






5.4服务器基本框架和事件处理模式
5.4.1基本框架
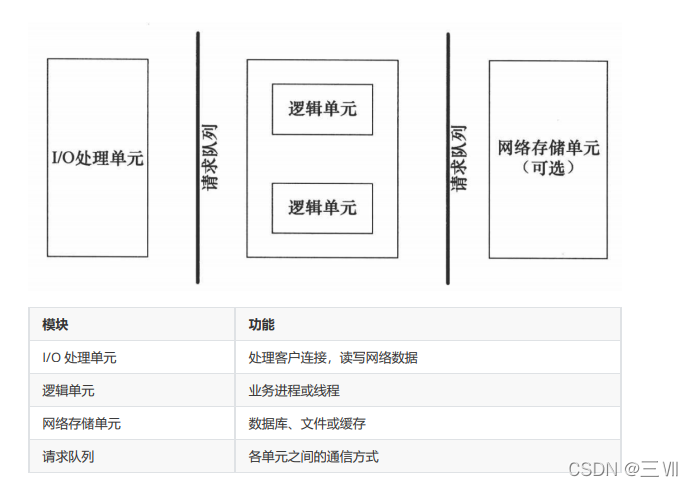
I/O 处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但是数据的收发不一定在 I/O 处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。
一个逻辑单元通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给 I/O 处理单元或者直接发送给客户端(具体使用哪种方式取决于事件处理模式)。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并发处理。
网络存储单元可以是数据库、缓存和文件,但不是必须的。
请求队列是各单元之间的通信方式的抽象。I/O 处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单
元时,也需要采用某种机制来协调处理竞态条件。请求队列通常被实现为池的一部分。
5.4.2两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor和 Proactor,同步 I/O 模型通常用于实现 Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
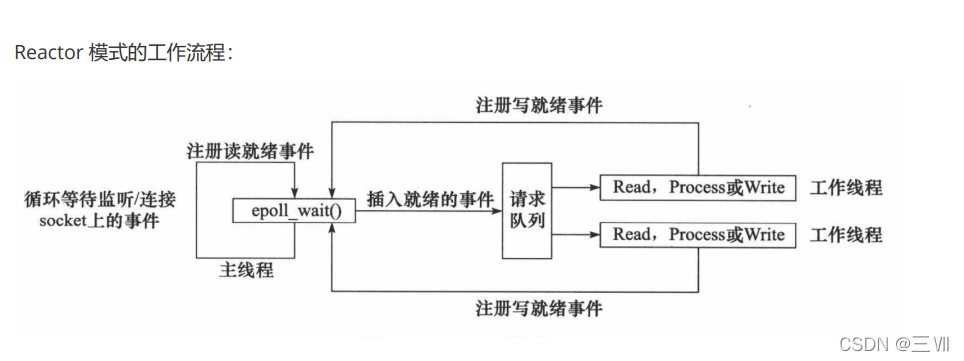
Reactor模式
要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步 I/O(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll
内核事件表中注册该 socket 上的写就绪事件。 - 当主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
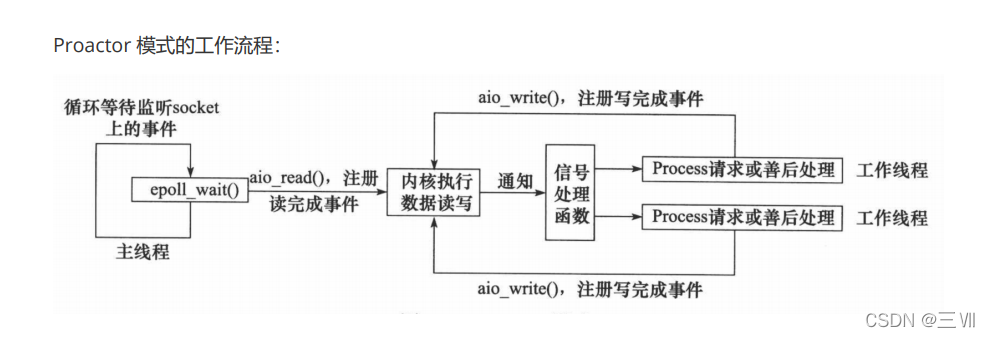
Proactor模式
Proactor 模式将所有 I/O 操作都交给主线程和内核来处理(进行读、写),工作线程仅仅负责业务逻辑。使用异步 I/O 模型(以 aio_read 和 aio_write 为例)实现的 Proactor 模式的工作流程是:
- 主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)。
- 主线程继续处理其他逻辑。
- 当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据已经可用。
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序。
- 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕。
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
区别:工作线程是否需要进行读写操作;
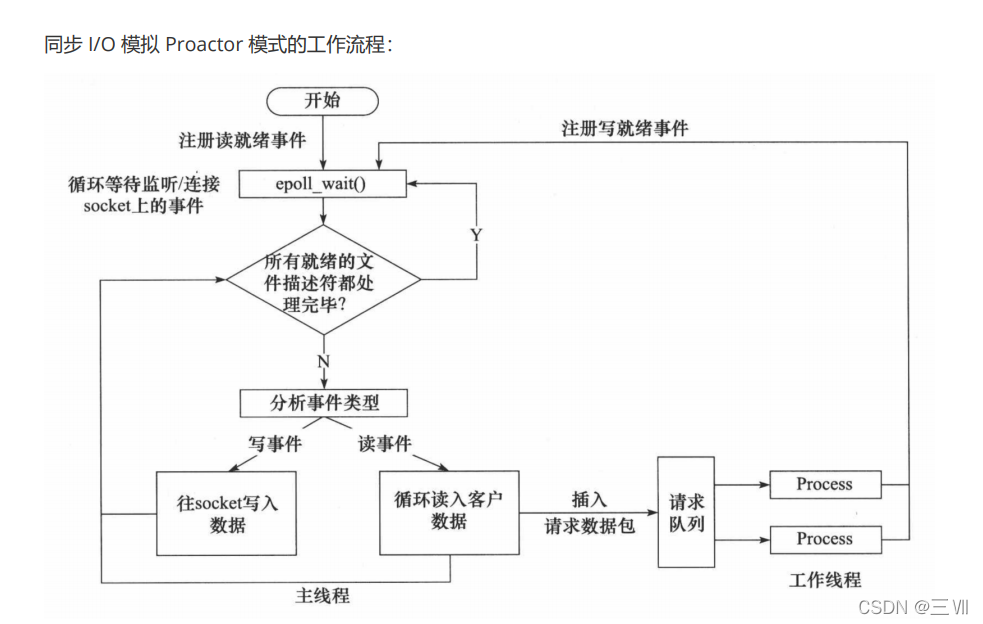
模拟 Proactor 模式
使用同步 I/O 方式模拟出 Proactor 模式。原理是:主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一”完成事件“。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
使用同步 I/O 模型(以 epoll_wait为例)模拟出的 Proactor 模式的工作流程如下:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事件表中注册 socket 上的写就绪事件。
- 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
5.5线程池
线程池是由服务器预先创建的一组子线程,线程池中的线程数量应该和 CPU 数量差不多。线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程,选择一个已经存在的子线程的代价显然要小得多。至于主线程选择哪个子线程来为新任务服务,则有多种方式:
- 主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round
Robin(轮流选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。 - 主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的”接管权“,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在工作队列上。

线程池中的线程数量最直接的限制因素是中央处理器(CPU)的处理器(processors/cores)的数量N :如果你的CPU是4-cores的,对于CPU密集型的任务(如视频剪辑等消耗CPU计算资源的任务)来说,那线程池中的线程数量最好也设置为4(或者+1防止其他因素造成的线程阻塞);对于IO密集型的任务,一般要多于CPU的核数,因为线程间竞争的不是CPU的计算资源而是IO,IO的处理一般较慢,多于cores数的线程将为CPU争取更多的任务,不至在线程处理IO的过程造成CPU空闲导致资源浪费。 - 空间换时间,浪费服务器的硬件资源,换取运行效率。
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
- 当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配。
- 当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
线程池代码
threadpool.h
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <list>
#include <cstdio>
#include <exception>
#include <pthread.h>
#include "locker.h"
template<typename T>
class threadpool{
public:
/*thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量*/
threadpool(int thread_number = 8, int max_requests = 10000);
~threadpool();
bool append(T* request);
private:
/*工作线程运行的函数,它不断从工作队列中取出任务并执行之*/
static void* worker(void* arg);
void run();
private:
// 线程的数量
int m_thread_number;
// 描述线程池的数组,大小为m_thread_number
pthread_t * m_threads;
// 请求队列中最多允许的、等待处理的请求的数量
int m_max_requests;
// 请求队列
std::list< T* > m_workqueue;
// 保护请求队列的互斥锁
locker m_queuelocker;
// 是否有任务需要处理
sem m_queuestat;
// 是否结束线程
bool m_stop;
};
//具体实现
template <typename T>
threadpool< T >::threadpool(int thread_number, int max_requests) :
m_thread_number(thread_number), m_max_requests(max_requests),
m_stop(false), m_threads(NULL) {
if((thread_number <= 0) || (max_requests <= 0) ) {
throw std::exception();
}
m_threads = new pthread_t[m_thread_number];
if(!m_threads) {
throw std::exception();
}
// 创建thread_number 个线程,并将他们设置为脱离线程。
for ( int i = 0; i < thread_number; ++i ) {
printf( "create the %dth thread\n", i);
if(pthread_create(m_threads + i, NULL, worker, this ) != 0) {
delete [] m_threads;
throw std::exception();
}
//设置线程分离;
if( pthread_detach( m_threads[i] ) ) {
delete [] m_threads;
throw std::exception();
}
}
}
//析构函数
template< typename T >
threadpool< T >::~threadpool() {
delete [] m_threads;
m_stop = true;
}
template< typename T >
bool threadpool< T >::append( T* request )
{
// 操作工作队列时一定要加锁,因为它被所有线程共享。
m_queuelocker.lock();
if ( m_workqueue.size() > m_max_requests ) {
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlock();
m_queuestat.post();
return true;
}
template< typename T >
void* threadpool< T >::worker( void* arg )
{
threadpool* pool = ( threadpool* )arg;
pool->run();
return pool;
}
template< typename T >
void threadpool< T >::run() {
while (!m_stop) {
m_queuestat.wait();//判断有没有任务可以做
m_queuelocker.lock();
if ( m_workqueue.empty() ) {
m_queuelocker.unlock();
continue;
}
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
if ( !request ) {
continue;
}
request->process();
}
}
#endif
locker.h
#ifndef LOCKER_H
#define LOCKER_H
//线程同步机制封装类
#include<pthread.h>
#include<exception>
#include <semaphore.h>
//互斥锁类
class locker
{
private:
pthread_mutex_t m_mutex;
public:
locker(){
if(pthread_mutex_init(&m_mutex, NULL)!= 0){
throw std::exception();
}
}
~locker()
{
pthread_mutex_destroy(&m_mutex);
}
bool lock()
{
return pthread_mutex_lock(&m_mutex) == 0;
}
bool unlock()
{
return pthread_mutex_unlock(&m_mutex) == 0;
}
pthread_mutex_t *get()
{
return &m_mutex;
}
};
class cond {
public:
cond(){
if (pthread_cond_init(&m_cond, NULL) != 0) {
throw std::exception();
}
}//初始化信号量
~cond() {
pthread_cond_destroy(&m_cond);
}
//销毁信号量
bool wait(pthread_mutex_t *m_mutex) {
int ret = 0;
ret = pthread_cond_wait(&m_cond, m_mutex);
return ret == 0;
}
bool timewait(pthread_mutex_t *m_mutex, struct timespec t) {
int ret = 0;
ret = pthread_cond_timedwait(&m_cond, m_mutex, &t);
return ret == 0;
}
//带有超时时间的
bool signal() {
return pthread_cond_signal(&m_cond) == 0;
}
bool broadcast() {
return pthread_cond_broadcast(&m_cond) == 0;
}
private:
pthread_cond_t m_cond;
};
// 信号量类
class sem {
public:
sem() {
if( sem_init( &m_sem, 0, 0 ) != 0 ) {
throw std::exception();
}
}
sem(int num) {
if( sem_init( &m_sem, 0, num ) != 0 ) {
throw std::exception();
}
}
~sem() {
sem_destroy( &m_sem );
}
// 等待信号量
bool wait() {
return sem_wait( &m_sem ) == 0;
}
// 增加信号量
bool post() {
return sem_post( &m_sem ) == 0;
}
private:
sem_t m_sem;
};
#endif














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









