






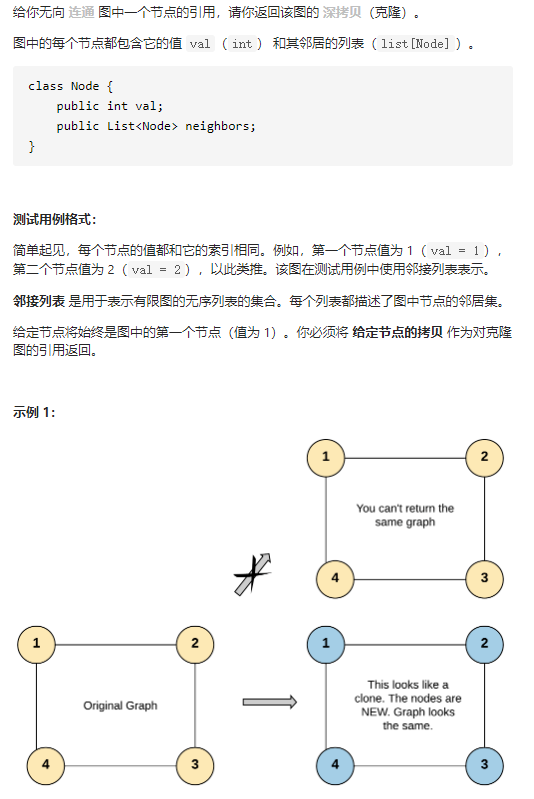

解题思路
深度优先遍历,并用一个Set记录哪些节点已经遍历过(克隆过),映射关系源节点->克隆节点
如果节点为null则返回null
如果该节点已经克隆过, 返回它的克隆结果
否则新创建一个节点new Node(node.val),并将该节点和克隆节点记录进Set
然后遍历该节点的邻接表,将递归表中的节点作为参数递归本方法,将返回结果添加到克隆节点的邻接表 cloneNode.neighbors.add(cloneGraph(neighbor))
最后返回最开始的节点的克隆节点
代码
class Solution {
Map<Node, Node> visited = new HashMap<>();
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
// 如果该节点已经克隆过, 返回它的克隆结果
if (visited.containsKey(node)) {
return visited.get(node);
}
Node cloneNode = new Node(node.val);
// 记录已经克隆过的节点
visited.put(node, cloneNode);
// 添加邻接列表时也要克隆邻接节点, 而不是单纯克隆邻接列表
for (Node neighbor : node.neighbors) {
cloneNode.neighbors.add(cloneGraph(neighbor));
}
return cloneNode;
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









