







本文将介绍用于衡量知识图谱嵌入(Knowledge Graph Embedding,KGE)模型性能中最常用的几个指标:MRR,MR,HITS@1,HITS@3,HITS@10。
一、MRR
MRR的全称是Mean Reciprocal Ranking,其中Reciprocal是指“倒数的”的意思。具体的计算方法如下:
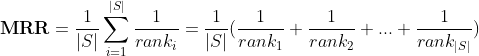
其中S是三元组集合,|S|是三元组集合个数,rank_i是指第i个三元组的链接预测排名。该指标越大越好。例如,对于三元组(Jack,born_in,Italy),链接预测的结果可能是
s p o score rank
Jack born_in Ireland 0.789 1
Jack born_in Italy 0.753 2 *
Jack born_in Germany 0.695 3
Jack born_in China 0.456 4
Jack born_in Thomas 0.234 5
那么,三元组(Jack,born_in,Italy)的链接预测排名则是2.
个人理解:平均排名的倒数,是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
二、MR
MR的全称是Mean Rank。具体的计算方法如下:
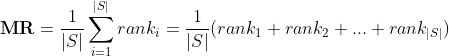
上述公式涉及的符号和MRR计算公式中涉及的符号一样。该指标越小越好。
个人理解:首先 对于每个 testing triple,以预测tail entity为例,我们将(h,r,t)中的t用知识图谱中的每个实体来代替,然后通过fr(h,t)函数来计算分数,这样我们可以得到一系列的分数,之后按照 升序将这些分数排列。
然后,我们需要知道的是f函数值是越小越好,那么在上个排列中,排的越前越好。
现在重点来了,我们去看每个 testing triple中正确答案也就是真实的t到底能在上述序列中排多少位,比如说t1排100,t2排200,t3排60…,之后对这些排名求平均,Mean rank就得到了。
另外,mean rank评估指标的 原始排名raw和过滤排名filt
raw和filter区别就是filter在测试时候剔除了在训练时出现过的样本得到的结果,因为测试时候是替换所有实体来进行排名,而训练集中出现的实体排名靠前也可以接受,所以剔除后得到filter结果
三、HITS@n
该指标是指在链接预测中排名小于n的三元组的平均占比。具体的计算方法如下:
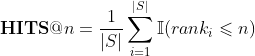
其中,上述公式涉及的符号和MRR计算公式中涉及的符号一样,另外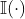 是indicator函数(若条件真则函数值为1,否则为0)。一般地,取n等于1、3或者10。该指标越大越好。
是indicator函数(若条件真则函数值为1,否则为0)。一般地,取n等于1、3或者10。该指标越大越好。
个人理解:如Hit10,还是按照上述进行f函数值排列,然后去看每个testing triple正确答案是否排在序列的前十,如果在的话就计数+1。最终 排在前十的个数/总个数 就是Hit@10
四、从论文上发现的观点
MRR和HITS@10是两个重要指标,不可缺少。MR则不被认为是一个好的指标。

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









