






文章目录
ABSTRACT
本文研究了在自动语音识别 (ASR) 中从个性化说话人适应神经网络声学模型 (AM) 中有效检索说话人信息的方法。 这个问题在 ASR 声学模型的联合学习环境中尤为重要,其中基于从多个客户端接收到的更新在服务器上学习全局模型。 我们提出了一种方法来分析神经网络 AMs 中的信息,该方法基于所谓的指标数据集上的神经网络足迹。 使用这种方法,我们开发了两个攻击模型,旨在从更新的个性化模型中推断说话者身份,而无需访问实际用户的语音数据。 TED-LIUM 3 语料库上的实验表明,所提出的方法非常有效,可以提供 1-2% 的相等错误率 (EER)。
这里边出现了一个数据集TED-LIUM 3
1. INTRODUCTION
共享模型更新,即梯度信息,而不是原始用户数据,旨在保护在设备本地处理的用户个人数据。
这样很容易受到攻击,包括:1.成员推断攻击;2.GAN推断攻击等。同样的我们也提出了保护的方式:1.secure multiparty computation安全多方计算;2.differential privacy差分隐私(在用户参数中添加噪声,但这种方法会降低精确度)。例如完全同态加密和安全多方计算在加密域中执行计算,但是这些方法会增加计算复杂度。
语音隐私保护的替代方法包括用于环境声音分析的删除方法,以及旨在抑制语音信号中的个人可识别信息保持所有其他属性不变的匿名化方法。并且这些方法可以混合使用。
通过分析可以从本地更新的用户数据的个性化 AM (声学模型)中检索到的说话者信息,作者开发了两个隐私攻击模型,它们直接对更新的模型参数进行操作,而无需访问实际用户的数据。提出的方法能有效和轻松地从适应的 AM 中检索说话者信息。所提出方法的主要思想是使用外部指标数据集来分析 AM 在该数据上的足迹。这项工作的另一个重要贡献是了解说话人信息如何在适应的 NN(神经网络) AM 中分布。
2. FEDERATED LEARNING FOR ASR ACOUSTIC MODELS
假设数据来自多个远程设备,
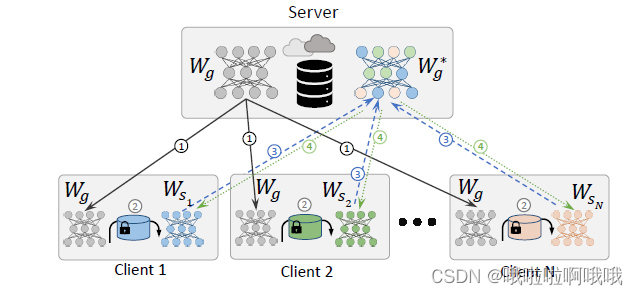
3. ATTACK MODELS
3.1. Privacy preservation scenario
服务器和客户端之间没有语音数据交换,客户端和服务器之间(或某些客户端之间)只传输模型更新。攻击者旨在使用服务器拥有的信息攻击用户。 他们可以访问一些更新的个性化模型。
假设可以接触到的数据:
1.初始全局
W
g
W_{g}
Wg。
2.加入FL系统的目标说话者
s
s
s的个性化模型
W
s
W_{s}
Ws。通过使用说话人数据对
W
g
W_{g}
Wg进行微调,从全局模型
W
g
W_{g}
Wg 中获得相应的个性化模型。我们将此模型视为攻击者的注册数据。
3.测试实验数据:其他的非目标/目标说话人的个性化模型
W
s
1
⋅
⋅
⋅
⋅
⋅
⋅
⋅
W
s
N
W_{s1}·······W_{sN}
Ws1⋅⋅⋅⋅⋅⋅⋅WsN。
攻击者的目标是通过使用
W
s
W_{s}
Ws形式的注册数据模型和模型
W
s
1
⋅
⋅
⋅
⋅
⋅
⋅
⋅
W
s
N
W_{s1}·······W_{sN}
Ws1⋅⋅⋅⋅⋅⋅⋅WsN 形式的测试试验数据来执行自动说话人验证 (ASV) 任务。
3.2. Attack models
所提出方法的动机是基于这样一个假设,即我们可以通过比较从隐藏层 h 中获取的这两个神经 AMs 的输出,从相应的说话人适应模型
W
s
W_{s}
Ws和全局模型
W
g
W_{g}
Wg 中捕获有关说话人身份的信息。 语音数据。 我们将此语音数据称为指标数据。 请注意,指标数据与任何测试或 AM 训练数据无关,可以从任何发言者中任意选择。
假设已知以下所有信息:

3.2.1. Attack model A1
模型如下
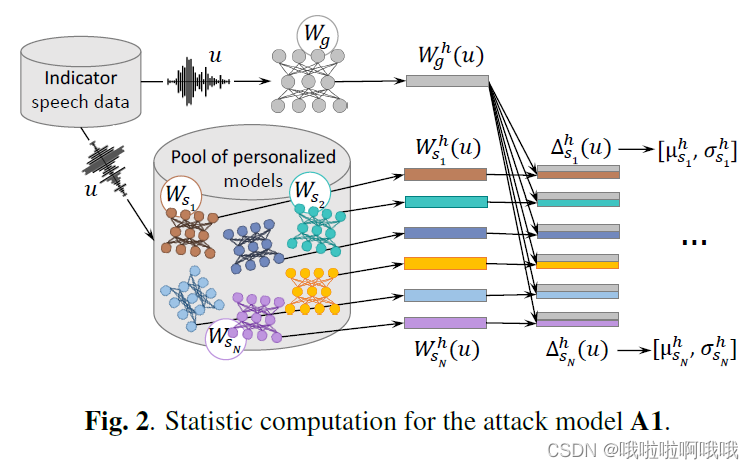
这里边前提假设已经知道这条数据来自某个
W
s
W_{s}
Ws,然后再继续进行识别。
模型的一些参数设定和具体解释:

最后一步计算的是
W
g
W_{g}
Wg和
W
s
W_{s}
Ws之间的相似度。
3.2.2. Attack model A2
用私人和全局模型和刚刚提到的数据集,评估时借助他提取embedding,然后应用PLDA来进行分析。
利用下面的层(冰冻层)算出来的
Δ
s
i
h
\Delta_{s_{i}}^{h}
Δsih:
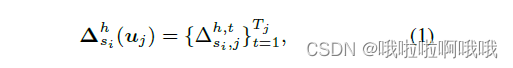
输入到下面
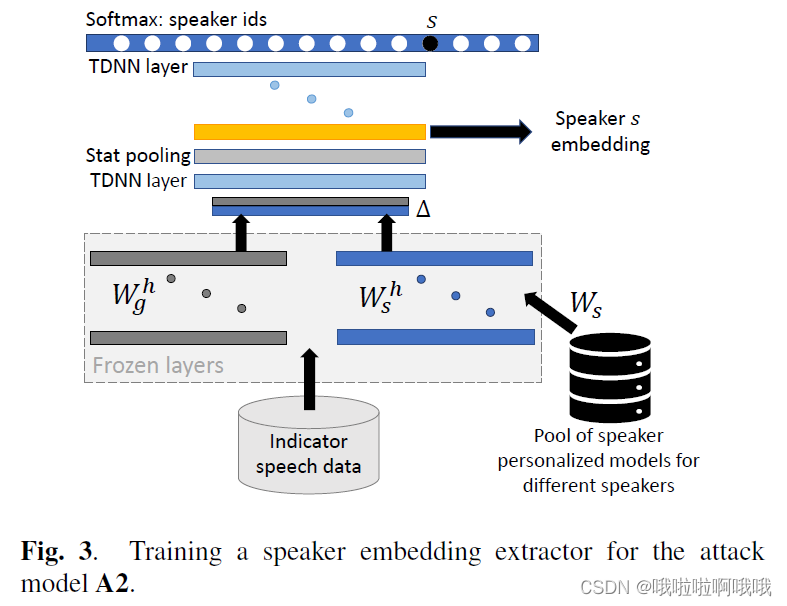
简单点来说冰冻层就是在对数据进行预处理
4. EXPERIMENTS
4.1. Data
实验是在 TED-LIUM 3 语料库 [30] 的说话人适应分区上进行的。 这个公开可用的数据集包含 TED 演讲,总计 452 小时的英语语音数据,来自大约 2K 扬声器,16kHz。 与 [3] 类似,我们从 TED-LIUM 3 训练数据集中选择了三个数据集:Train-G、Part-1、Part-2,具有不相交的说话者子集,如表 1 所示。指标数据集用于训练攻击模型 . 它由从 TED-LIUM 3 语料库的测试和开发数据集的所有 32 个说话者中选出的 320 个话语组成。 指标数据集中的说话者与 Train-G、Part-1 和 Part-2 中的说话者不相交。 对于指标数据集中的每个说话者,我们选择 10 个话语。 指标数据集的大小为 32 分钟。 Train-G 数据集用于训练初始全局 AM Wg。 Part-1和Part-2分别用于获得两组个性化模型
4.2. ASR acoustic models
AM模型包括TDNN结构,用Kaldi工具箱训练。40维的MFCC,没有倒谱截断,附加100维的i-vector作为输入。
每个模型都有 13 个 512 维的隐藏层,后跟一个 softmax 层,其中 3664 个三音素状态用作目标。初始全局模型
W
g
W_{g}
Wg 使用无晶格最大互信息 (LFMMI) 标准进行训练,帧速率降低了 3 倍。
两种类型的语音数据增强策略应用于训练和适应数据:速度扰动(因子为 0.9、1.0、1.1)和音量扰动。 每个模型有大约 1380 万个参数。 最初的全局模型 W g W_{g} Wg 在Train-G 上进行了训练。个性化模型 W s i W_{si} Wsi是通过在说话者数据上微调 W g W_{g} Wg 的所有参数而获得的。 对于所有个性化说话人模型,我们使用大致相同数量的语音数据来执行微调(说话人适应)——每个模型大约需要 4 分钟。 对于大多数发言者(第 1 部分中的 564 名,第 2 部分中的 463 名),我们在不相交的适应子集上获得了两个不同的个性化模型(每个发言者),对于其余发言者,我们只有一个模型的适应数据。
4.3. Attack models
A1是一种基于NN输出的比较统计量和个性化模型之间相关性得分的简单方法,A2是一个相同说话者不同模型之间的比较。
4.3.1. Attack model A1
如第 3.2.1 节所述应用第一个攻击模型。 式(4)中的参数 分别等于 1 和 10。 该模型在对应于 Part-2 的两个个性化模型数据集和组合 Part-1+Part-2 数据集上进行了评估。 指标数据集在所有实验中都是相同的。
4.3.2. Attack model A2
训练时,用了1300个说话者模型对应着736个特有的说话人,用Part-1中的32min(只有32min)的数据集,就可以获得693h (32*1300)的数据。















 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









