







文章目录
平台:阿里云轻量级应用服务器
Hadoop:3.2.2
Hive:3.1.2
一、Hive的安装
(一)下载安装文件
- Hive官网链接
http://www.apache.org/dyn/closer.cgi/hive/ - hive-3.1.2的链接
https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz - 下载
sudo wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz - 解压及相应设置
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中 cd /usr/local/ sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive sudo chown -R hadoop:hadoop hive # 修改文件权限
(二)配置环境变量
- 进入环境变量设置文件
sudo nano ~/.bashrc - 添加变量的内容
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin - 使文件生效
source ~/.bashrc
(三)修改配置文件
- 修改配置文件名称
cd /usr/local/hive/conf sudo mv hive-default.xml.template hive-default.xml - 新建一个配置文件
文件内容cd /usr/local/hive/conf sudo nano hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> <!--可选,用于指定 Hive 数据仓库的数据存储在 HDFS 上的目录--> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> <description>hive default warehouse, if nessecory, change it</description> </property> </configuration>
(四)安装并配置MySQL
- 安装MySQL
sudo apt-get update sudo apt-get install mysql-server - 下载MySQL JDBC驱动程序
下载链接:https://downloads.mysql.com/archives/c-j/
解压并进行相关设置cd ~ tar -zxvf mysql-connector-java-8.0.17.tar.gz #解压 #下面将mysql-connector-java-8.0.17.jar拷贝到/usr/local/hive/lib目录下 cp mysql-connector-java-8.0.17/mysql-connector-java-8.0.17.jar /usr/local/hive/lib - 启动MySQL
遇到输入密码的时候,直接回车service mysql start #启动MySQL服务 mysql -u root -p #登录MySQL数据库 - 在MySQL中为Hive新建数据库
新建一个名称为hive的数据库,用来保存Hive的元数据。mysql> create database hive;
- 配置MySQL允许Hive接入
MySQL进行权限配置,允许Hive连接到MySQLmysql> grant all on *.* to hive@localhost identified by 'hive'; mysql> flush privileges;
- 初始化元数据库
出现到如下问题schematool -dbType mysql -initSchema
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
解决方法:
打开/usr/local/hive/conf/hive-site.xml,在hive配置文件hive-site.xml中加上serverTimezone=GMT

- 启动Hive
启动Hive之前,需要先启动Hadoop集群
出现下面错误cd /usr/local/hadoop ./sbin/start-dfs.sh cd /usr/local/hive ./bin/hive
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgumen
解决方法
hadoop和hive的jar包冲突cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib rm /usr/local/hive/lib/guava-19.0.jar
二、Hive的数据类型
- Hive的基本数据类型
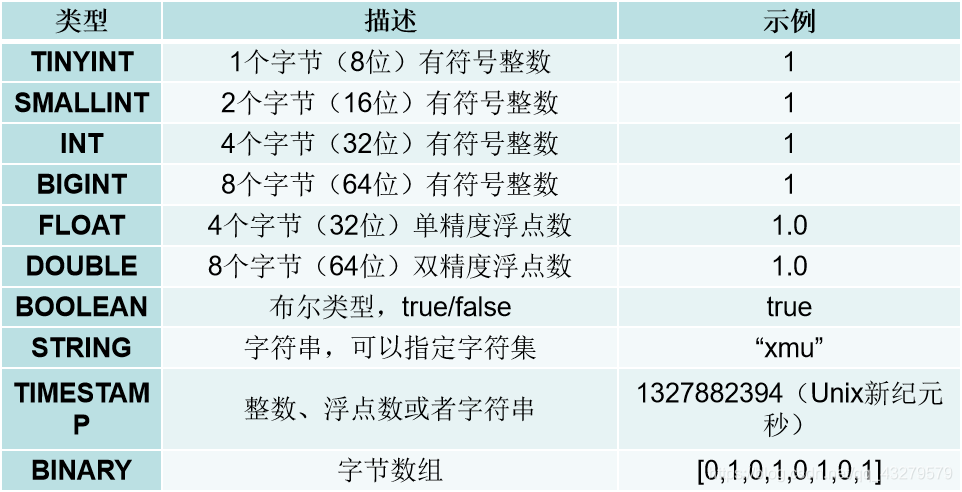
- Hive的集合数据类型
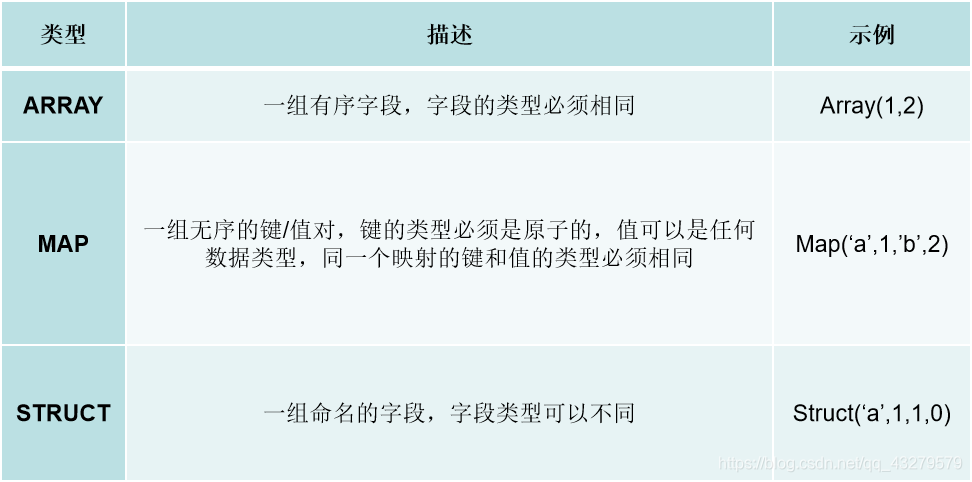
三、Hive基本操作
- 创建数据库、表、视图
保存的位置为/user/hive/warehouse/,根据上面是否添加可选的配置
①创建数据库create database hive; #避免因为数据库已存在,而出现抛异常,加上if not exists关键字,则不会抛出异常 create database if not exists hive;
②创建表#通常创建表 hive> use hive; hive>create table if not exists usr(id bigint,name string,age int); #创建可以读取以“,”分隔的数据 create table student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ",";

- 删除数据库、表、视图
①删除数据库
②删除表drop database hive; #删除数据库hive,因为有if exists关键字,即使不存在也不会抛出异常 drop database if not exists hive; #加上cascade关键字,可以删除当前数据库和该数据库中的表 drop database if not exists hive cascade;
③删除视图#删除表usr,如果是内部表,元数据和实际数据都会被删除;如果是外部表,只删除元数据,不删除实际数据 drop table if exists usr;drop view if exists little_usr; - 往表中加载数据
load data local inpath "/home/hadoop/student.txt" into table student;
- 查询数据
select * from student;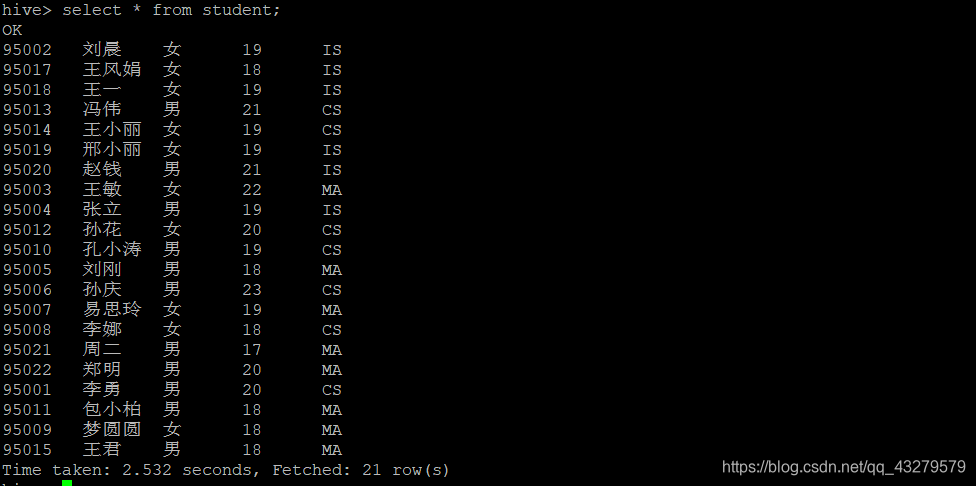
- 查看表结构
desc student;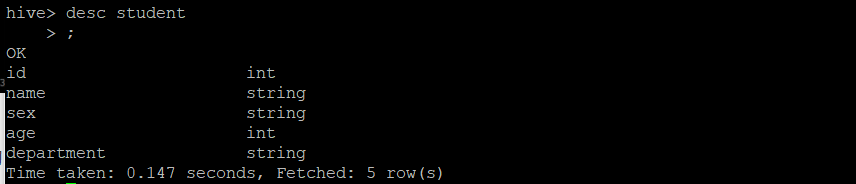
四、Hive应用实例——WordCount
实例描述:需要创建一个需要分析的输入数据文件,然后编写HiveQL语句实现WordCount算法
-
创建input目录,其中input为输入目录
cd /usr/local/hadoop mkdir input -
创建两个测试文件file1.txt和file2.txt
cd /usr/local/hadoop/input echo "hello world" > file1.txt echo "hello hadoop" > file2.txt -
编写HiveQL语句实现WordCount算法
./hive/bin/hive hive> create table docs(line string); hive> load data inpath "hdfs://localhost:9000/input" overwrite into table docs; hive>create table word_count as select word, count(1) as count from (select explode(split(line,' '))as word from docs) w group by word order by word;
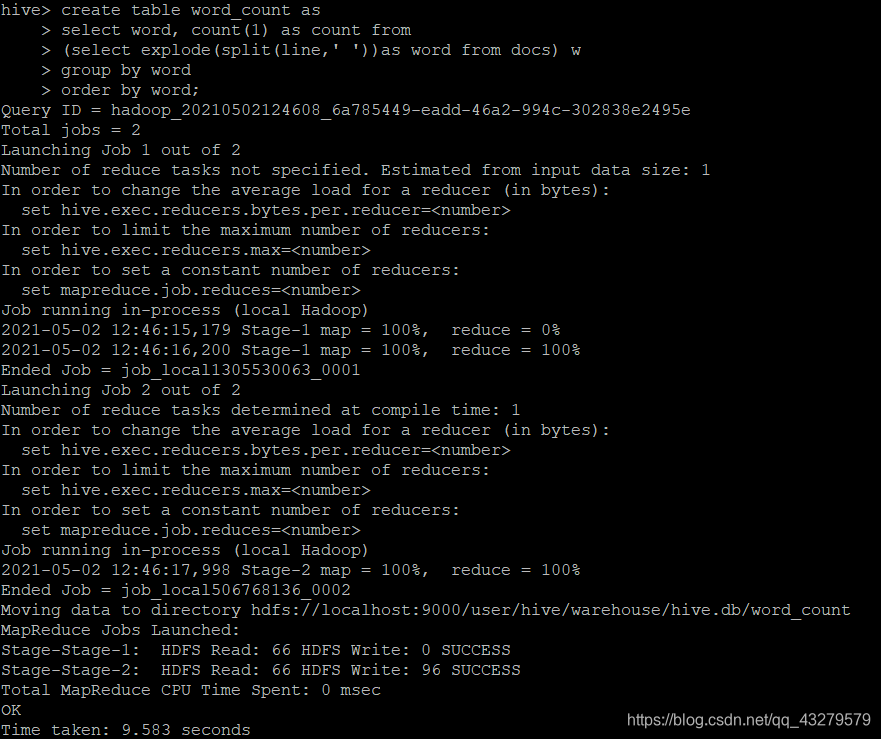
select语句查看运行结果
select * from word_count;
小结
Hive是一个构建于Hadoop顶层的数据仓库工具,主要用于对存储在 Hadoop 文件中的数据集进行数据整理、特殊查询和分析处理。Hive在某种程度上可以看作是用户编程接口,本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据。

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









