







 阿里云的AI框架EMO能通过单一图像和音频生成逼真的肖像视频,支持多种语言和风格,实现照片人物的动态表达,提升多媒体内容的互动性和真实感。
阿里云的AI框架EMO能通过单一图像和音频生成逼真的肖像视频,支持多种语言和风格,实现照片人物的动态表达,提升多媒体内容的互动性和真实感。
作者:苍何,前大厂高级 Java 工程师,阿里云专家博主,CSDN 2023 年 实力新星,土木转码,现任部门技术 leader,专注于互联网技术分享,职场经验分享。
🔥热门文章推荐:

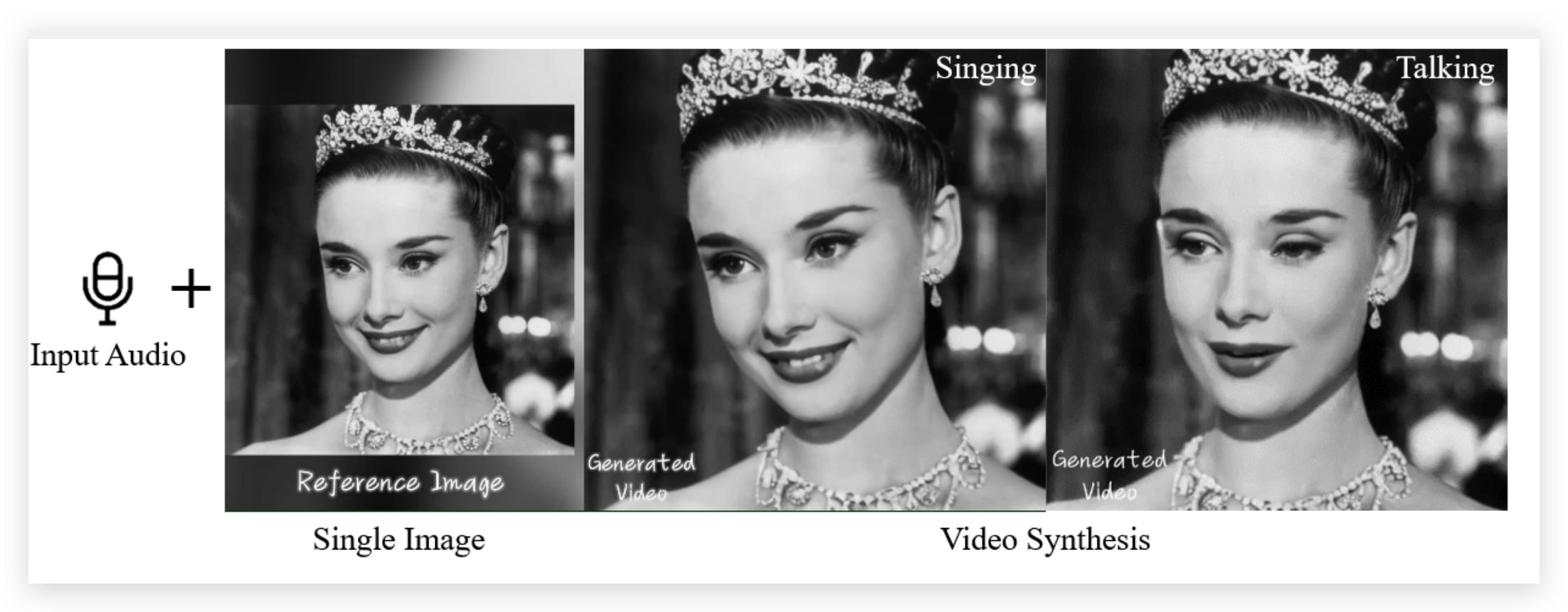
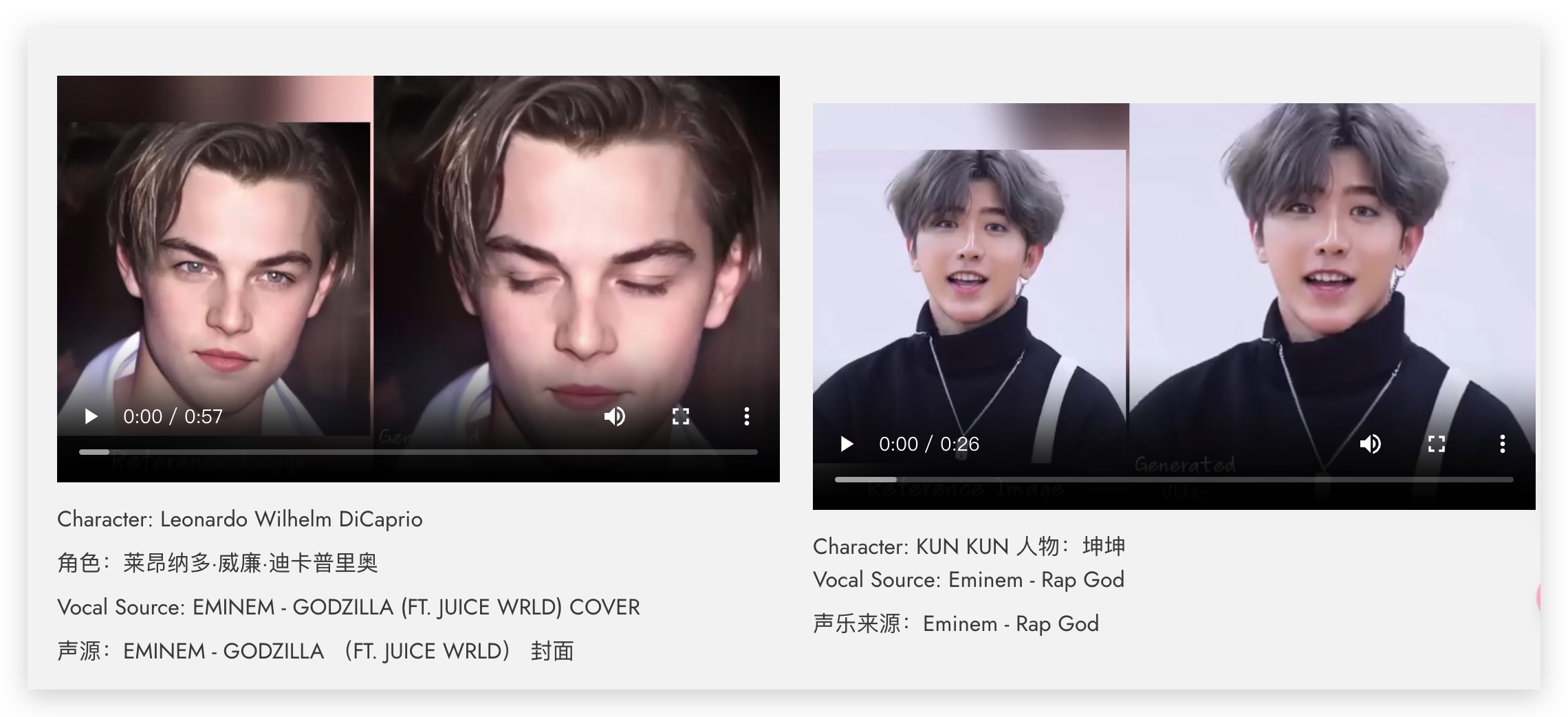
大家好,我是苍何。之前几篇文章介绍过阿里在 AI 方面的一些惊人工具,这不,阿里又推出了 EMO ,它是 AI 肖像视频生成框架,能够通过图像和音频生成富有表现力的人像视频。
它可以直接让头像唱歌,还是很有趣的。
这个工具特别之处在于它能够利用单一的参考图像和音频(如说话或唱歌)来生成丰富的面部表情和头部姿势变化的肖像视频。EMO 的特点是可以根据音频的长度生成任意时长的视频,并且保持角色身份的一致性。此外,EMO 是一个纯视觉解决方案,无需XML(可拓展标记语言)和系统元数据,操作范围不受限制,支持多应用操作,并配备多种视觉感知工具用于操作定位。
EMO 能够通过输入单一的参考图像和声音音频,如说话和唱歌,生成具有表现力的视频,其中的嘴型还可以与声音匹配。这表明 EMO 能够处理任意语音和图像输入,支持任意语速和图像,从而实现高度个性化的视频内容生成。
EMO 甚至擅长制作各种风格的歌唱视频!想象一下,只用你最喜欢的艺术家的一张图片来制作音乐视频,是不是很炸裂!
感兴趣的小伙伴可以去官网看看视频效果哈。
EMO研究论文:https://arxiv.org/pdf/2402.17485.pdf
EMO开源地址:https://humanaigc.github.io/emote-portrait-alive/
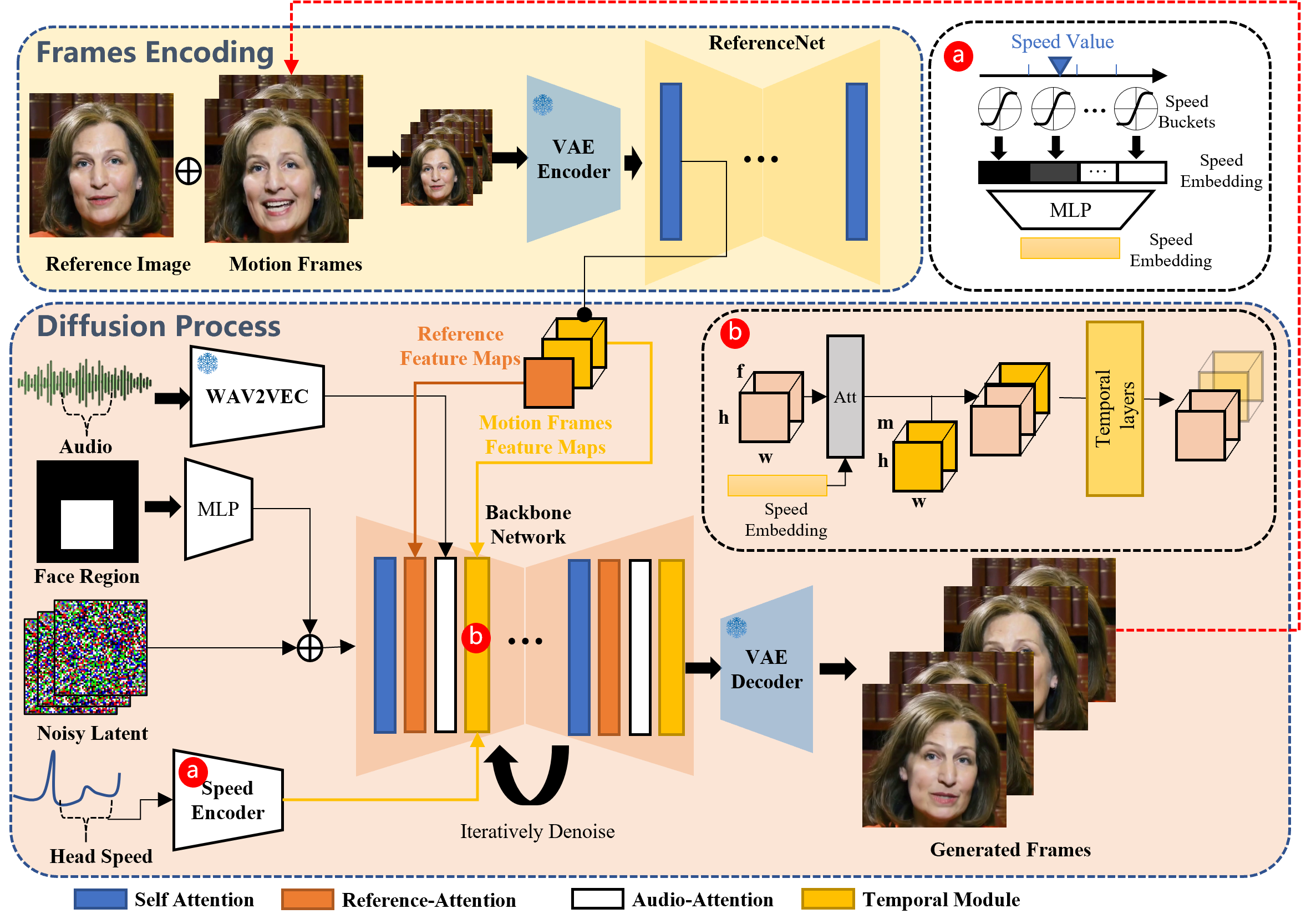
EMO 原理
框架主要由两个阶段组成。在称为帧编码的初始阶段,部署了 ReferenceNet 以从参考图像和运动帧中提取特征。随后,在扩散过程阶段,预训练的音频编码器处理音频嵌入。面部区域蒙版与多帧噪点集成在一起,以控制面部图像的生成。随后,我们采用骨干网络来促进降噪操作。在骨干网络中,应用了两种形式的注意力机制:参考注意力和音频注意力。这些机制分别对于保持角色的身份和调节角色的动作至关重要。此外,时间模块用于操纵时间维度,并调整运动速度。
EMO主要功能
- 把静止的照片变成会说话或唱歌的视频:只要你有一张人的照片和一段声音(比如说话或唱歌的录音),EMO技术就可以让这张照片里的人动起来,就像他们真的在说话或唱歌一样。不管他们怎么变脸或动头,视频里的人物都会保持照片上的样子。
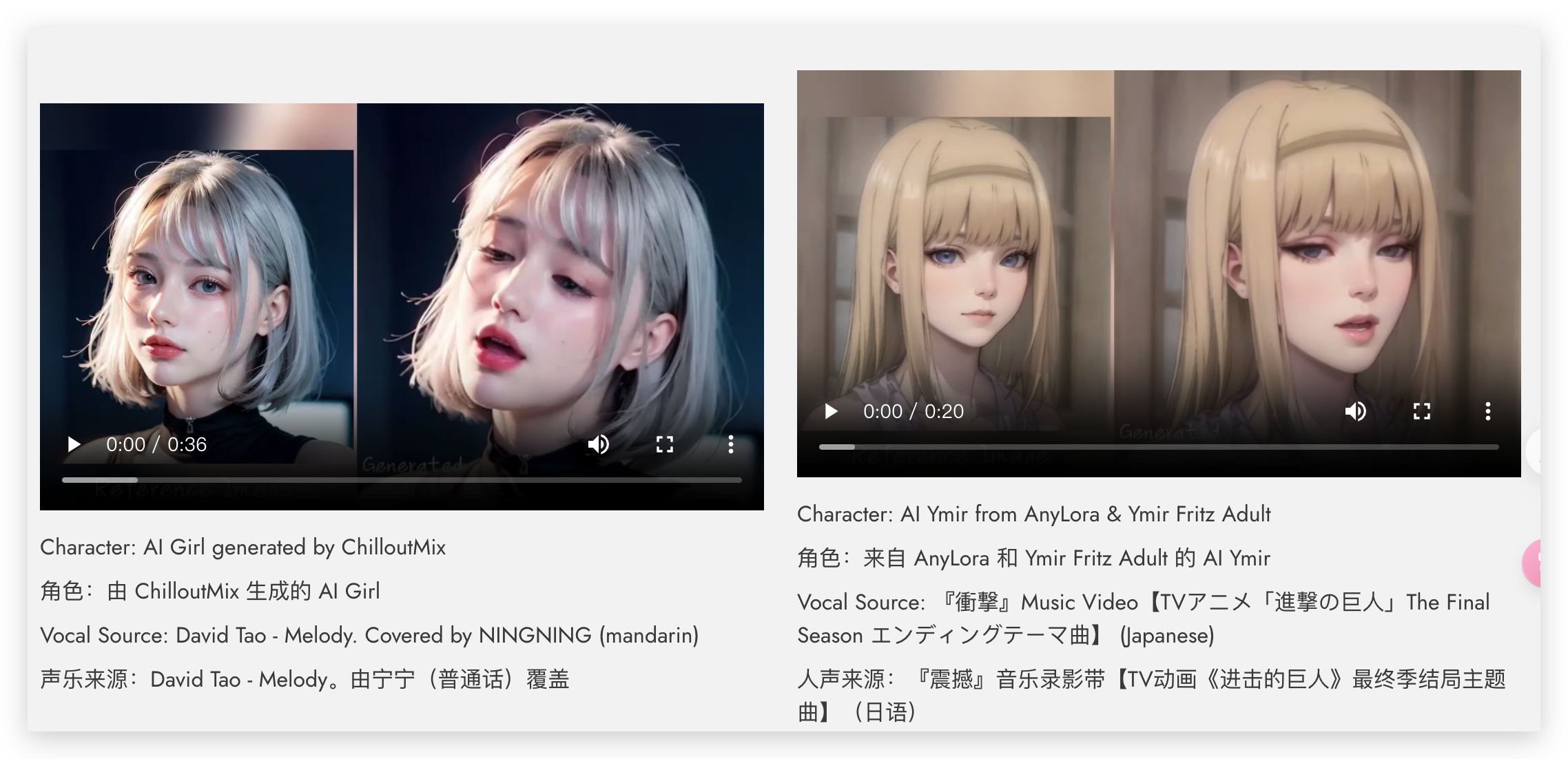
- 视频里的表情和头动作看起来真实自然:EMO特别擅长让视频中的面部动作和表情看起来非常自然和生动。它可以捕捉到细微的表情和头部的动作,让人物的谈话和唱歌看起来就像是真的一样。
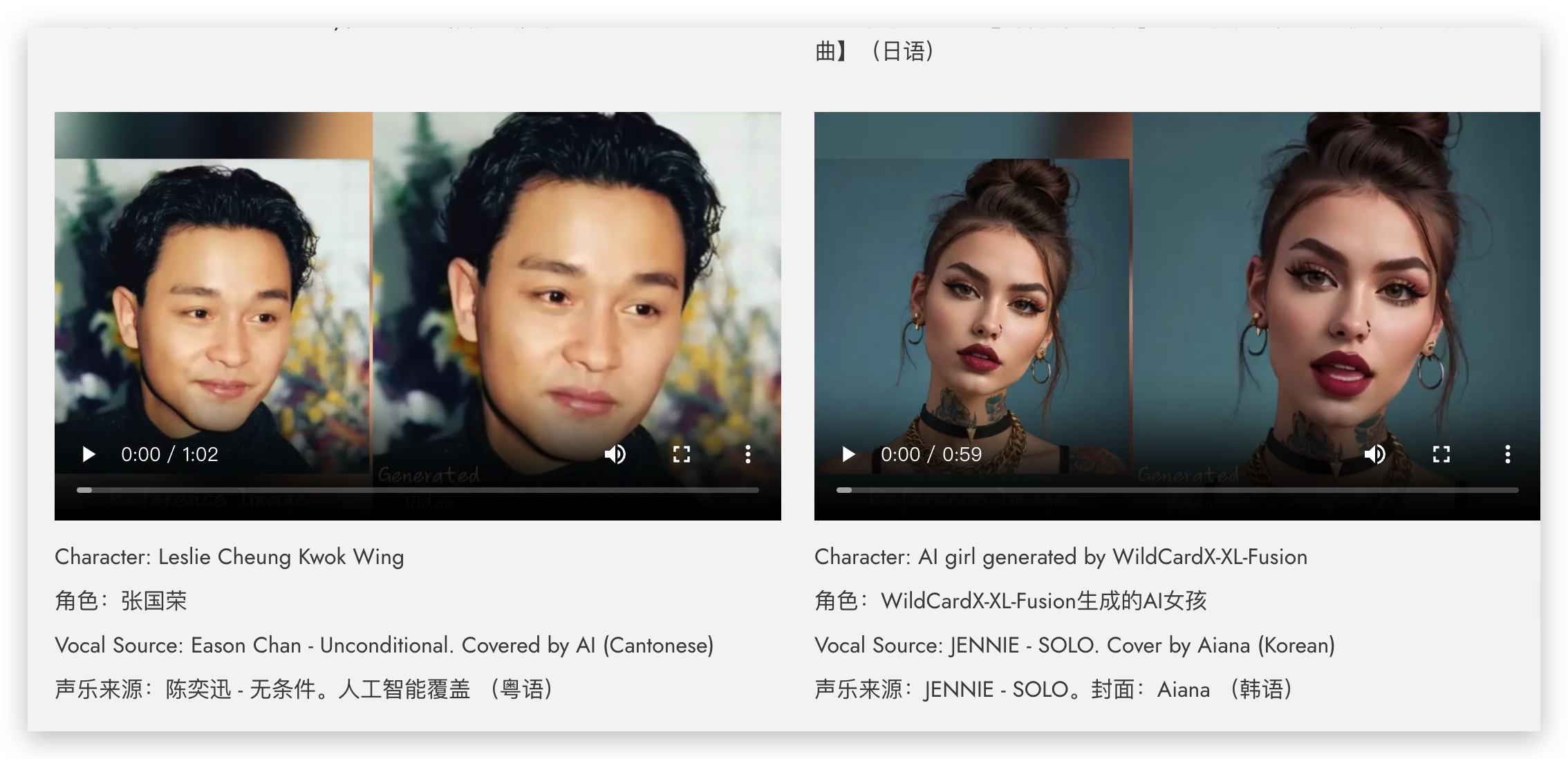
- 支持多种语言和风格:不管你说的是什么语言,或者想要什么样的风格——比如历史人物、绘画、3D模型,或者AI生成的内容——EMO技术都能搞定。
- 能跟上快节奏:如果你的音频节奏很快,比如快歌或快速说话,EMO也能确保视频中的人物动作和音频保持同步。
- 可以模仿不同人的表现:EMO还能让一个人在视频里模仿另一个人的表现,这意味着你可以创造出多样化的角色和场景,让不同的人物在视频中扮演不同的角色。
简单来说,EMO技术让我们能用一张照片和声音创造出既真实又动听的视频,不受语言和风格的限制,还能快速适应不同的节奏和表现方式。
EMO 应用场景
这里是对你提供描述的一个改写,旨在避免词汇的重复并增加原创性:
- 实现同步声音配合:立刻为内容添加配音,增强视听体验。
- 塑造电影与游戏中栩栩如生的人物:为视觉作品中的角色注入生动的表情和丰富的情感,提升故事的沉浸感。
- 打造吸引眼球的教学资源:利用引人注目的互动元素,制作教育内容更加生动和吸引学习者。
- 赋予虚拟助理人性化特质:让技术助手不仅听起来,而且看起来更接近人类,增强用户体验。
- 增添视频会议的魅力和个性:通过创新技术,使远程沟通更加生动和个性化。
- 创作令人印象深刻的营销内容:通过动人心弦和难忘的视频广告,吸引观众注意力,提高品牌影响力。
大家可以去看看官网生成的视频,还是很惊艳的,可惜现在还没法体验。
如果你也对 AI 或编程感兴趣,欢迎关注苍何。

创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











