







文章概况
《Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting》是2021年发表于NeurIPS上的一篇文章。该文章针对时序预测问题,尤其长期序列,提出一种时序分解模块并对注意力模块进行创新。
模型流程
整个模型的流程大致如下图所示:
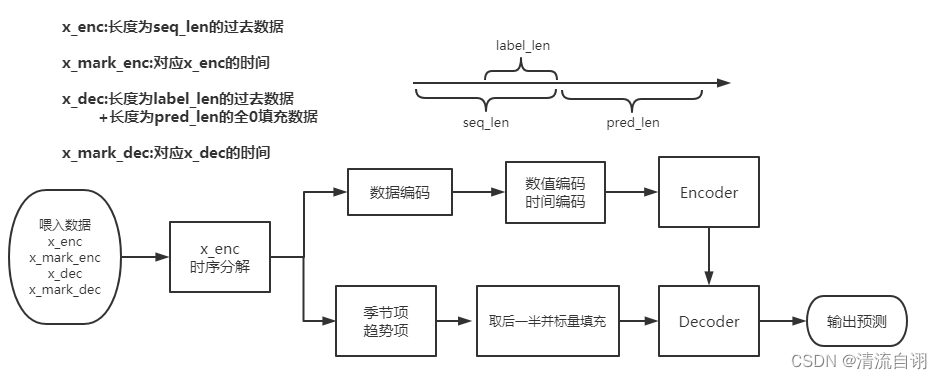
注意点:
1.Encoder和Decoder部分的细节可看下图。
2.“取后一半并标量填充”分为两步,首先对前面计算出的季节项和趋势项取后label_len长度的数据,再在这个的基础上填充长度为pred_len的常数数据(季节项以0填充,趋势项以x_enc的均值填充)。取后一半而不是所有,主要是在保证了预报效果差不多的前提下减少计算量。
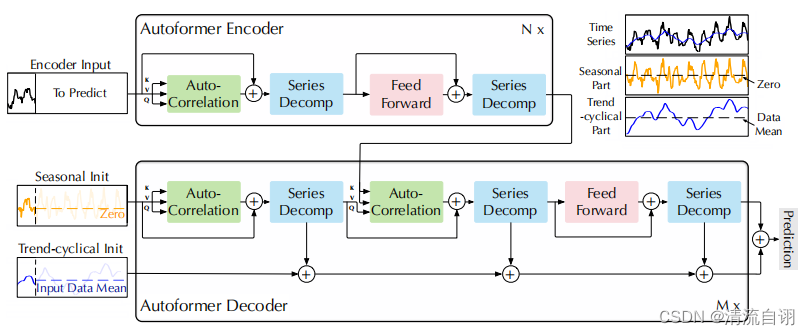
主要结构
Decomposition Architecture(分解结构)
将时序数据通过分解操作转变为若干个子序列的思想在传统的时序预测方法中已有涉及,如ARIMA等。作者成功地将这一思路引入深度学习模型结构设计中。如下图公示所示。作者使用了平均池化以滑动窗口的方式提取了时间序列的整体趋势特征(记作趋势项),其中为保证提取特征前后维度大小不变而使用了首尾填充操作(padding)。接着将原先序列同趋势项做差得到两者差值(记作季节项)。至此原始时间序列便被分解为两个特征序列。
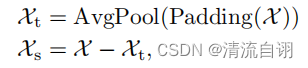
Auto-Correlation Mechanism(自相关机制)
作者提出了一种自关联机制来提高信息的利用率,通过计算序列的自相关来发现基于周期的依赖关系,并通过时延聚合来聚合相似的子序列。
基于周期的依赖关系 作者发现周期之间相同的相位位置的子序列具有相关性。
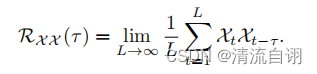
根据随机过程理论,两个序列的相关性可以通过上述公式获得。τ(tao)为原始序列平移长度,该公式旨在对多次序列平移前后的相关性进行计算并求其均值。
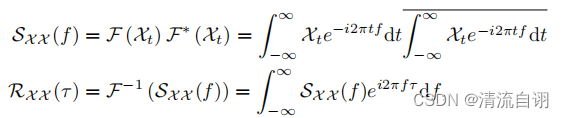
然而这样的计算方式过于冗余,作者通过基于Wiener–Khinchin定理的快速傅里叶变换(公式在上图,所处模型位置在下图左侧“Inverse FFT”)对该部分进行优化,减少计算复杂度。
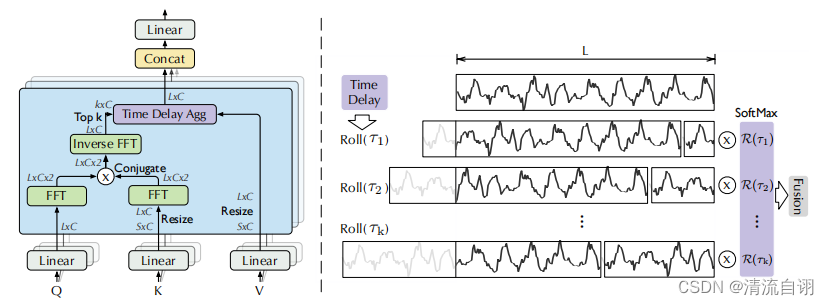
接下来使用所得相关性数值corr,根据相关性均值大小,从中选择最大的k个,于是便获得了最相似情况下的k个平移长度τ。随后对着k组相关值corr_k做softmax,保证每一组的权重总和为1。
时间延迟聚合 延迟,顾名思义,在现有时间的基础上向后顺延。因此可以看到上图右侧出现若干个长度为L的序列(第一行为原始数据,来源于上图左侧的V),从第二个序列开始,前一小段被填补至序列的最末尾。这边可以理解为将序列首尾相接形成一个圆,根据先前求到的τ进行若干次的τ时刻延迟。最后再将延迟后的k个序列同softmax(corr_k)相乘并融合(加权求和)。融合操作就是简单的for循环求和操作,至此便得到了AutoCorrelation的结果。
实验结果
实验涉及的数据集源于真实世界,涵盖了五个主流的时间序列预测方向,分别为能源、交通、经济、天气和疾病。
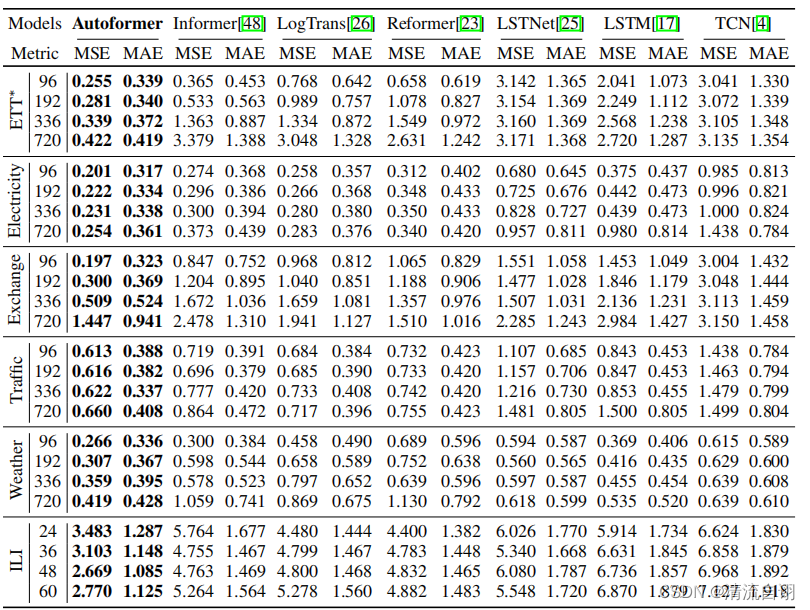
可以看出Autoformer在MAE、MSE上取得了最优异的效果。(更多详细结果可见原文)
消融实验
作者针对所提两个模块的效果展开了一系列的消融实验。
序列分解模块
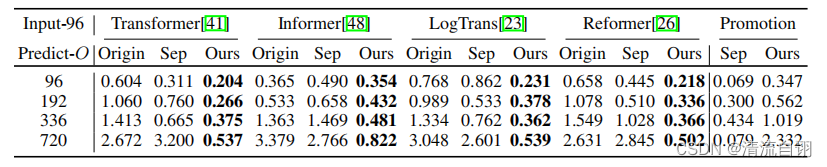
作者将前人的几种方法和自己做了对比。Origin表示他人原始预测结果;Sep表示在模型中分别添加季节时序分解结果和趋势时序分解结果,分别进行预测并最终合并结果;Our表示使用本文提出的完全版时序分解模块。可以看出他人模型在使用了完全版时序分解模块后效果获得显著提高。Promotion这一列应该是文章方法,但最后一行预测未来720时出现更小的0.079让我有些不解。
自相关模块
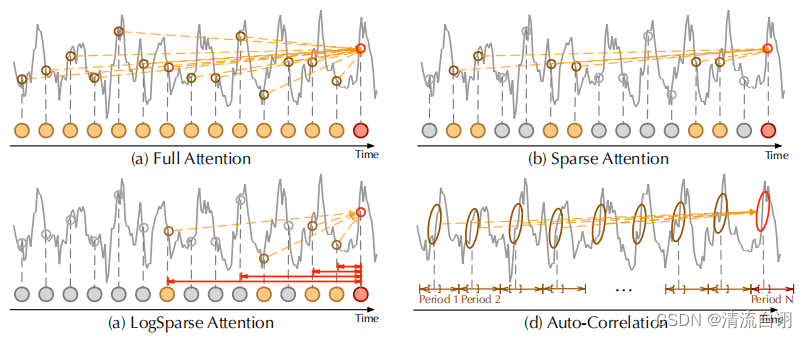
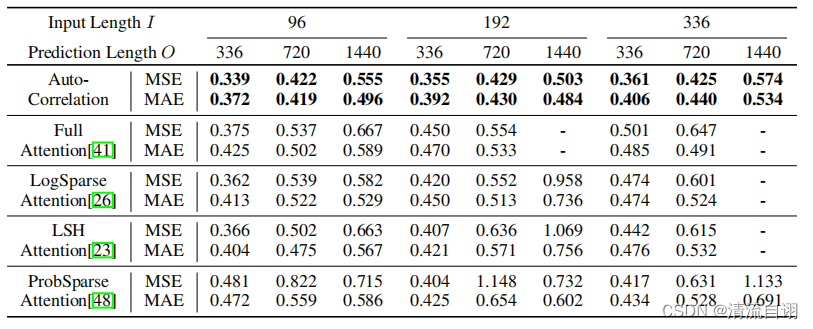
自相关模块是针对注意力机制进行的一个创新,因此作者将多种注意力机制方法与之对比,从表格可以看出自相关模块优于其他的注意力方法,同时从上图各个机制对过去时间序列的关注重点的区别中,我们可以看出自相关机制对周期性数据特征具有更强大的周期特征提取能力,这一能力产生的效果超过了过去针对离散时序数据进行的全局信息提取和稀疏信息提取产生的效果。
总结
在文章的后半部分,作者针对模型的设计进行了分析,主要涉及Decoder部分序列分解模块的个数、依赖性学习效果、复杂季节性建模效果以及模型效率。总体来说,Autoformer相比其他模型确实有着自己得天独厚的优势:从传统方法引入的序列分解模块逐步深入提取到时序数据的特征、自相关机制以注意力机制为蓝本而又与注意力机制大有不同,更加地注重时序数据本身周期性特征的挖掘。
个人认为,分解模块是一个万金油,在诸多平稳性周期性不一的时序数据中均可以使用,但自相关机制由于其更注重时序数据周期性的探索,因此在周期性很弱甚至是正无穷的情况下,强行进行周期特征的提取,有可能会弄巧成拙,当然不管是思路还是方法都给我提供了一个可行的预测方案,而具体效果如何还需要拉到数据上跑一跑。















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











