







28.实现strStr()
题目描述:
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例一:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例二:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 104
haystack 和 needle 仅由小写英文字符组成
解题思路:
-
关键词提取:第一个匹配项下标、一部分
-
解法一:
- 关键词转换,题目是要找一个字符串是否是另一个字符串的字串。
- 假如是的话,返回第一个字符的下标。
- 假如不是的话,返回-1。
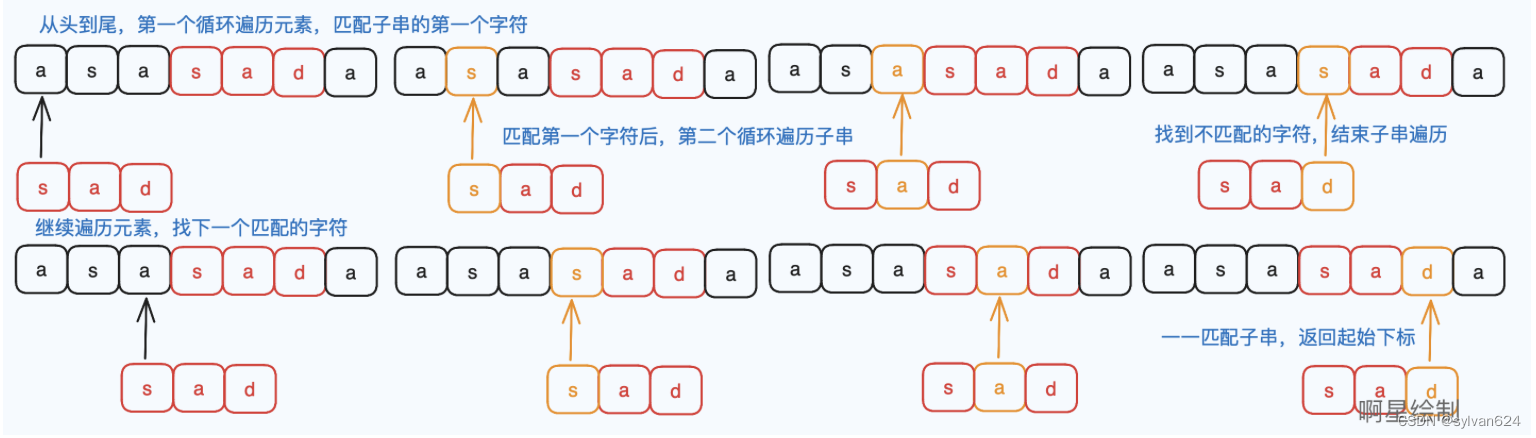
- 暴力解法:
- 两个for循环,一个负责遍历目标字符串,找到第一个字符与待匹配子字符串第一个字符相等的下标,记录当前下标值。
- 另一个负责遍历当前下标往后的字符是否一一匹配,若匹配,就返回当前下标。否则,从当前下标开始,重新遍历符合要求的首字符。
- 绘图如下:
代码如下:
- 关键词转换,题目是要找一个字符串是否是另一个字符串的字串。
class Solution {
public:
int strStr(string haystack, string needle) {
// 定义返回的下标值
int index = -1;
// 遍历目标字符串
for(int i = 0; i < haystack.size(); i++) {
// 找到与子串匹配的第一个字符
if(haystack[i] == needle[0]) {
// 记录当前下标
index = i;
// 开始同时遍历目标字符串与子串
for(int j = 1; j < needle.size(); j++) {
// 若出现不匹配的字符,下标复位至-1,结束子串遍历
if(haystack[i + j] != needle[j]) {
index = -1;
break;
}
}
// 若子串遍历后,完全匹配,返回匹配的第一个下标
if(index != -1) {
return index;
}
}
}
// 若没有找到匹配的子串,返回-1
return index;
}
};
-
解法二:
- KMP算法:
- 在暴力解法的基础上,可以做剪枝优化。
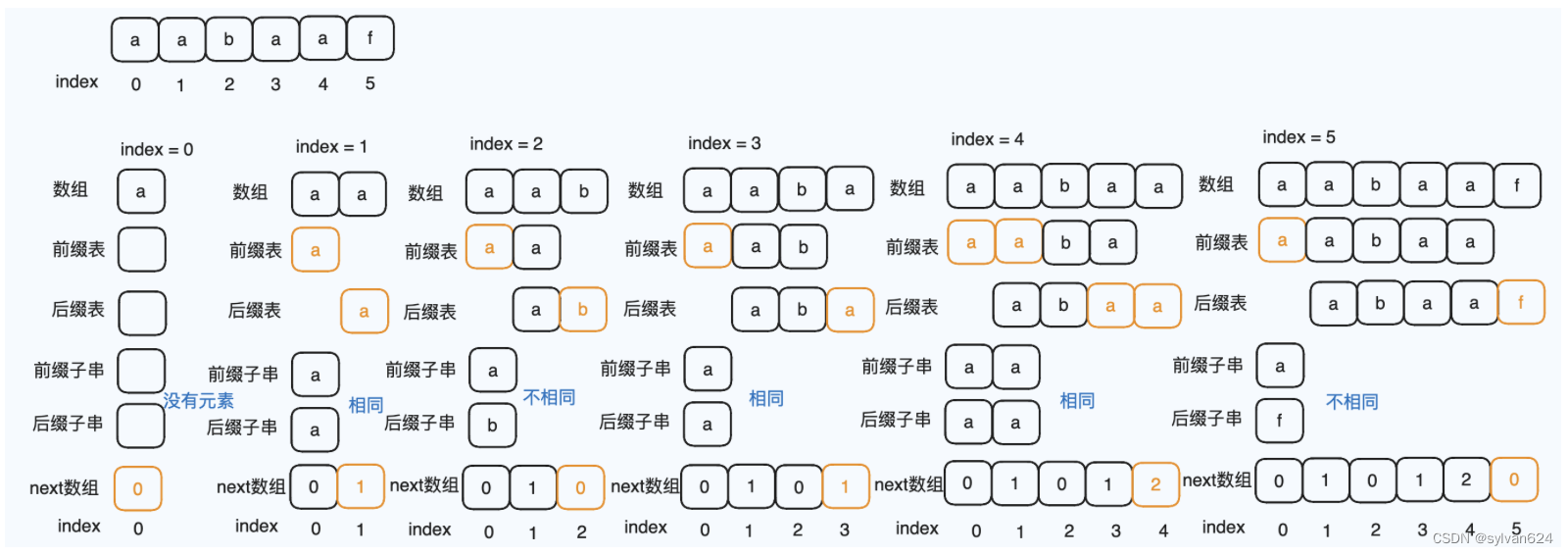
- 在检索的时候,检索到不匹配的子串时,不需要回到目标字符串检索的起始位置重新开始遍历,而是可以基于子串的重复性,从上次遍历的其中某个位置开始遍历,这个位置需要计算。
- 计算这个位置的方法叫做KMP算法。基于子串的重复性,对每个字符都记录一个若不匹配,需要回退的下标位置。要建立一个前缀表prefix table来记录该位置,也可称为next数组。
- 采用前缀表的原因:
- 和数组的遍历顺序一致,都是从前往后遍历,在回退的时候,往前回退符合应用场景,前缀表更适合。
- 采用next数组的时候,要解决四种情况:
- 初始化
- 前后缀不同
- 前后缀相同
- next数组当前位置保存的回退下标,是在下一个位置遍历到前后缀不同时生效
- 举一个例子来说明:
- 目标字符串aabaabaaf
- 子字符串aabaaf
- 在目标字符串中,检索是否出现过子字符串。也就是找一个连续的子串。
- 再次强调前缀表的作用:是当前位置匹配失败,前缀表会协助找到之前可以匹配的位置,重新匹配。
- 所以,前缀表记录的是:在下标区间[0,i]的字符串中,有多大长度的相同的前缀与后缀。
- 前缀的定义:不包含最后一个字符的,所有以第一个字符为开头的,连续子串。
- 后缀的定义:不包含第一个字符的,所有以最后一个字符为结尾的,连续子串。
- 绘图如下:
- KMP算法:
代码如下:
class Solution {
public:
void getNext(int* next,const string& targetString) {
// 初始化回退的下标值
int retIndex = 0;
// 初始化next数组的第零个元素
next[0] = 0;
// 开始从第一个元素遍历,建立next数组
for(int i = 1; i < targetString.size(); i++) {
// 在前后缀不同的时候,要做下标回退的动作
while(retIndex > 0 && targetString[i] != targetString[retIndex]) {
// 回退的时候,是以前一个位置的下标为准
// 前缀表是不带有最后一个字符的,所以当前位置的前缀表理应是前一个位置保存的下标值
retIndex = next[retIndex - 1];
}
// 假如前缀表跟后缀表的子串相等,可以做累加
if(targetString[i] == targetString[retIndex]) {
retIndex++;
}
// 保存当前的回退下标
next[i] = retIndex;
}
}
int strStr(string haystack, string needle) {
if(needle.size() == 0) {
return 0;
}
int next[needle.size()];
// 建立模式字符串的next数组
getNext(next ,needle);
// 跟目标字符串做比较
int retIndex = 0;
// 从第一个元素开始比较
for(int i = 0; i < haystack.size(); i++) {
// 假如当前位置的元素不匹配,需要做下标回退动作
while(retIndex > 0 && haystack[i] != needle[retIndex]) {
// 回退的时候,以前一个位置的下标为准
retIndex = next[retIndex - 1];
}
// 假如当前位置的元素匹配,移动模式字符串的下标
if(haystack[i] == needle[retIndex]) {
retIndex++;
}
// 假如模式字符串的下标已经移动到最后一位,说明能够在目标字符串中找到匹配的模式字符串,返回第一个匹配位置的下标
if(retIndex == needle.size()) {
return (i - needle.size() + 1);
}
}
return -1;
}
};
总结:
- 投降!!!一刷的时候,看完讲解视频,觉得这道题会做了,现在二刷,还是一脸懵,而且研究不明白了。画个图才知道,自己的理解浅薄得不行。建议直接看carl哥视频。
- 代码随想录的视频讲解:
- 理论讲解:https://www.bilibili.com/video/BV1PD4y1o7nd/
- next数组代码讲解:https://www.bilibili.com/video/BV1M5411j7Xx/
459.重复的子字符串
题目描述:
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例一:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
示例二:
输入: s = "aba"
输出: false
提示:
1 <= s.length <= 104
s 由小写英文字母组成
解题思路:
- **关键词提取:**子串、重复构成
- KMP解法:
- KMP擅长的就是字符串的匹配,可以找到重复的部分,缩短不匹配时需要的重新检索的时间
- 先建立next数组,从next数组中获取结果。next数组中存放的是最长公共前后缀的长度,也就是说,有重复部分的信息
- 假如这个目标字符串是由多个子串构成,那么,在最后一个元素的位置上,next数组一定会保留着不为0的值,可以做下标回退
- 但是,还要再做一层判断,最后一个元素的值,是最长公共前后缀的长度,而且也是可以回退的下标位置,因此,可以计算出子串的长度
- 将字符串总长度跟子串长度做整除,若能整除,就证明可以由这个子串重复构成,否则,不能
代码如下:
class Solution {
public:
// 建立next数组
void getNext(int* next,const string s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while(j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if(s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if(s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
// 若可以由子串重复构成,那next数组的最后一个元素,一定不是0
if(next[len - 1] != 0) {
// 计算出子串的长度,看是否是字符串长度的整数倍
// next数组最后一个元素,代表的是回退的下标值,字符串长度减去回退的下标位置,就是子串的长度
if(len % (len - next[len - 1]) == 0) {
return true;
}
}
return false;
}
};
总结:
- 二刷,在做的时候,会考虑到,下标不是0,但是缺少了一层判断,就是子串长度与字符串总长度的关系。调试多次之后,才摸索出来,还缺这么一个条件。
- 怎么说呢,尽管是没有很好的理解这道题目,还没有掌握KMP算法,但是这是一个过程,先行记录下我的整体想法,后续再回过头看的时候,可以再做迭代与优化。
- 这道题目卡了我四天,每天都是3-4小时左右的时间,视频和文字版反复看,还有代码也是。最终还是对以下几个点有疑惑:
- 最长公共前后缀,这个概念,怎么跟匹配内容联系在一起的。
- 我画了前后缀的图,但好像还是很奇怪,为什么这个地方存储的长度,就是返回值的下标呢。
- 减少重复匹配的时间,在例子sasad中检索sad,那么检索到sas的时候,发现不匹配,这时公共最长前后缀是a,长度是1,就应该从回退到s[1] = a,而不是s[0] = s,重新开始检测?好像这么一看,又符合算法所讲的思路了。。。
- 对计算的过程还是有点不理解,就是为什么比较的是前缀和后缀。
- 思考:
- 实践出真知,多做多思考,总会有收获的。二刷没彻底搞懂,但是我也记住了这个模板,记住了这个解题思路,虽然离融会贯通有很大的差距,但是至少在路上了,总会搞明白的。
- 工作偶尔是闭卷考试,但经常是开卷考试,是可以集思广益的,作为一个普通人,借助团队的力量完成一件事情也是值得骄傲的。
- 建议反复观看代码随想录的讲解,还是避免我这个中间商赚取的差价,直接获取信息比较靠谱一些。















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









