







一、知识梳理
CPU内存和GPU显存是两个独立的空间,两个空间的变量想交互(例如赋值)的话,就需要使用特定的函数传输,一个程序通常需要很多次的数据传输,所以数据传输产生的性能开销不容小觑,所以CUDA推出“统一内存”机制,简化数据传输操作。
二、实验例程
统一内存 的声明方法
关键字 __managed__
或
函数调用
cudaError_t cudaMallocManaged(void **devPtr,size_t size,unsigned int flag=0)对比
//不使用统一内存
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub)
{
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
cudaMallocHost((void **) &h_a, sizeof(int)*m*n);
cudaMallocHost((void **) &h_b, sizeof(int)*n*k);
cudaMallocHost((void **) &h_c, sizeof(int)*m*k);
cudaMallocHost((void **) &h_cc, sizeof(int)*m*k);
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_c, sizeof(int)*m*k);
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
cudaEventRecord(start);
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float timeout;
cudaEventElapsedTime(&timeout,start,stop);
printf("Timeout is %g ms,\n",timeout);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
//cudaThreadSynchronize(&timeout,start,stop);
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
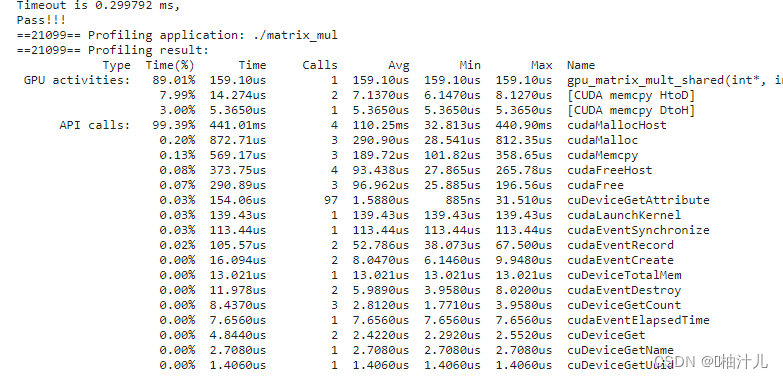
}
//使用统一内存
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
__managed__ int a[1000 * 1000];
__managed__ int b[1000 * 1000];
__managed__ int c_gpu[1000 * 1000];
__managed__ int c_cpu[1000 * 1000];
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k)
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub)
{
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k)
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads();
}
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
a[i * n + j] = 0*rand() % 1024+1;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
b[i * k + j] = 0 * rand() % 1024 +1;
}
}
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
cudaEventRecord(start);
gpu_matrix_mult_shared << <dimGrid, dimBlock >> > (a, b, c_gpu, m, n, k);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float timeout;
cudaEventElapsedTime(&timeout,start,stop);
printf("Timeout is %g ms,\n",timeout);
cudaEventDestroy(start);
cudaEventDestroy(stop);
//cudaThreadSynchronize(&timeout,start,stop);
cpu_matrix_mult(a, b, c_cpu, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
//printf("GPU: % d; CPU: %d; ", h_c[i * k + j], h_cc[i * k + j]);
if (fabs(c_gpu[i * k + j] - c_cpu[i * k + j]) > (1.0e-10))
{
ok = 0;
}
//printf("\n");
}
}
if (ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
return 0;
}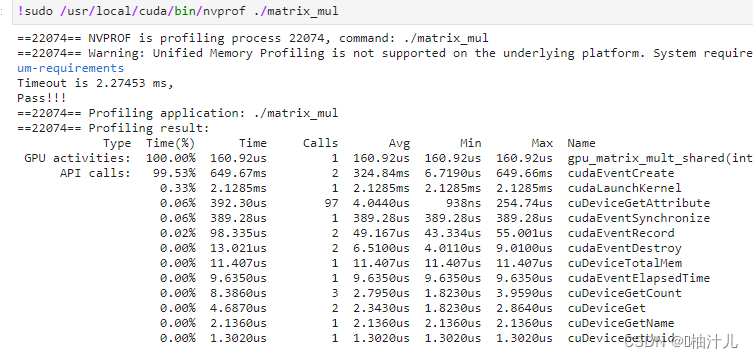
可以看到数据传输的部分 [CUDA memcpy HtoD] 和 [CUDA memcpy DtoH] 不见了,CPU部分的函数和GPU部分的函数使用的是同一个变量。
三、总结
应该注意到的是,虽然数据传输部分被简化了,但是核函数执行所花费的时间反而变多了,这就需要我们根据实际需要取舍了。















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









