







1. 论文简介
标题:Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
作者:Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long(Tsinghua University)
发表刊物:NeurIPS 2021
论文下载地址:https://arxiv.org/abs/2106.13008
2. 背景及意义
长距离的时序预测问题,传统的transformer及其改版在计算注意力机制时通常使用以下公式:
导致每次计算时都要将Q与每一个K做相似度计算,而过长的输入迫使模型只能采用稀疏点积取代逐个点积,从而丢失部分信息。
针对此问题,本文提出Auto-Correlation,以子序列之间的相关性计算取代点与点之间的相关性计算,从而直接捕捉子序列直接的关系,提高对历史数据的利用率。
此外,本文将传统transformer直接对输入原始数据处理,修改成季节性-趋势性分解后进行处理,并将注意力机制着重点放在捕捉季节性信息。
3. 研究方法
3.1. 整体框架
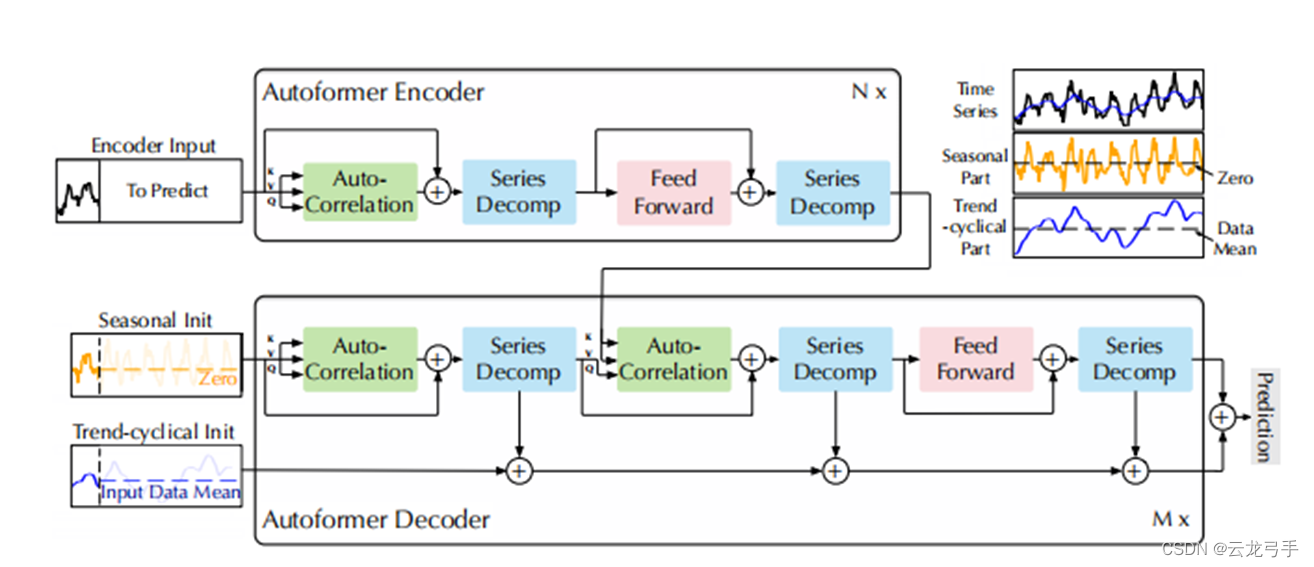
本文提出基于子序列相关性的Auto-Correlation块和基于时序分解的Series Decomp块,分别代替传统transformer中的Self-Attention块和Layer Norm块
3.2. Encoder
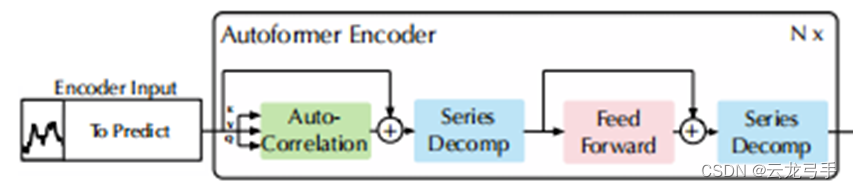
- 结构流程
原始原始数据经过Auto-Correlation得到带权和,与自身相加后通过Series Decomp去除趋势性信息,经过前馈网络与自身相加后再次去除趋势性信息,作为全局的季节性信息表示传递给Decoder
- 公式表达
3.3. Decoder
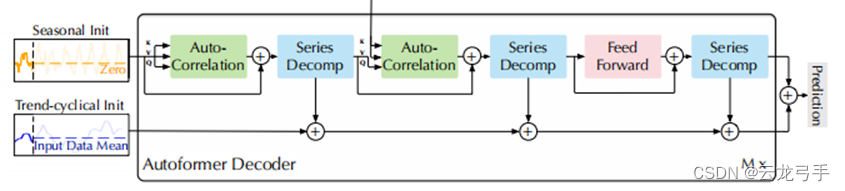
- 结构流程
季节性信息部分:原始数据(预测部分的季节信息以0填充)的季节信息经过Auto-Correlation与自身相加后,经分解得到季节性信息作为Q,与Encoder传递的K/V经Auto-Correlation得到全局历史信息加权和,与自身相加、分解后把季节信息经过前馈网络再与自身相加,最后分解提取季节信息,得到最终季节预测。
趋势性信息部分:原始数据(预测部分的趋势信息以历史均值填充)的趋势信息,通过季节信息通道三次时序分解得到的趋势信息加权聚合,得到最终趋势预测
- 公式表达
3.4. Auto-Correlation
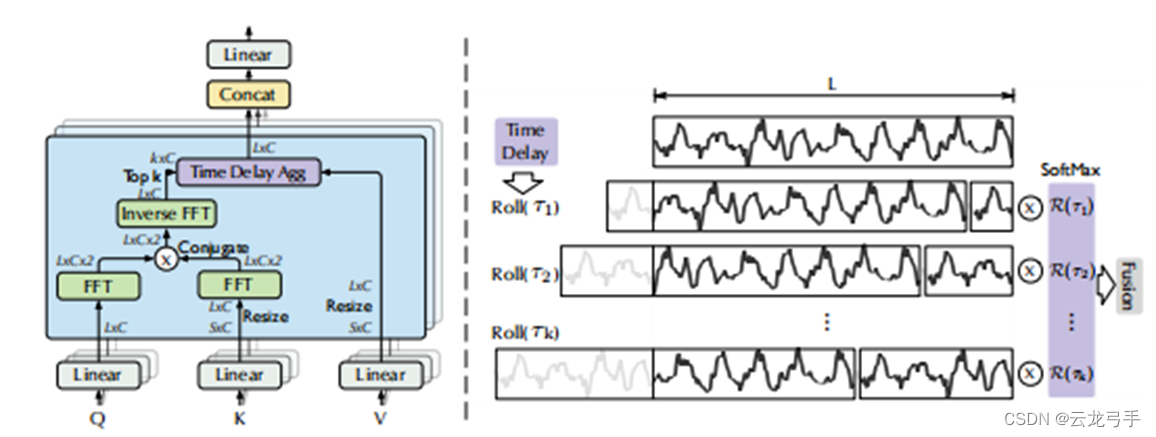
- 时延序列
选择时延时长,将原始序列的前
个数据点转移到末尾(如上右图)
- 子序列相关性(基于随机过程理论)
与Self-Attenetion中的相关性计算类似,通过QK之间的计算,结果越大,表明序列之间的相关性越大,经过SoftMax之后可得到非负且和为1的权重
- 时延聚合
与Self-Attenetion中的加权和类似,将SoftMax输出的权重与时延子序列相乘相加得到时延子序列的加权和,即聚合感兴趣的历史信息
3.5. SeriesDecomp
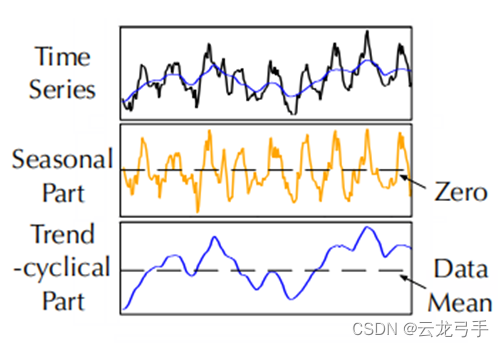
- 趋势性信息提取
以序列的滑动平均值作为趋势信息
- 季节性信息提取
以源序列减去其滑动平均值作为季节性信息
4. 实验验证
4.1. 不同Attention之间对比
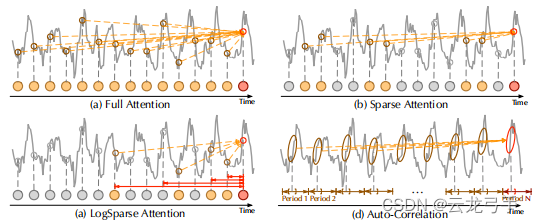
作者将自己的Auto-Corelation将全Attention和两种稀疏Attention作比较,可以看出传统点积的Attention感兴趣的点与源点之间关联度并不高,对时序之间的模式提取能力弱,凸显本文新Attention在捕捉子序列相关性上的优势
4.2. 数据集测试效果对比
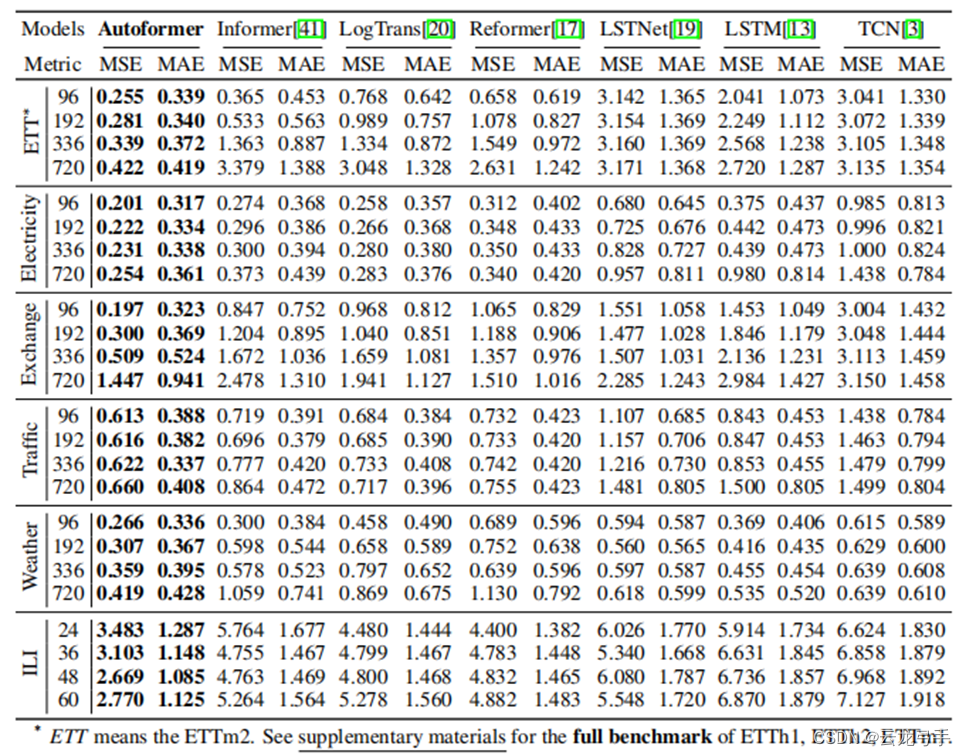
作者以MSE,MAE作为评估项目,在ETT等六种不同领域的时序数据集上,与Informer等三种Transformer改版、两种基于LSTM的模型和TCN进行对比,在不同未来预测长度中均胜过其余Baseline算法。
















 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











