







 本文介绍了在处理JSON字符串时如何解析Unicode字符,包括理解Unicode码点、编码规则,特别是UTF-8的编码方式。详细讨论了如何将4位十六进制数转换为码点,并编码为UTF-8,同时讲解了在实现过程中遇到的问题,如代理对的处理。通过实例展示了如何将码点U+20AC(欧元符号)编码为UTF-8。
本文介绍了在处理JSON字符串时如何解析Unicode字符,包括理解Unicode码点、编码规则,特别是UTF-8的编码方式。详细讨论了如何将4位十六进制数转换为码点,并编码为UTF-8,同时讲解了在实现过程中遇到的问题,如代理对的处理。通过实例展示了如何将码点U+20AC(欧元符号)编码为UTF-8。
解析思路:
json字符串中/uXXXX是用十六进制表示码点U+0000 至 U+FFFF。
我们需要:
- 将4位十六进制整数解析成码点(Unicode字符)。
- 将码点编码成UTF-8,该过程可能要处理代理对。
实现过程及遇到的问题;
1. Unicode相关知识:
Unicode及编码规则介绍
Unicode是为了解决ASCII码表示字符数过少,各地区编码方式不同这两个问题而出现,Unicode为每个字符分配唯一的码点,就像身份证号码一样,码点的表示是U+XXXXXX,X表示十六进制数。
码点的取值范围是U+0000 - U+10FFFF,理论大小为10FFFF+1= 110000(十六进制,+1是因为从0开始)。110000第二个1表示164=65536,第二个1表示有16个164,总共有(16+1)个164码点。Unicode将这17个部分分成17个平面,第一个平面是BMP(基本多语言平面),其他的是增补平面。
Unicode的编码规则常见的有UTF-8、UTF-16 和 UTF-32,每种UTF会把码点存储为一至多个编码单元,其中UTF-8、UTF-16是可变长度编码。
UTF实现可变长度编码
在BMP平面挖出两份1024个编码位置,一个做高代理区(D800–DBFF),一个做低代理区(DC00–DFFF),这两个区组成的二维表格有10241024 = 16 * 65536个新的编码(8到B是4,FF-00+1=256, 4256=1024),刚好可以覆盖后面的16个平面。
UTF-8对码点的编码
UTF-8是可变长编码,采用保留高位的方法避免了解析歧义的问题,比如将1编码成a,将12编码成b,程序遇到1的时候就不知道该选择哪个进行编码了,如图,多字节是不会包含一字节的模式,缺点是编码空间变少了。
编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为 0,剩余的 N - 1个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
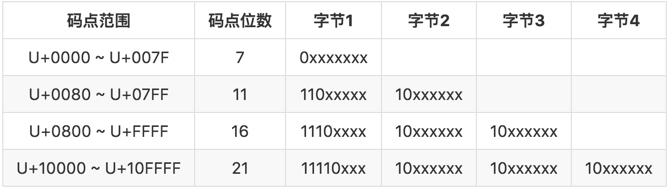
对于Unicode编码就是先确定它的范围,知道是几字节的,然后化成二进制对应的码点位数,不足位在前面补0,再填入字节里的xxx里。
我们举一个例子解析多字节的情况,欧元符号 € → U+20AC:
- U+20AC 在 U+0800 ~ U+FFFF 的范围内,应编码成 3 个字节。
- U+20AC 的二进位为 10000010101100
- 3 个字节的情况我们要 16 位的码点,所以在前面补两个 0,成为 0010000010101100
- 按上表把二进位分成 3 组:0010, 000010, 101100
- 加上每个字节的前缀:11100010, 10000010, 10101100
- 用十六进位表示即:0xE2, 0x82, 0xAC
补充阅读:
Unicode详解
彻底弄懂Unicode编码
其他人实现解析Unicode经历
实现细节
-
lept_parse_hex4():将字符解析为码点
将4位16进制数表示的字符解析位码点, 成功时返回解析以后的文本指针,失败返回 NULL。u用来保存解析的结果。每次解析一个16进制字符时会先向左移四位,这样才能把解析到的数字存入u中。
如何解析单个16进制字符: 分三种情况,0-9的字符直接转换成int型数字存入u,a-f的话ch-(‘a’ - 10)…

-
lept_encode_utf8(); 把码点编码成 UTF-8,写进缓冲区。
首先要理解UTF-8的编码规则:以8位为一个单位,按照码点的范围将码点的二进位拆分成1-4个字节。
所以过程就很简单了,确定码点所处范围,将码点二进制表示填进码点范围里的xxx就好,不足位在码点左边补0.
实现是从左边开始填充,用右移运算符切掉右边多余二进制数字,与运算符切掉左边多余数字来填充。
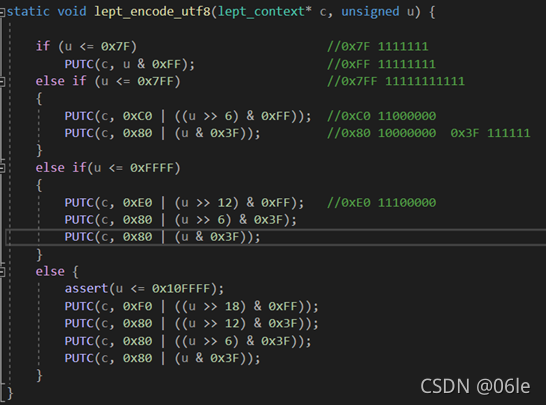
-
刚开始困惑在范围3里的字节2是怎么填充的,如果u为0xFFFF,右移6位后和0x80进行或运算,不会把0x80前面的0填满吗? 如下,可以看到u即使右移6位后还是比0x80大。
0xFFFF 1111111111
0x80 10000000
结果 1111111111
后面经过测试,发现关键点在 ((u >> 6) & 0x3F), 这里会把u右移6位后的结果切成只剩后面6位,与运算符是保留最小运算数的位数来进行运算,而或运算符是保留最大运算数的位数来进行运算的。
int i = 7, s = 2;
cout << (i | s); //7
cout << (i & s); //2
所以这个函数填充的过程是用右移运算符切掉右边多余的位数,用与运算符保留中间部分,去掉左边多余部分。
解析字符串的过程:当解析lept_parse_hex4()的结果属于U+D800 至 U+DBFF区间,该结果是一个高代理项,那么该Unicode属于BMP(基本多文种平面)以外的字符,继续解析低代理项,如果得到了,就用公式
codepoint = 0x10000 + (H − 0xD800) × 0x400 + (L − 0xDC00) 将高,低代理项转换成码点。
犯的错误:
<< 和 <<=运算符的区别:
左移运算符是返回一个临时结果,左移等于运算符是在原来变量上进行改动。
int i = 2;
cout << (i << 1) << endl; //4
cout << i << endl; //2
cout << (i <<= 1) << endl; //4
cout << i << endl; //4
总结
- 了解了Unicode字符集和编码规则。

















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









