







这期博客咱们来学习一下Shufflenet系列轻量级卷积神经网络,Shufflenet v1 、Shufflenet v2。
本博客代码可以直接生成训练集和测试集的损失和准确率的折线图,便于写论文使用。
首先学习一下,Shufflenet v1网络:
论文下载链接:
Shufflene系列轻量级卷积神经网络由旷世提出,也是非常有趣的轻量级卷积神经网络,它提出了通道混合的概念,改善了分组卷积存在的问题,加强各组卷积之间的特征交互和信息交流,在改善模型的特征提取方式的同时,增强特征提取的全面性,如下图所示:

当然上面说的很抽象,图像也很抽象,具体的实现过程如下图所示:
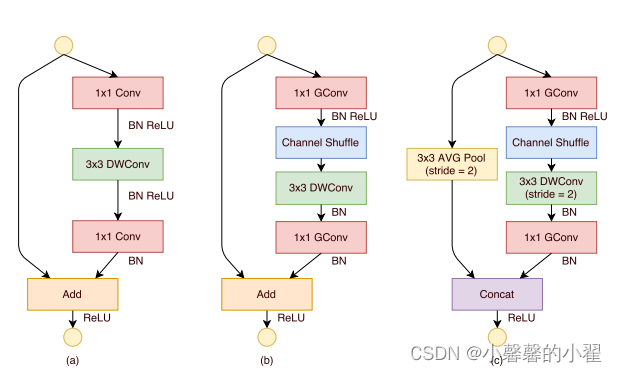
其他的网络都是用分组卷积来进行特征提取,但是这样各类组别之间的特征没有交互,增大了计算量,shufflenet通过对channel shuffle,将各组之间提取的特征进行交互,减少计算量,同时使用深度可分离卷积,减轻模型体量的同时,增强模型的鲁棒性和抗干扰性。具体的网络参数如下图所示:
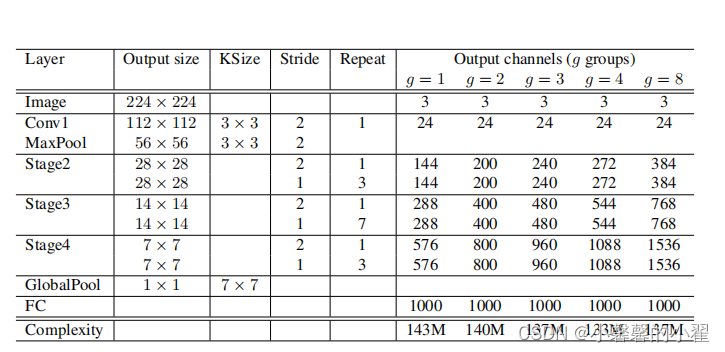
简单来说 shufflenet v1的主要改进就是:
1、增加了channel shuffle模块,
2、将所有的1*1卷积换成分组卷积GConv
shufflenet v1的代码使用没有什么意义,这里不公开,只公开shufflenet v2的代码。接下来简单讲述shufflenet v2。
其次来学习一下,Shufflenet v2网络:
论文下载地址:https://arxiv.org/pdf/1807.11164.pdf
在 shufflenet v1,通道混合的基础上增加了通道分离,与之前的不同,Shufflenet v2先使用通道分离,将网络分为几个分支,最后再使用通道混合,同时降低网络的分支,分组卷积的数目设计更加合理,减少逐点运算等等,具体的网络结构如下图所示。
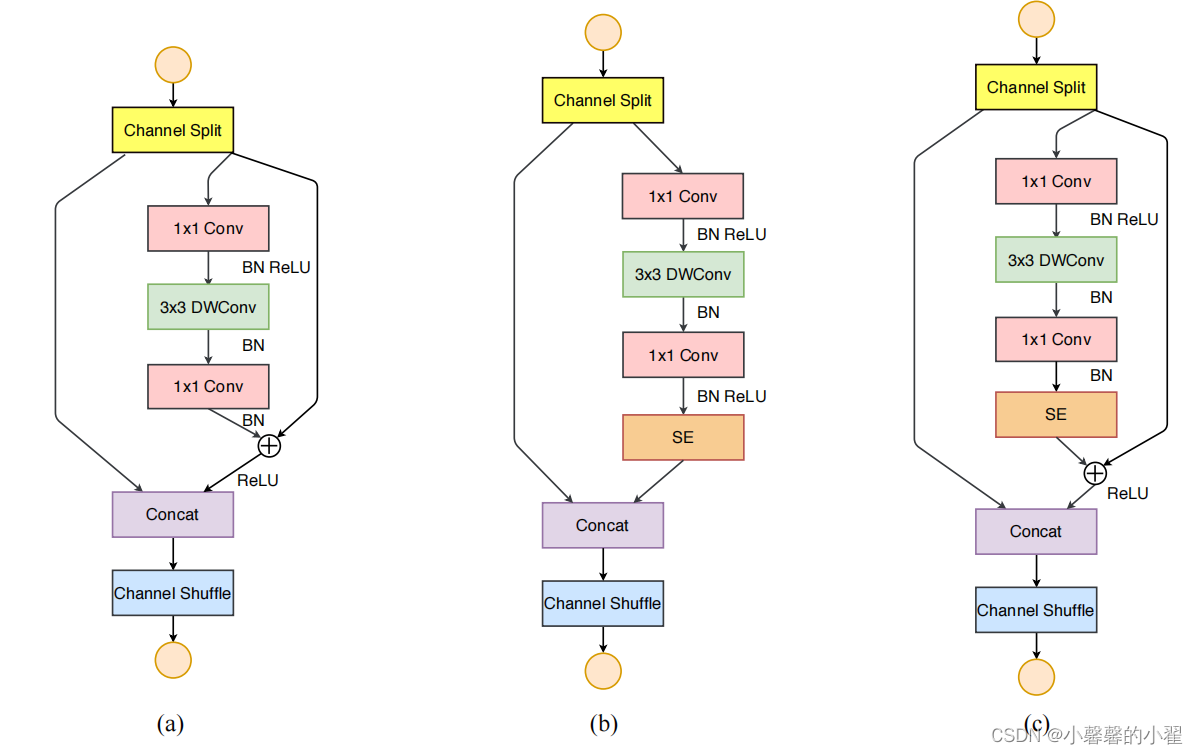
详细的网络参数如下图所示:
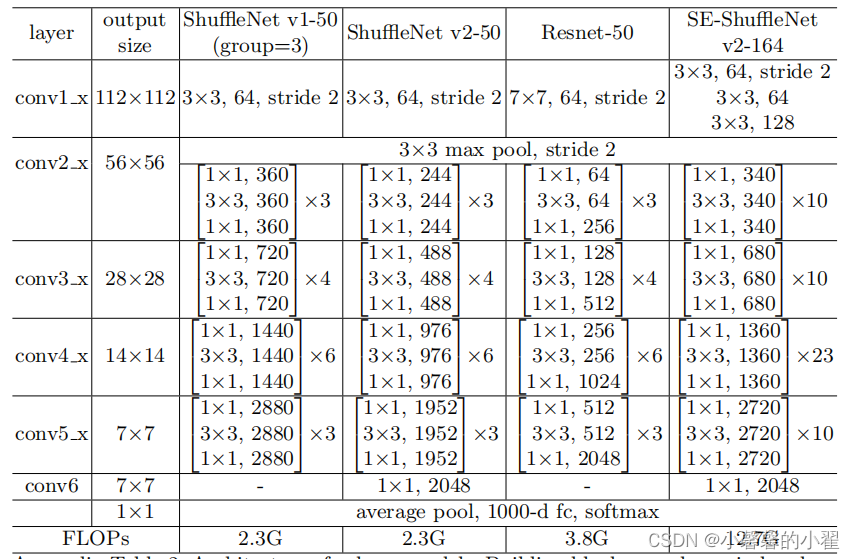
下面开源代码
Shufflenet v2代码:
训练代码:
import torch
from torch import nn, Tensor
import torchvision.models
from torch.nn import functional as F
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from typing import Callable, List, Optional
from functools import partial
from typing import List, Callable
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset=train_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) #输出训练集长度看一下,相当于看看有几张图片
print(test_size) #输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset=test_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行测试
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
shufflenet_v2 = shufflenet_v2_x1_0(num_classes=2) #将模型命名为shufflenet_v2,这里num_classes是数据集的种类,我用的猫狗数据集两类,所以等于2 你设置成你数据集的种类即可
#上面用的是mobilenet_v3_large,如果想用mobilenet_v3_small,直接把上面的mobilenet_v3_large替换成mobilenet_v3_small即可
shufflenet_v2.to(device)
print(shufflenet_v2.to(device)) #输出模型结构
test1 = torch.ones(64, 3, 120, 120) # 测试一下输出的形状大小 输入一个64,3,120,120的向量
test1 = shufflenet_v2(test1.to(device)) #将向量打入神经网络进行测试
print(test1.shape) #查看输出的结果
epoch = 1 # 迭代次数即训练次数
learning = 0.0001 # 学习率
optimizer = torch.optim.Adam(shufflenet_v2.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0 #
train_accuracy = 0.0 #训练集的准确率初始设为0
shufflenet_v2.train() #将模型设置成 训练模式
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data #将data 分位 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs = shufflenet_v2(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
loss1 = loss(outputs, target.to(device)) # 计算神经网络输出的结果outputs与图片真实标签target的差别-这就是我们通常情况下称为的损失
outputs = torch.argmax(outputs, 1) #会输出10个值,最大的值就是我们预测的结果 求最大值
loss1.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss = train_loss + loss1.item() #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0) #
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i + 1, train_loss / train_num, #输出训练情况
train_accuracy / train_num))
train_loss_all.append(train_loss / train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num)#训练集的准确率
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
shufflenet_v2.eval() #将模型调整为测试模型
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs = shufflenet_v2(img.to(device))
loss2 = loss(outputs, target.to(device)).cpu()
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + loss2.item()
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
#下面的是画图过程,将上述存放的列表 画出来即可,分别画出训练集和测试集的损失和准确率图
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epoch), train_loss_all,
"ro-", label="Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-", label="test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch), train_accur_all,
"ro-", label="Train accur")
plt.plot(range(epoch), test_accur_all,
"bs-", label="test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(shufflenet_v2, "shufflenet_v2.pth")
print("模型已保存")
预测代码:
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
from typing import Callable, List, Optional
from torch import nn, Tensor
from torch.nn import functional as F
image_path = "1.jpg"#相对路径 导入图片
trans = transforms.Compose([transforms.Resize((120 , 120)),
transforms.ToTensor()]) #将图片缩放为跟训练集图片的大小一样 方便预测,且将图片转换为张量
image = Image.open(image_path) #打开图片
# print(image) #输出图片 看看图片格式
image = image.convert("RGB") #将图片转换为RGB格式
image = trans(image) #上述的缩放和转张量操作在这里实现
# print(image) #查看转换后的样子
image = torch.unsqueeze(image, dim=0) #将图片维度扩展一维
classes = ["cat" , "dog" ] #预测种类,我这里用的猫狗数据集,所以是这两种,你调成你的种类即可
def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
#以上是神经网络结构,因为读取了模型之后代码还得知道神经网络的结构才能进行预测
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #将代码放入GPU进行训练
print("using {} device.".format(device))
model = torch.load("shufflenet_v2.pth") #读取模型
model.eval() #关闭梯度,将模型调整为测试模式
with torch.no_grad(): #梯度清零
outputs = model(image.to(device)) #将图片打入神经网络进行测试
# print(model) #输出模型结构
# print(outputs) #输出预测的张量数组
ans = (outputs.argmax(1)).item() #最大的值即为预测结果,找出最大值在数组中的序号,
# 对应找其在种类中的序号即可然后输出即为其种类
print("该图片的种类为:",classes[ans])
# print(classes[ans])网络结构搭建部分注释的很详细,有问题朋友欢迎在评论区指出,感谢!
不懂我代码使用方法的可以看看我之前开源的代码,更为详细:手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_pytorch更换数据集需要改代码吗_小馨馨的小翟的博客-CSDN博客
本代码使用的数据集是猫狗数据集,已经分好训练集和测试集了,下面给出数据集的下载链接。
链接:https://pan.baidu.com/s/1_gUznMQnzI0UhvsV7wPgzw
提取码:3ixd
Shufflenet v2代码下载链接如下:
链接:https://pan.baidu.com/s/1Sni3-uqVQ6M7UUJwrapVJw
提取码:o1l8
















 1988
1988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











