






Improving Object Detection With One Line of Code解读
一、论文地址及贡献
1.1论文地址
论文地址:https://arxiv.org/abs/1704.04503
1.2论文贡献
在原有的NMS上改进,使得检测算法的预测框更加准确。
二、NMS算法
1.1NMS介绍
检测器预测完结果,一张图像中会有很多预测框,显示的图片会有很多预测框,进行NMS可以过滤掉与同一检测对象中置信度分数最高的预测框IoU超过阈值的其他预测框,即同对象的多个预测结果我们只取置信度分数最高的那个预测结果,其余的我们都不要。
NMS时,置信度分高但是位置不够准的框可能会把置信度分低但是位置很准的框去掉。这使得原本定位准确的边界框会在迭代回归的过程中偏离目标,和我们的最终目标是冲突的。
NMS思路就是:对于输入的图像里面的每一个预测框,模型给每个预测框都添加了一个置信度分数。
(1)在所有的预测框里面筛选,将置信度小于阈值a的所有预测框去掉。
(2)然后在同一个图片上,根据类别,将所有预测框的置信度分数按照从高到低排序,将置信度分数最高的预测框保留,作为我们需要保留此类别的第一个预测框。
(3)按照剩下的预测框计算对应的IoU。
(4)将IoU大于IoU阈值的预测框的置信度分数置为0.
(5)经过一轮迭代之后已经筛选掉与第一个预测框重合度较高的预测框。
然后从剩下的预测框继续上述步骤得到第二个预测框,进行后续迭代直到所有类别全部处理完。
1.2NMS修剪预测框的评估函数

Si是当前检测框的置信度分数,Nt是IOU阈值,M为置信度分数最高的检测框。
三、soft-NMS算法
因为传统的NMS会导致重叠区域较大的目标检测框被漏检。下图是传统NMS与soft-NMS的比较:

soft-NMS用下图的修剪函数来改善NMS:
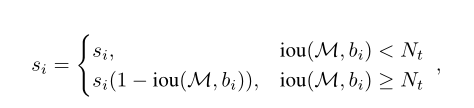
上述函数将会高于阈值Nt的检测框,作为与M重叠的线性方法衰退。因此,远离M的检测盒将不受影响,而非常接近的检测盒将被分配更大的惩罚。
然而,就重叠而言,它不是连续的,当达到NMS阈值Nt时,会应用突然的惩罚。如果惩罚函数是连续的,这将是理想的,否则它可能导致检测的等级列表的突然变化。当没有重叠时,连续惩罚函数应该没有惩罚,而在高重叠时,应该有非常高的惩罚。此外,当重叠较低时,它应该逐渐增加惩罚,因为M不应该影响与其重叠非常低的盒子的分数。然而,当一个盒子与M的重叠变得接近1时,将会受到严重的惩罚。考虑到这一点,我们建议用高斯罚函数更新修剪步骤,如下所示:
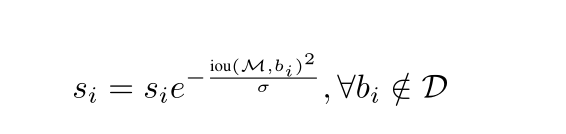
在每次迭代中应用该更新规则,并且更新所有剩余检测框的分数。















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









