







# 关键词: CNN、RNN、LSTM、transform、vit、视频理解、动作分类
# 关键词: RNN的3个分类: simple RNN、LSTM、GRU序列模型
vision-transformer encoder
cnn-rnn/vit视频动作分类
# 计划: 1、 simple RNN、LSTM、GRU序列模型、架构
2、 simple RNN、LSTM、GRU序列模型、情感分类demo
3、基于CNN-RNN的视频动作分类项目...【数据集小时】
4、基于CNN-vit的视频动作分类项目...【数据集大时】
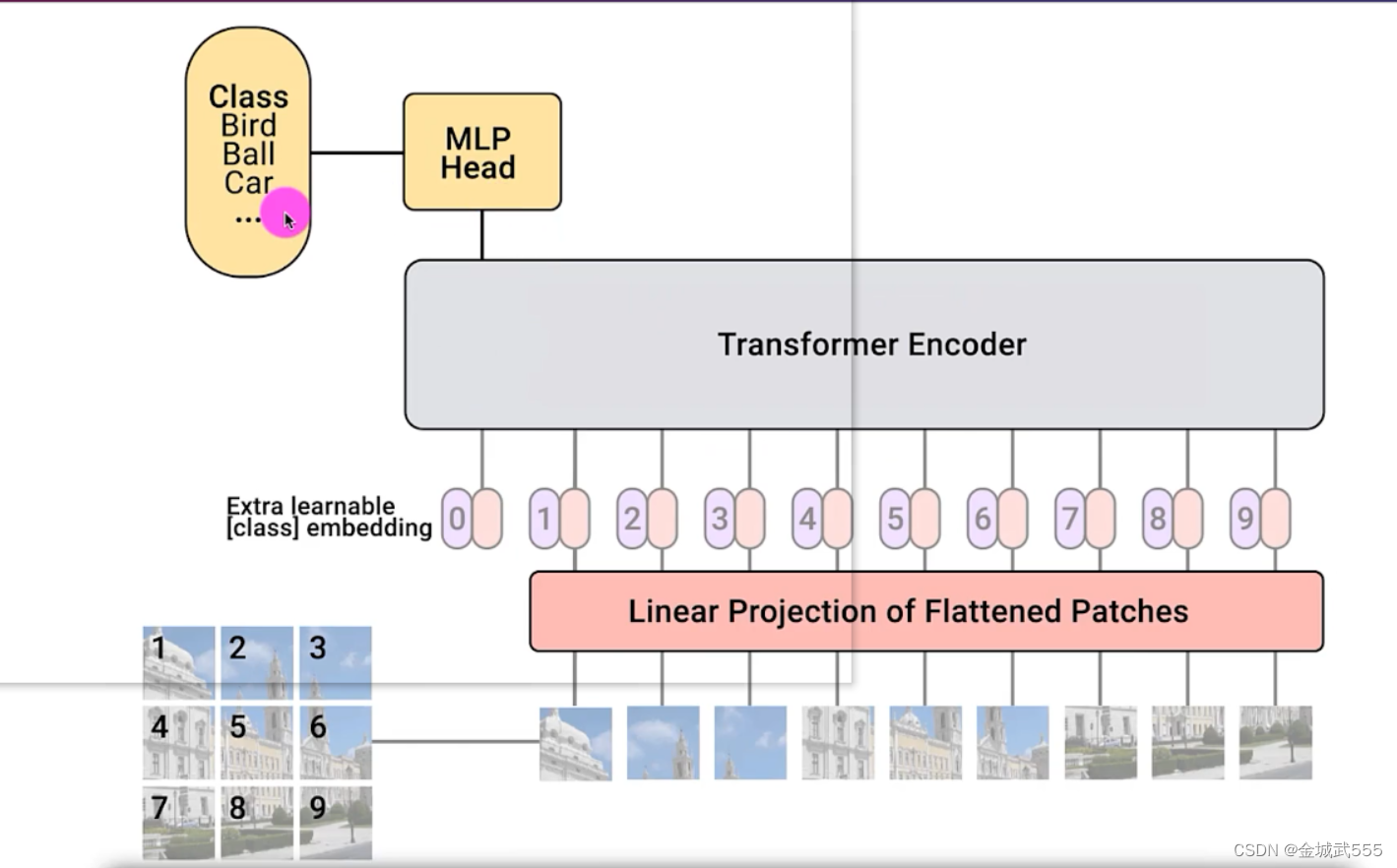
简述transformer: 图片->划分成patch小块 -> 拉直成向量
-> +位置编码 -->> 输入: transformer-encoder网络
-->> 多头、自注意力机制 --->>> 最后,再做分类!!!
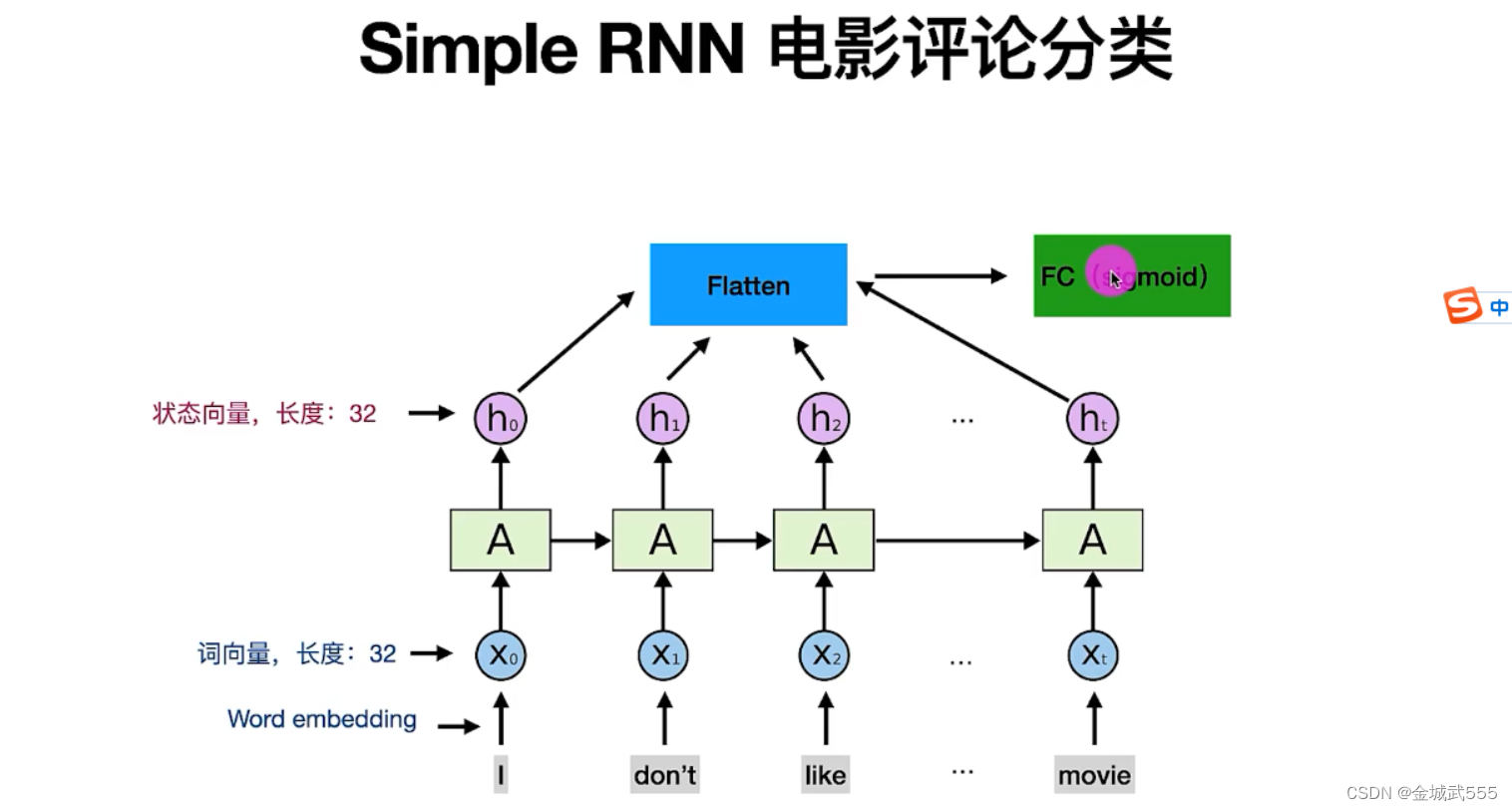
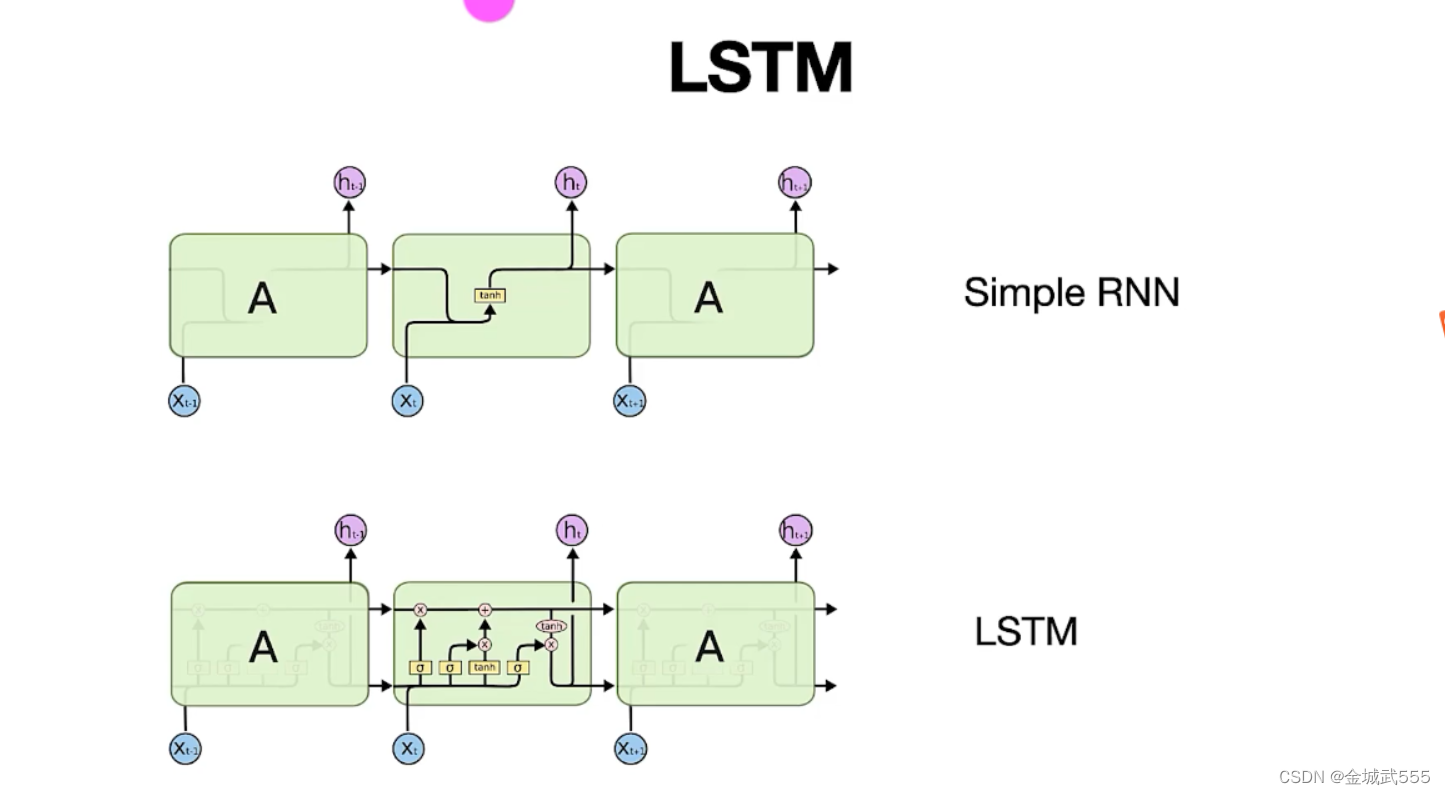
RNN: 非常擅长处理、序列数据!!
原因:他有顺序记忆的能力。逐渐积累信息!!!
RNN工作流程: 1、状态h记录状态信息、 2、词变成词向量xt 3、词向量xt输入RNN、RNN更新状态h 4、新的输入,会积累到状态h里去、逐渐累加起来!
5、更新状态 h时,需要使用到 参数矩阵A, 6、整个语句,只有一个参数矩阵A,A的数值由我们训练得到!!!
公式: tan h【A * [拼接:旧状态h0 + 新向量x1]】, 双曲正切: tanh ,值域【-1,1】,其实就是tan h = sin h /cos h
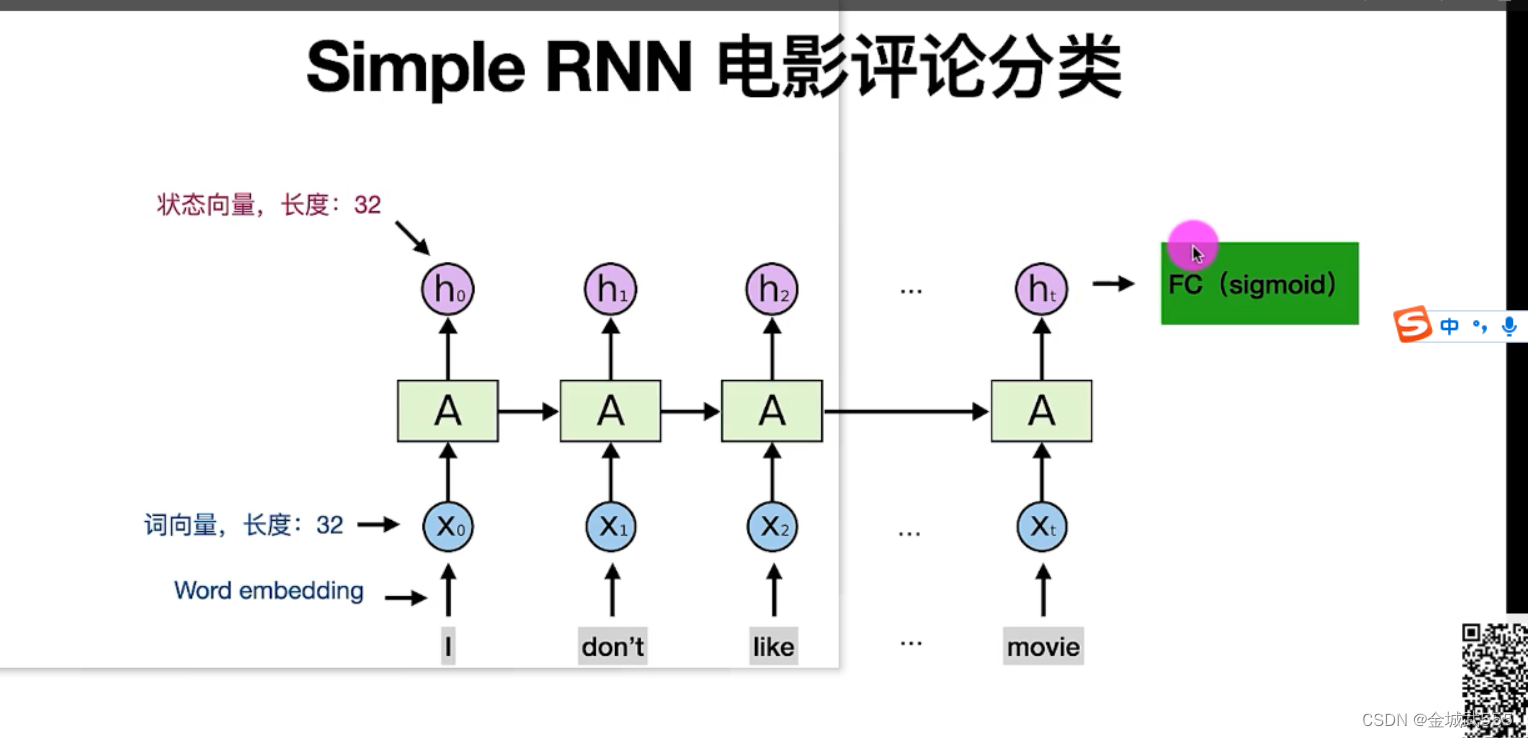
imdb电影评论分类: 正面positive、负面negative分类、 自动识别正/负面!!
创建环境: imdb python=3.8
# 下载 tensorflow-gpu报错: https 403
# 原因: 在外,使用自身手机热点,作为代理、 这是因为 PyPI 禁用了对 API 的非 HTTPS 访问
# 修正: 命令: pip install xxxx -i https://pypi.python.org/simple/
simple RNN缺陷: 只适合短期记忆、前期记忆会被稀释!!!
网络层数增加、梯度消失导致的!!!
具体:模型训练时、用于反向传播、优化参数的梯度、深层往浅层越来越小导致的!!
梯度越小、参数仍然更新,就相当于在训练时、状态h4不会随着第一个输入变化≈≈没有关系了....不合理!!!相当于已经忘记了!!!
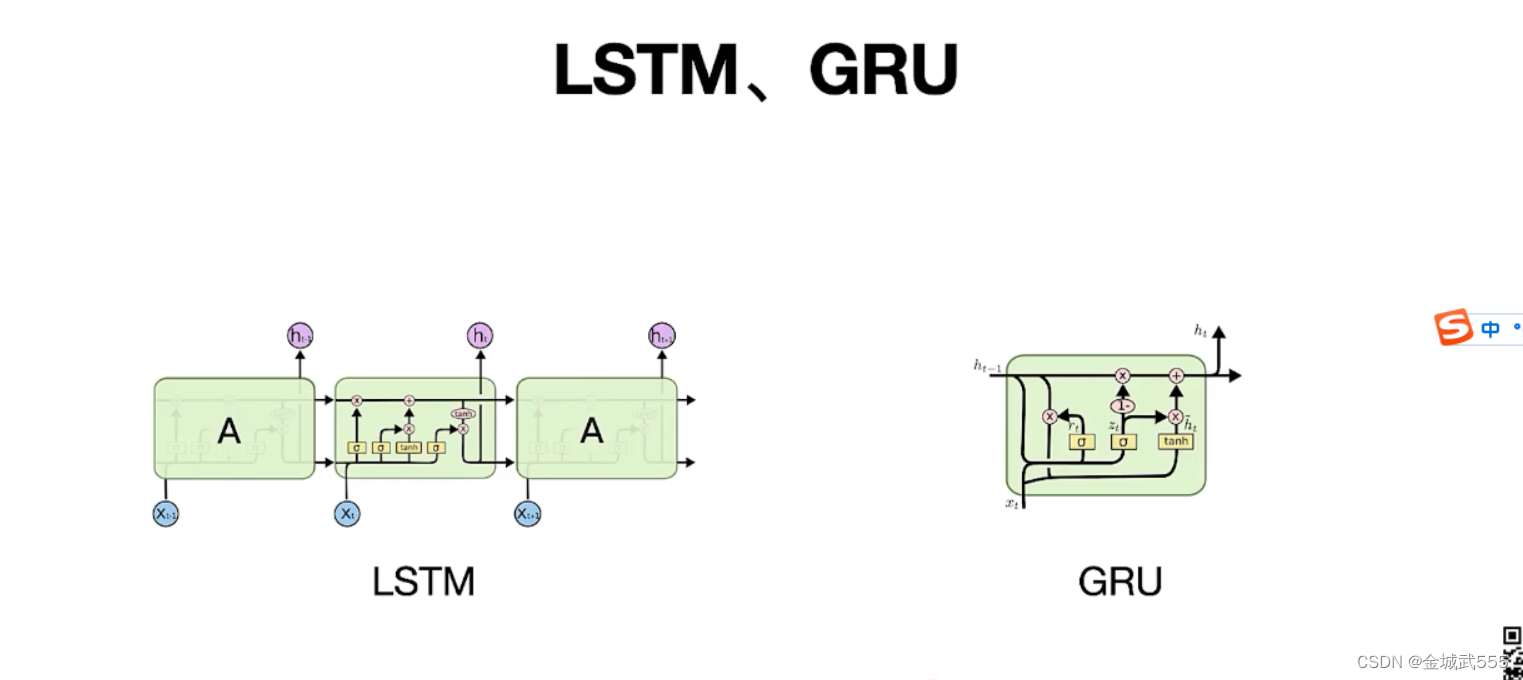
为解决simple RNN的遗忘问题: 引入RNN的变种:LSTM、GRU....避免了梯度消失问题、记忆能力更强些!!!
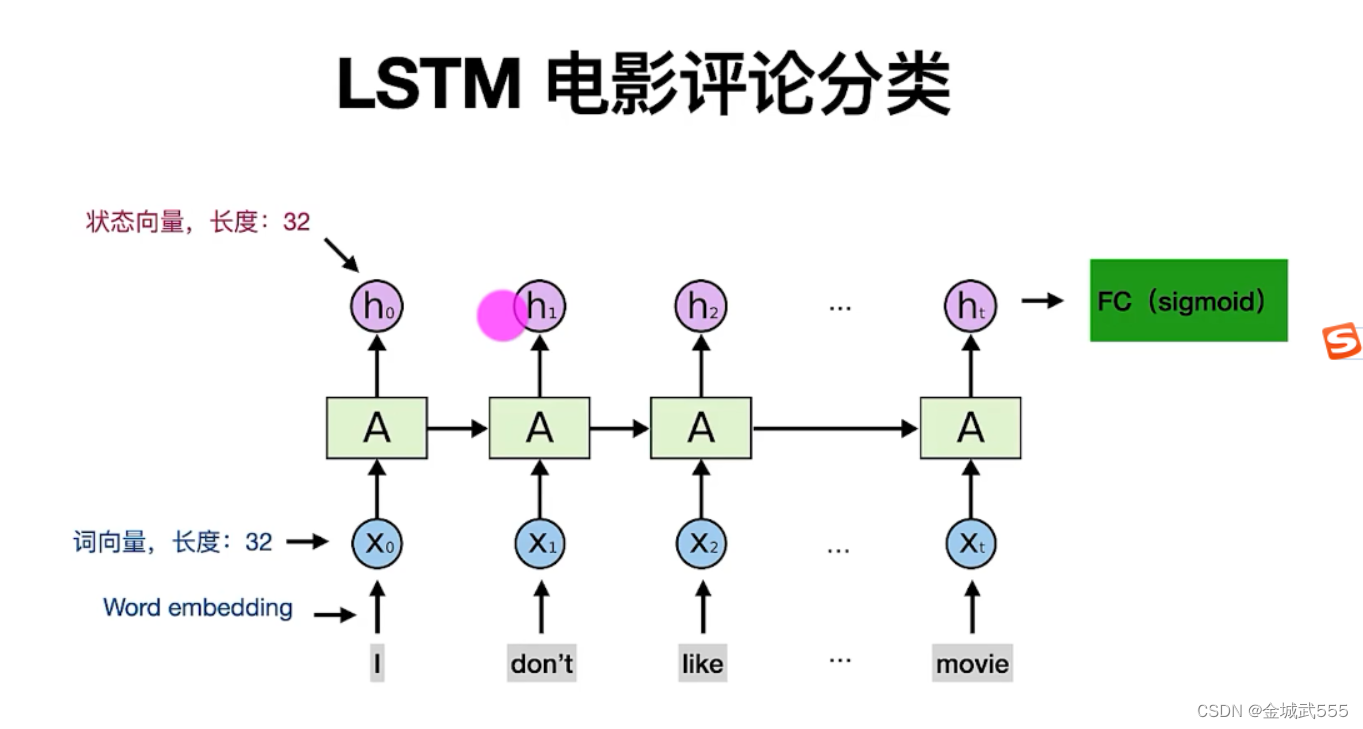
LSTM:长短期记忆, 与RNN对比、LSTM有4个参数矩阵!!!
LSTM的核心: 一条传输带,向量c,过去的信息经过传输带传送!! 避免消失问题!!!
LSTM的遗忘门: a经过sigmoid激活函数,变成压到【0,1】,选择性通过,0阻挡!其他选择性通过!!
LSTM的输入门: 类似simple-RNN
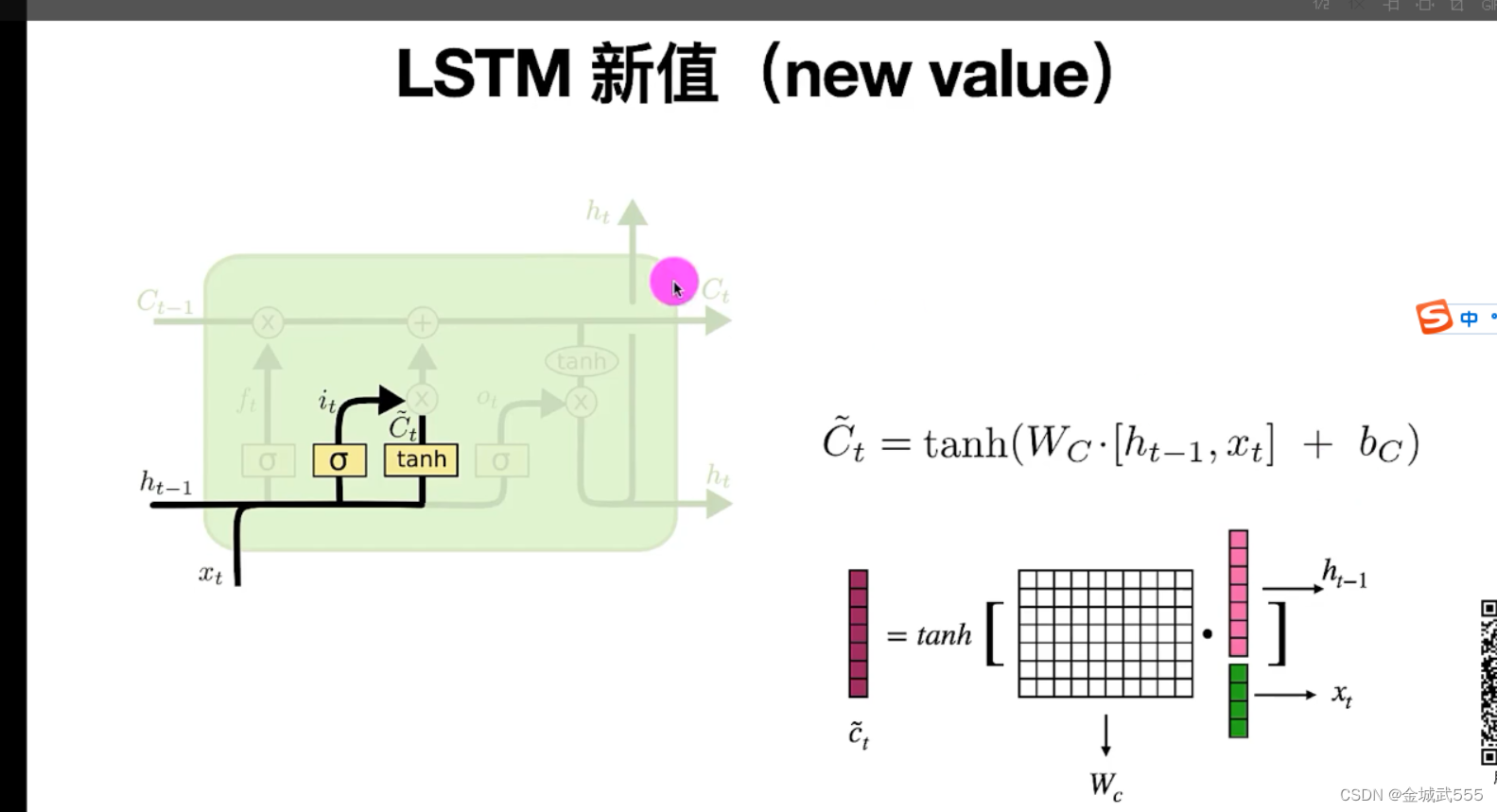
LSTM的新值c~t: 就是用 tan h,替代了 sigmoid, 双曲正切:tanh = sinh/cosh ... 【-1,1】
更新计算,传输带,值 ct: ct = ft *c(t-1) + it * c~t
# 遗忘门筛掉一些信息 + 加上一些新的东西!!
LSTM的输出门:
ot类似于遗忘门的 sigmoid 计算: 参数矩阵 A ,另外的训练得来..
ht = ot * tanh(c~t) # 获取状态向量...
更新后的,ht有两个流向: 1、流向传送 2、流向输出
LSTM的组成: 1、遗忘门 2、输入门 3、新值 4、输出门!!!
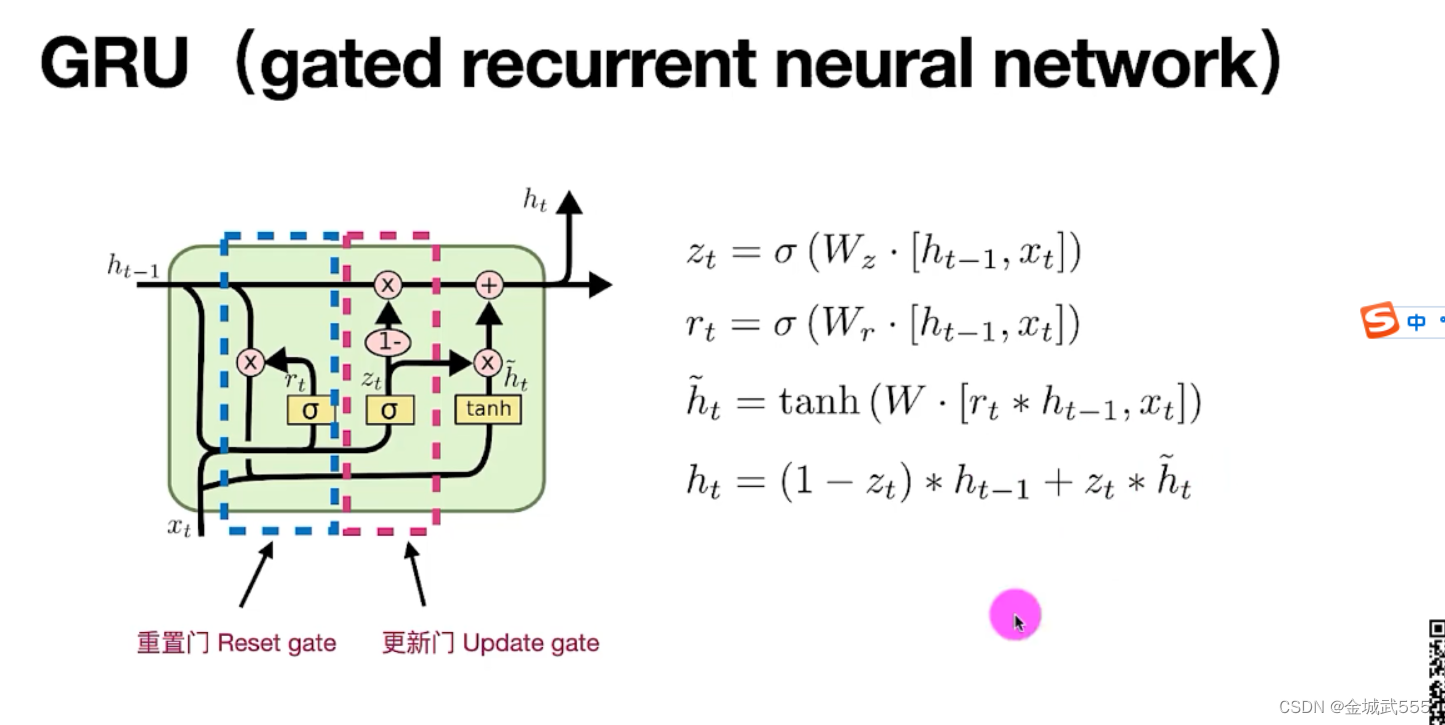
GRU: 类似于LSTM、
GRU: 1、更新门、计算类似遗忘门 2、重置门、类似更新门计算
# 编写代码:
simple-RNN,先编写出来,
LSTM、用LSTM,替代了simpleRNN即可!!!
# 数据预处理:: 中心裁剪、画面缩放、通道转换、用inception_resnetv2 提取特征、保留所需的序列帧数...搭建RNN网络模型、训练数据、保存在本地磁盘...
# 测试:: 拷贝上述预处理函数、调用,加载训练好的权重,随机选取视频测试、仅仅用RNN作为测试、transformer简单了解、并不亲自搭建,
# 效果:: RNN 效果也不错、但就结果而言,transformer置信度conf 极高,不愧是加入了位置编码的transformer,置信度很多都是100%的!
# 有一点注意事项: transformer的self.attention,自注意力机制,需要 tensorflow 2.5以后版本才有,尽量下载 tf 2.5,tf2.6及之后的版本!
# 词语的向量化: 词->设置向量长度32->乘上参数矩阵A->获得状态向量h

















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









