










二分查找:
二分查找的思路:我们设定一个初始的L和R,保证答案在[L,R]中,当[L,R]中不止有一个数字的时候,取区间的中点M,询问这个中点和答案的关系,来判断答案是M,还是位于[L,M-1]中,还是位于[M+1,R]中。
二分查找时间复杂度的计算方法:
比如,在猜数字的游戏中,假设我们一开始有n个数字。每次把剩余数字的区间分成两半,直到xx次后只剩下最后一个数字,就是我们想要的答案啦。 计算公式如下:
n * 1/(2^x) = 1n∗1/(2x)=1
xx次后只剩下最后一个数字
x = log_2(n)x=log2(n)
那么,xx的值就是log n咯
总结
现在我们来看一下二分查找这个神奇的算法:
-
二分查找的原理:每次排除掉一半答案,使可能的答案区间快速缩小。
-
二分查找的时间复杂度:log_2(n)log2(n),因为每次询问会使可行区间的长度变为原来的一半。
-
我们再来看一下二分查找的思路:我们设定一个初始的L和R,保证答案在
[L,R]中,当[L,R]中不止有一个数字的时候,取区间的中点M,询问这个中点和答案的关系,来判断答案是M,还是位于[L,M-1]中,还是位于[M+1,R]中。 -
二分查找的伪代码如下:
int L = 区间左端点; int R = 区间右端点; // 闭区间 while( L < R ) { // 区间内有至少两个数字 int M = L+(R-L)/2; // 区间中点 if( M是答案 ) 答对啦; else if( M比答案小 ) L = M+1; else R = M-1; // M比答案大 } // 若运行到这里,因为答案一定存在,所以一定有L==R,且L是答案
总结
二分查找可能会遇到哪些边界情况?为什么示例代码能完美的解决这些边界情况?
答:总是可以通过问题转换写出满足L < R的优美代码。
- 二分查找伪代码
while( L < R ) {
int M = L + (R - L)/2;
if( 答案在[M + 1,R]中 ) { // 思考一下,什么情况下能够说明“答案在[M+1,R]中”
L = M + 1;
} else { // 答案在[L,M]中
R = M;
}
}-
写二分查找遇到了死循环,考虑是不是遇到了“差一点”问题。
-
如果代码中是用的
L = M,把L不断往右push,那么M向上取整(M = L + (R - L + 1)/2); -
如果代码中是用的
R = M,把R不断往左push,那么M向下取整(M = L + (R - L)/2)。
-
-
代码示例:
- 有一个从小到大排好序的数组,你要找到第一个大于等于x的数字,应该怎么做?
输入n,x,以及一个长度为n的数组a(已经从小到大排好序了)
输入样例:
9 4
2 3 3 3 3 4 4 4 4
- 代码样例:
#include <iostream>
using namespace std;
int n, x, a[100000];
int main() {
cin >> n >> x; // n为数组元素个数,x为
// 输入数组
for( int i = 0; i < n; ++i )
cin >> a[i];
// 考虑数组中不存在大于等于x的数字的情况
if( x > a[n-1] ) {
cout << -1 << endl;
return 0;
}
// 二分查找
int L = 0, R = n-1; // 数组下标从0到n-1,闭区间
while( L < R ) { // 当区间中至少有两个数字的时候,需要继续二分
int M = L + (R - L) / 2; // 求出区间中点
if( a[M] < x ) { // 答案一定出现在[M+1,R]中
L = M + 1;
} else { // a[M] >= x,答案一定出现在[L,M]中
R = M;
}
}
// 此时L == R,a[L]就是第一个大于等于x的数字
if ( a[L] == x) {
cout << L << endl; // 如果答案存在,则输出答案
} else {
cout << -1 << endl; // 如果答案不存在,则输出-1
}
return 0;
}-
最后,再回顾一下在上一知识点中,我们推导了二分查找的时间复杂度。只有当我们询问区间中点的时候,我们才能让可行区间的长度以最快的速度变短——每次大约变为原来长度的一半,所以二分查找的时间复杂度是log_2(n)log2(n)。
二分查找时间复杂度的计算方法:
比如,在猜数字的游戏中,假设我们一开始有n个数字。每次把剩余数字的区间分成两半,直到xx次后只剩下最后一个数字,就是我们想要的答案啦。 计算公式如下:
n * 1/(2^x) = 1n∗1/(2x)=1
xx次后只剩下最后一个数字
x = log_2(n)x=log2(n)
那么,xx的值就是log_2(n)log2(n)咯

练习题:
#include <bits/stdc++.h>
using namespace std;
int a[100010];
int main() {
int n, x;
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i];
cin >> x;
int pos = lower_bound(a + 1, a + n + 1, x) - a;
if (a[pos] != x)
cout << "not find" << endl;
else
cout << pos << endl;
return 0;
}二分查找算法的应用范围:
如果我们想要在一个数组上进行二分查找,那么这个数组必须是有序的,不管是升序还是降序,它必须是有序的。
为什么呢?
注意二分查找的本质是什么:通过比较数组中间那个值和我们要求的值的关系,来判断出“答案不可能出现在数组的某一半”,从而让我们的查找范围缩小为原来的一半。
这也就是为什么我们要求数组中的元素是满足单调性的:只有这样,我们才能保证当a[M]不满足条件的时候,它左边(或者右边)的所有元素都不满足条件。
所以:
-
要进行二分,数组必须是有序的。
-
基本上所有可以比较的数据都可以进行二分查找。
- 比如:日期、字符串、二维数组
-
如果数据可以方便的计算“中点”,那么就可以在大区间上二分查找指定的数据(比如日期)
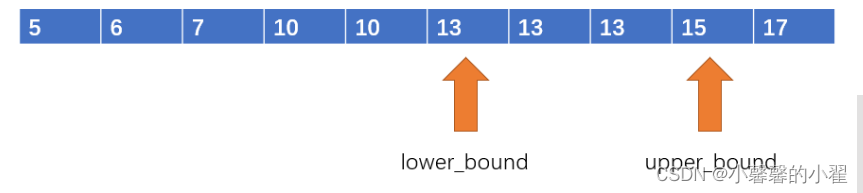
lower_bound的用途是:在指定的升序排序的数组中,找到第一个大于等于x的数字。
upper_bound的用途是:在指定的升序排序的数组中,找到第一个大于x的数字。
这两个函数会返回对应数字的指针(或者是迭代器)。
int a[100000], n;
cin >> n;
for( int i = 0; i < n; ++i )
cin >> a[i];
sort(a, a + n);
int *p = lower_bound(a, a + n, 13); // 第一个大于等于13的数字
int *q = upper_bound(a, a + n, 13); // 第一个大于13的数字假如我们使用lower_bound和upper_bound二分查找同一个数字13,容易发现,我们得到的两个指针构成了一个左闭右开区间,这个区间里全部都是数字13。
巧妙地运用这两个函数,可以完成所有常见的二分查找操作:
- 找到第一个大于等于x的数字
- 找到第一个大于x的数字
- 找到最后一个等于x的数字
- 查找数组中是否有数字x
- 查询数组中有几个数字x
- 找到最后一个小于x的数字
- ……
我们总结一些二分查找的常见应用:
-
lower_bound和upper_boundlower_bound的用途是:在指定的升序排序的数组中,找到第一个大于等于x的数字。upper_bound的用途是:在指定的升序排序的数组中,找到第一个大于x的数字。使用
lower_bound和upper_bound可以帮我们解决绝大多数二分查找问题。这两个函数会返回对应数字的指针。示例代码如下:
int a[100000], n;
cin >> n;
for( int i = 0; i < n; ++i )
cin >> a[i];
sort(a, a + n);
int *p = lower_bound(a, a + n, 13); // 第一个大于等于13的数字
int *q = upper_bound(a, a + n, 13); // 第一个大于13的数字假如我们使用
lower_bound和upper_bound二分查找同一个数字13,容易发现,我们得到的两个指针构成了一个左闭右开区间,这个区间里全部都是数字13。
巧妙地运用这两个函数,可以完成所有常见的二分查找操作:
- 找到第一个大于等于x的数字
- 找到第一个大于x的数字
- 找到最后一个等于x的数字
- 查找数组中是否有数字x
- 查询数组中有几个数字x
- 找到最后一个小于x的数字
-
二分法可以求方程的近似解。
-
二分法可以用来优美地实现离散化操作。
-
在double上二分时,尽量使用固定次数二分的方法。

















 5686
5686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











