个框架内,我们可以使用的工具很多,这也大大降低了代码编写的难度,时间就可以放在思路理解上。















 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









