







一、原型模式
原型模式(Prototype Pattern)是指原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象,属于创建型模式。
原型模式的核心在于拷贝原型对象。以系统中已存在的一个对象为原型,直接基于内存二进制流进行拷贝,无需再经历耗时的对象初始化过程(不调用构造函数),性能提升许多。当兑现的构建过程比较耗时时,可以利用当前系统中已存在的对象作为原型,对其进行克隆(一般是基于二进制流的复制),躲避初始化过程,使得新对象的创建时间大大减少。下面,我们来看看原型模式类结构图。
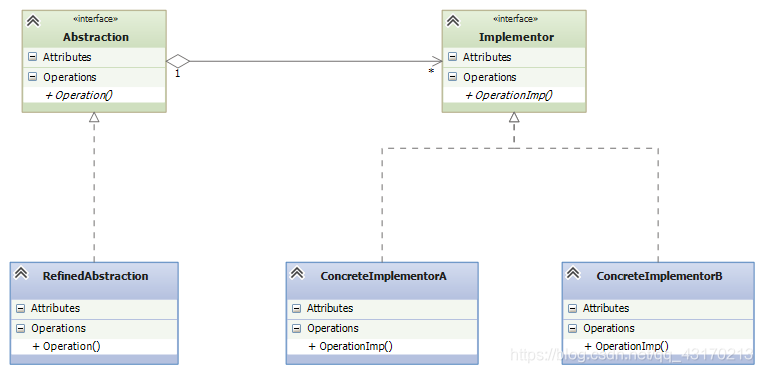
从UML图中,我们可以看到,原型模式,主要包含三个角色:
- 客户(Client):客户类提出创建对象的请求。
- 抽象原型(Prototype):规定拷贝接口。
- 具体原型(Concrete Prototype):被拷贝的对象。
注:对不通过new关键字,而是通过对象拷贝来实现创建对象的模式就称作原型模式。
原型模式的应用场景
你一定遇到过大篇幅getter、setter赋值的场景。例如这样的代码:
@Data
public class ExamPaper{
private String examinationPaperId;//试卷主键
private String leavTime;//剩余时间
private String organizationId;//单位主键
private String id;//考试主键
private String examRoomId;//考场主键
private String userId;//用户主键
private String specialtyCode;//专业代码
private String postionCode;//报考岗位
private String gradeCode;//报考等级
private String examStartTime;//考试开始时间
private String examEndTime;//考试结束时间
private String singleSelectionImpCount;//单选选题重要数量
private String multiSelectionImpCount;//多选题重要数量
private String judgementImpCount;//判断题重要数量
private String examTime;//考试时长
private String fullScore;//总分
private String passScore;//及格分
private String userName;//学员姓名
private String score;//考试得分
private String resut;//是否及格
private String singleOkCount;//单选题答对数量
private String multiOkCount;//多选题答对数量
private String judgementOkCount;//判断题答对数量
public ExamPaper copy(){
ExamPaper examPaper = new ExamPaper();
//剩余时间
examPaper.setLeavTime(this.getLeavTime());
//单位主键
examPaper.setOrganizationId(this.getOrganizationId());
//考试主键
examPaper.setId(this.getId());
//用户主键
examPaper.setUserId(this.getUserId());
//专业
examPaper.setSpecialtyCode(this.getSpecialtyCode());
//岗位
examPaper.setPostionCode(this.getPostionCode());
//等级
examPaper.setGradeCode(this.getGradeCode());
//考试开始时间
examPaper.setExamStartTime(this.getExamStartTime());
//考试结束时间
examPaper.setExamEndTime(this.getExamEndTime());
//单选题重要数量
examPaper.setSingleSelectionImpCount(this.getSingleSelectionImpCount());
//多选题重要数量
examPaper.setMultiSelectionImpCount(this.getMultiSelectionImpCount());
//判断题重要数量
examPaper.setJudgementImpCount(this.getJudgementImpCount());
//考试时间
examPaper.setExamTime(this.getExamTime());
//总分
examPaper.setFullScore(this.getFullScore());
//及格分
examPaper.setPassScore(this.getPassScore());
//学员姓名
examPaper.setUserName(this.getUserName());
//分数
examPaper.setScore(this.getScore());
//单选答对数量
examPaper.setSingleOkCount(this.getSingleOkCount());
//多选答对数量
examPaper.setMultiOkCount(this.getMultiOkCount());
//判断答对数量
examPaper.setJudgementOkCount(this.getJudgementOkCount());
return examPaper;
}
@Override
public String toString() {
return "ExamPaper{" +
"examinationPaperId='" + examinationPaperId + '\'' +
", leavTime='" + leavTime + '\'' +
", organizationId='" + organizationId + '\'' +
", id='" + id + '\'' +
", examRoomId='" + examRoomId + '\'' +
", userId='" + userId + '\'' +
", specialtyCode='" + specialtyCode + '\'' +
", postionCode='" + postionCode + '\'' +
", gradeCode='" + gradeCode + '\'' +
", examStartTime='" + examStartTime + '\'' +
", examEndTime='" + examEndTime + '\'' +
", singleSelectionImpCount='" + singleSelectionImpCount + '\'' +
", multiSelectionImpCount='" + multiSelectionImpCount + '\'' +
", judgementImpCount='" + judgementImpCount + '\'' +
", examTime='" + examTime + '\'' +
", fullScore='" + fullScore + '\'' +
", passScore='" + passScore + '\'' +
", userName='" + userName + '\'' +
", score='" + score + '\'' +
", resut='" + resut + '\'' +
", singleOkCount='" + singleOkCount + '\'' +
", multiOkCount='" + multiOkCount + '\'' +
", judgementOkCount='" + judgementOkCount + '\'' +
'}';
}
}
代码非常工整,命名非常规范,注释也写的很全面,其实这就是原型模式的需求场景。但是,上述代码属于纯体力劳动。那原型模式,能帮助我们解决这样的问题。
原型模式主要适用于以下场景:
1、类初始化消化资源较多
2、new 产生的一个对象需要非常繁琐的过程(数据准备,访问权限等)
3、构造函数比较复杂
4、循环体中生产大量的对象时。
在Spring中,原型模式应用得非常广泛。例如 scope = “prototype”,在我们经常用的JSON。parseObject()也是一种原型模式。
原型模式的通用写法
- 一个标准的原型模式代码,应该是这样设计的,先创建原型IPrototype接口:
public interface IPrototype<T> {
T clone();
}
- 创建具体需要克隆的对象ConcretePrototype
public class ConcretePrototype implements IPrototype {
private int age;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public ConcretePrototype clone() {
ConcretePrototype concretePrototype = new ConcretePrototype();
concretePrototype.setAge(this.age);
concretePrototype.setName(this.name);
return concretePrototype;
}
@Override
public String toString() {
return "ConcretePrototype{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
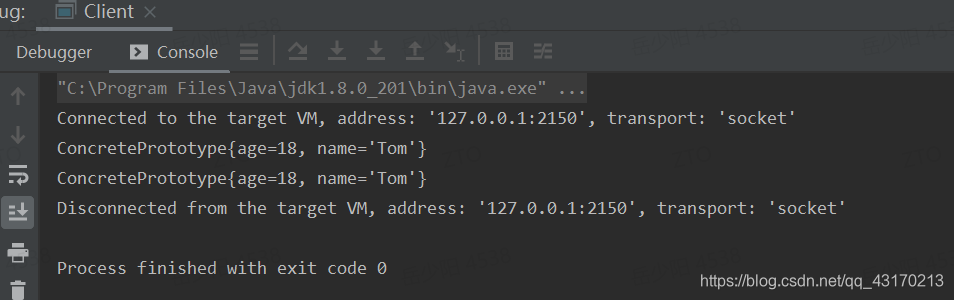
- 测试代码
public class Client {
public static void main(String[] args) {
//创建原型对象
ConcretePrototype prototype = new ConcretePrototype();
prototype.setAge(18);
prototype.setName("Tom");
System.out.println(prototype);
//拷贝原型对象
ConcretePrototype cloneType = prototype.clone();
System.out.println(cloneType);
}
}
- 运行结果:
在实际编码中,我们一般不会浪费这样的体力劳动,JDK已经帮我们实现了一个现成的API,我们只需要实现Cloneable接口即可。来改造一下代码,修改ConcretePrototype类:
@Data
public class ConcretePrototype implements Cloneable {
private int age;
private String name;
private List<String> hobbies;
@Override
public ConcretePrototype clone() {
try {
return (ConcretePrototype)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
@Override
public String toString() {
return "ConcretePrototype{" +
"age=" + age +
", name='" + name + '\'' +
", hobbies=" + hobbies +
'}';
}
}
写一个测试用例
public class Client {
public static void main(String[] args) {
//创建原型对象
ConcretePrototype prototype = new ConcretePrototype();
prototype.setAge(18);
prototype.setName("Tom");
List<String> hobbies = new ArrayList<String>();
hobbies.add("书法");
hobbies.add("美术");
prototype.setHobbies(hobbies);
//拷贝原型对象
ConcretePrototype cloneType = prototype.clone();
cloneType.getHobbies().add("技术控");
System.out.println("原型对象:" + prototype);
System.out.println("克隆对象:" + cloneType);
System.out.println(prototype == cloneType);
System.out.println("原型对象的爱好:" + prototype.getHobbies());
System.out.println("克隆对象的爱好:" + cloneType.getHobbies());
System.out.println(prototype.getHobbies() == cloneType.getHobbies());
}
}
运行结果
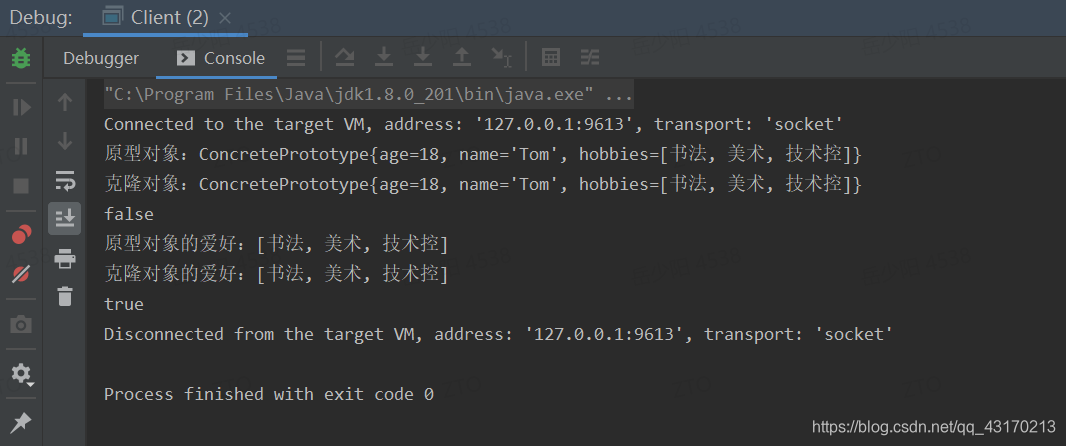
我们给复制后的克隆对象新增一项爱好,发现原型对象也发生了变化,这显然不符合我们的预期。因为我们希望克隆出来的对象应该和原型对象是两个独立的对象,不应该再有联系了。从测试结果分析来看,应该是hobies共用了一个内存地址,意味着复制的不是值,而是引用的地址。这样的话,如果我们修改的是一个对象中的属性值,prototype和cloneType的hobbies值都会改变。这就是我们常说的浅克隆。只是完整复制了值类型数据,没有复制引用对象。换言之,所有的引用对象仍然指向原来的对象,显然不是我们想要的结果。下面我们引入深克隆继续改造。
使用序列化实现深度克隆
在上面的基础上,我们继续改造,来看代码,增加一个deepClone()方法:
@Data
public class ConcretePrototype implements Cloneable,Serializable {
private int age;
private String name;
private List<String> hobbies;
@Override
public ConcretePrototype clone() {
try {
return (ConcretePrototype)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
public ConcretePrototype deepCloneHobbies(){
try {
ConcretePrototype result = (ConcretePrototype)super.clone();
result.hobbies = (List)((ArrayList)result.hobbies).clone();
return result;
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
public ConcretePrototype deepClone(){
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (ConcretePrototype)ois.readObject();
}catch (Exception e){
e.printStackTrace();
return null;
}
}
@Override
public String toString() {
return "ConcretePrototype{" +
"age=" + age +
", name='" + name + '\'' +
", hobbies=" + hobbies +
'}';
}
}
测试代码
public class Client {
public static void main(String[] args) {
//创建原型对象
ConcretePrototype prototype = new ConcretePrototype();
prototype.setAge(18);
prototype.setName("Tom");
List<String> hobbies = new ArrayList<String>();
hobbies.add("书法");
hobbies.add("美术");
prototype.setHobbies(hobbies);
//拷贝原型对象
ConcretePrototype cloneType = prototype.deepCloneHobbies();
cloneType.getHobbies().add("技术控");
System.out.println("原型对象:" + prototype);
System.out.println("克隆对象:" + cloneType);
System.out.println(prototype == cloneType);
System.out.println("原型对象的爱好:" + prototype.getHobbies());
System.out.println("克隆对象的爱好:" + cloneType.getHobbies());
System.out.println(prototype.getHobbies() == cloneType.getHobbies());
}
}
运行结果
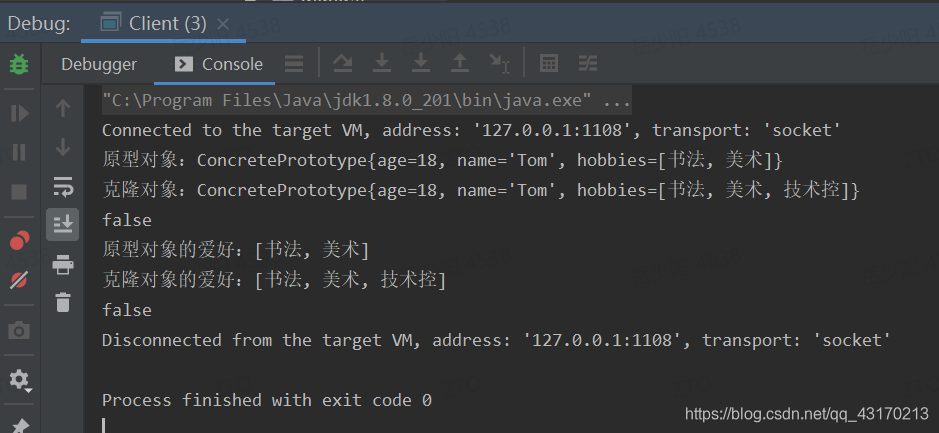
克隆会破坏单例模式
如果我们克隆的目标对象是单例对象,那意味着,深克隆就会破坏单例。实际上防止克隆破坏单例解决思路非常简单,禁止深克隆便可。要么我们的单例类不实现Cloneable接口;要么我们重写clone()方法,在clone方法中返回单例对象即可,具体代码如下:
@Override
protected object clone() throws CloneNotSupportedException {
return instance;
}
原型模式在源码中的应用
先来JDK中Cloneable接口:
public interface Cloneable{
}
接口定义还是很简答的,我们找源码其实只需要找到看哪些接口实现了Cloneable即可。来看ArrayList类的实现。
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
我们发现方法中知识将List中的元素循环遍历了一遍。这个时候我们再思考一下,是不是这种形式就是深克隆呢?其实用代码验证一下就知道了,继续修改ConcretePrototype类,增加一个deepCloneHobbies()方法:
public ConcretePrototype deepClone(){
try {
ConcretePrototype result = (ConcretePrototype) super.clone();
result.hobbies = (List) ((ArrayList)result.hobbies).clone();
return result;
}catch (CloneNotSupportedException e){
e.printStackTrace();
return null;
}
}
修改客户端代码:
public static void main(String[] args) {
...
//拷贝原型对象
ConcretePrototype cloneType = prototype.deepCloneHobbies();
...
}
运行也能得到期望的结构。但是这样的代码,其实是硬编码,如果在对象中声明了各种集合的类型,那每种情况都需要单独处理。因此,申客隆的写法,一般会直接用序列化来操作。
原型模式的优缺点:
优点:
1、性能优良,Java自带的 原型模式 是基于内存二进制流的拷贝,比直接new 一个对象性能上提升了许多。
2、可以使用深克隆方式保存对象的状态,使用原型模式对象复制一份并将其状态保存起来,简化了创建对象的过程,以便在需要的时候使用(例如恢复到历时某一状态),可辅助实现撤销操作。
缺点:
1、需要为每一个类配置一个克隆放啊。
2、克隆方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违反了开闭原则。
3、在实现深克隆时,需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来会比较麻烦。因此深拷贝、浅拷贝需要运用得当。
二、建造者模式
建造者模式(Builder Pattern)是一个将复杂对象的构建过程与它的表示分离,使得同样的构建过程可以创建不同的表示,属于创建型模式。使用建造者模式对于用户而言只需指定需要建造的类型就可以获得对象,建造过程及细节不需要了解。
建造者模式适用于创建对象需要很多步骤,但是步骤的顺序不一定固定。如果一个对象有非常复杂的内部结构(很多属性),可以将复杂对象的创建和使用进行分离。
使用场景
这个就非常重要了,因为如果你学了个东西,都不知道用来解决什么问题,你说有什么用?理解使用场景的的重要性要远高于你是不是会实现这个模式,因为只要你知道什么问题可以使用builder模式来解决,那你即使不会写,也可以在调查相关资料后完成。 我不想说一些大而正确的术语来把你搞蒙,我们只针对具体的问题,至于延展性的思考,随着你知识的增长,逐渐会明白的。延展阅读
当一个类的构造函数参数个数超过4个,而且这些参数有些是可选的参数,考虑使用构造者模式。
解决的问题
当一个类的构造函数参数超过4个,而且这些参数有些是可选的时,我们通常有两种办法来构建它的对象。 例如我们现在有如下一个类计算机类Computer,其中cpu与ram是必填参数,而其他3个是可选参数,那么我们如何构造这个类的实例呢,通常有两种常用的方式:
public class Computer {
private String cpu;//必须
private String ram;//必须
private int usbCount;//可选
private String keyboard;//可选
private String display;//可选
}
- 第一:折叠构造函数模式(telescoping constructor pattern ),这个我们经常用,如下代码所示
public class Computer {
...
public Computer(String cpu, String ram) {
this(cpu, ram, 0);
}
public Computer(String cpu, String ram, int usbCount) {
this(cpu, ram, usbCount, "罗技键盘");
}
public Computer(String cpu, String ram, int usbCount, String keyboard) {
this(cpu, ram, usbCount, keyboard, "三星显示器");
}
public Computer(String cpu, String ram, int usbCount, String keyboard, String display) {
this.cpu = cpu;
this.ram = ram;
this.usbCount = usbCount;
this.keyboard = keyboard;
this.display = display;
}
}
- 第二种:Javabean 模式,如下所示
public class Computer {
...
public String getCpu() {
return cpu;
}
public void setCpu(String cpu) {
this.cpu = cpu;
}
public String getRam() {
return ram;
}
public void setRam(String ram) {
this.ram = ram;
}
public int getUsbCount() {
return usbCount;
}
...
}
那么这两种方式有什么弊端呢?
第一种主要是使用及阅读不方便。你可以想象一下,当你要调用一个类的构造函数时,你首先要决定使用哪一个,然后里面又是一堆参数,如果这些参数的类型很多又都一样,你还要搞清楚这些参数的含义,很容易就传混了。。。那酸爽谁用谁知道。
第二种方式在构建过程中对象的状态容易发生变化,造成错误。因为那个类中的属性是分步设置的,所以就容易出错。
为了解决这两个痛点,builder模式就横空出世了。
如何实现
- 在Computer 中创建一个静态内部类 Builder,然后将Computer 中的参数都复制到Builder类中。
- 在Computer中创建一个private的构造函数,参数为Builder类型
- 在Builder中创建一个public的构造函数,参数为Computer中必填的那些参数,cpu 和ram。
- 在Builder中创建设置函数,对Computer中那些可选参数进行赋值,返回值为Builder类型的实例
- 在Builder中创建一个build()方法,在其中构建Computer的实例并返回
下面代码就是最终的样子
public class Computer {
private final String cpu;//必须
private final String ram;//必须
private final int usbCount;//可选
private final String keyboard;//可选
private final String display;//可选
private Computer(Builder builder){
this.cpu=builder.cpu;
this.ram=builder.ram;
this.usbCount=builder.usbCount;
this.keyboard=builder.keyboard;
this.display=builder.display;
}
public static class Builder{
private String cpu;//必须
private String ram;//必须
private int usbCount;//可选
private String keyboard;//可选
private String display;//可选
public Builder(String cup,String ram){
this.cpu=cup;
this.ram=ram;
}
public Builder setUsbCount(int usbCount) {
this.usbCount = usbCount;
return this;
}
public Builder setKeyboard(String keyboard) {
this.keyboard = keyboard;
return this;
}
public Builder setDisplay(String display) {
this.display = display;
return this;
}
public Computer build(){
return new Computer(this);
}
}
//省略getter方法
}
如何使用
在客户端使用链式调用,一步一步的把对象构建出来。
Computer computer=new Computer.Builder("因特尔","三星")
.setDisplay("三星24寸")
.setKeyboard("罗技")
.setUsbCount(2)
.build();
案例
构建者模式是一个非常实用而常见的创建类型的模式(creational design pattern),例如图片处理框架Glide,网络请求框架Retrofit等都使用了此模式。
传统Builder 模式
构建者模式UML图如下所示
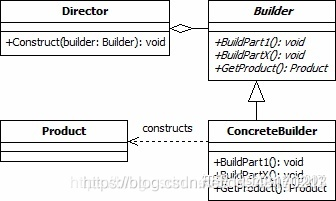
如上图所示,builder模式有4个角色。
- Product: 最终要生成的对象,例如 Computer实例。
- Builder: 构建者的抽象基类(有时会使用接口代替)。其定义了构建Product的抽象步骤,其实体类需要实现这些步骤。其会包含一个用来返回最终产品的方法Product getProduct()。
- ConcreteBuilder: Builder的实现类。
- Director: 决定如何构建最终产品的算法. 其会包含一个负责组装的方法void Construct(Builder builder), 在这个方法中通过调用builder的方法,就可以设置builder,等设置完成后,就可以通过builder的 getProduct() 方法获得最终的产品。
我们接下来将最开始的例子使用传统方式来实现一遍。
- 第一步:我们的目标Computer类:
public class Computer {
private String cpu;//必须
private String ram;//必须
private int usbCount;//可选
private String keyboard;//可选
private String display;//可选
public Computer(String cpu, String ram) {
this.cpu = cpu;
this.ram = ram;
}
public void setUsbCount(int usbCount) {
this.usbCount = usbCount;
}
public void setKeyboard(String keyboard) {
this.keyboard = keyboard;
}
public void setDisplay(String display) {
this.display = display;
}
@Override
public String toString() {
return "Computer{" +
"cpu='" + cpu + '\'' +
", ram='" + ram + '\'' +
", usbCount=" + usbCount +
", keyboard='" + keyboard + '\'' +
", display='" + display + '\'' +
'}';
}
}
- 第二步:抽象构建者类
public abstract class ComputerBuilder {
public abstract void setUsbCount();
public abstract void setKeyboard();
public abstract void setDisplay();
public abstract Computer getComputer();
}
- 第三步:实体构建者类,我们可以根据要构建的产品种类产生多了实体构建者类,这里我们需要构建两种品牌的电脑,苹果电脑和联想电脑,所以我们生成了两个实体构建者类。
苹果电脑构建者类
public class MacComputerBuilder extends ComputerBuilder {
private Computer computer;
public MacComputerBuilder(String cpu, String ram) {
computer = new Computer(cpu, ram);
}
@Override
public void setUsbCount() {
computer.setUsbCount(2);
}
@Override
public void setKeyboard() {
computer.setKeyboard("苹果键盘");
}
@Override
public void setDisplay() {
computer.setDisplay("苹果显示器");
}
@Override
public Computer getComputer() {
return computer;
}
}
- 第四步:指导者类(Director)
public class ComputerDirector {
public void makeComputer(ComputerBuilder builder){
builder.setUsbCount();
builder.setDisplay();
builder.setKeyboard();
}
}
使用
首先生成一个director (1),然后生成一个目标builder (2),接着使用director组装builder (3),组装完毕后使用builder创建产品实例 (4)。
public static void main(String[] args) {
ComputerDirector director=new ComputerDirector();//1
ComputerBuilder builder=new MacComputerBuilder("I5处理器","三星125");//2
director.makeComputer(builder);//3
Computer macComputer=builder.getComputer();//4
System.out.println("mac computer:"+macComputer.toString());
ComputerBuilder lenovoBuilder=new LenovoComputerBuilder("I7处理器","海力士222");
director.makeComputer(lenovoBuilder);
Computer lenovoComputer=lenovoBuilder.getComputer();
System.out.println("lenovo computer:"+lenovoComputer.toString());
}
输出结果如下:
mac computer:Computer{cpu='I5处理器', ram='三星125', usbCount=2, keyboard='苹果键盘', display='苹果显示器'}
lenovo computer:Computer{cpu='I7处理器', ram='海力士222', usbCount=4, keyboard='联想键盘', display='联想显示器'}
可以看到,文章最开始的使用方式是传统builder模式的变种, 首先其省略了director 这个角色,将构建算法交给了client端,其次将builder 写到了要构建的产品类里面,最后采用了链式调用。
建造者模式的优缺点
建造者模式的优点:
1、封装性号,创建和使用分离;
2、扩展性好,建造类之间独立、一定程度上解耦。
建造者模式的缺点:
1、产生多余的Builder;
2、产品内部发生变化,建造者都要修改,成本较大。
建造者模式和工厂模式的区别
1、建造者模式更加注重方法的调用顺序,工行模式注重于创建对象。
2、创建对象的力度不同,建造者模式创建复杂的对象,由各种复杂的部件组成,工厂模式创建出来的都一样。
3、关注重点不一样,工厂模式只需要把对象创建出来就可以了,而建造者模式中不仅要创建出这个对象,还要知道这个对象由哪些部件组成。
4、建造者模式根据建造过程中的顺序不一样,最终的对象部件组成也不一样。















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









