







字符串
字符串大家都知道,也非常的熟悉,在这里就不一一介绍了。
字符串的存储我们一般就是使用string来存储,相对于链式存储的闲的没事干就是用数组来线性存储,一个地址存放一个字符,一般的string都是这么干的,但是我们一般都不会模拟这个东东……
而且考起来一般也不难,最难的地方在于——字符串的模式匹配。
字符串模式匹配问题
一般而言有两种方法,一种是暴力匹配法,一种是KMP匹配法。
暴力匹配
暴力匹配法,按照字面意思,就是一个个比较。
一般来说,匹配模式是这样的:
- 给我了两个字符串s与t。
- 我们一个字符一个字符的比较,如果匹配成功,那么比较的位置都下移一位(即i++,j++),如果比较失败,那就很抱歉了,被匹配的串s从这一次匹配的开头的下一个开始匹配(即i+1),而进行匹配的串t则是从最开始进行匹配。
- 直到匹配到t串的最后一个字符结束,如果成功输出s串的位置,如果失败,进行第二部。
- 如果直到s串结束,都没有匹配玩t串的最后一个元素,那么我们就会下这样一个定义:匹配失败,s中不存在子串t。
暴力匹配的优点十分明显,大家都可以看得出来,思想非常简单,实现虽然不太容易,但是对于大部分同学来说努力努力还是可以打出来的,但是缺点也很明显——十分耗时。
如果我们不进行oj上的提交也就算了,但是众所周知,我们是必须提交的,而且时限多为1秒。
在这短短的一秒内,我们很容易想到,一个时间复杂度为O(n*m)的算法,是没有未来的,一旦主串和副串的长度都高达10^5,那么超时是必然的。
聪明的科学家们于是就开始思考如何才能让这个算法更快。
很简单,大家都会想到,主串能不能别一下子移动这么多,甚至不移动呢?如果仅仅移动副串,那么时间应该会减少很多吧?
于是KMP模式匹配的方法,就这样诞生了。
KMP算法
KMP算法就是暴力算法的引申。
我们都看得出来,这个暴力的解法最浪费时间的地方在于将s刷新后重新从i+1开始一个个枚举。
而这种KMP算法,不再让s重新进行枚举了,而是让p进行一些类似于右移的行为,即j=next[j],找到与j位置前面的后缀相同的前缀,再进行一个个的枚举,直到s枚举结束,用f[i]记录s中i这个位置最大可以对应到p的j位置,f[i]=plen的时候,就是s第一次包含了p的地方:i。
要说博客,还是这篇博客好,内容非常细致!
代码实现:
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
}
int KmpSearch(char* s, char* p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}
多维数组
数组我们使用的都十分熟练了,大大小小有关数组的题目也做了很多。
这里重点介绍的是对于二维数组甚至n维数组是怎么存储到一维数组里面的。同时也会介绍如何将矩阵存在数组里面。
为什么要将二维数组存到一维数组当中自找麻烦呢?
因为数组虽然有二维、三维或者n维,但是内存却是只有一维的,对于一个二维数组来说,他是经过了编译器的预处理,将它以另一种方式存储到一维的内存当中。
由于我们以后会学习到编译器,会需要用到维度的转换,所以此时的学习是非常有必要哒。
当然,这里还会介绍广义表。
广义表
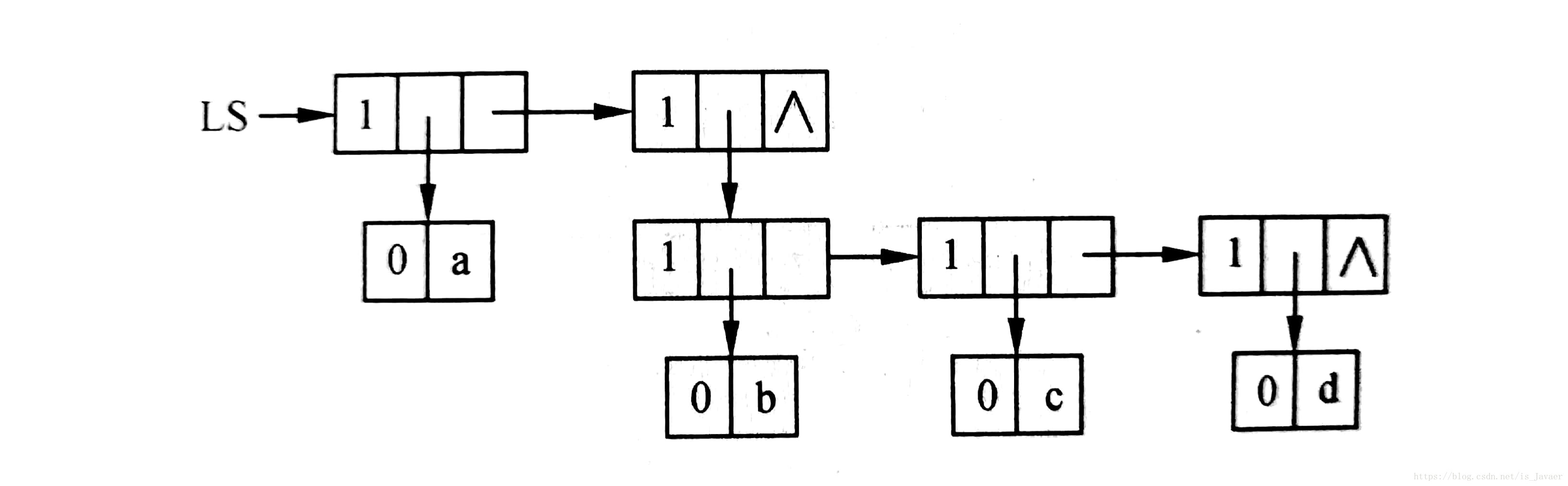
广义表是线性表的推广,是由0个或多个单元素或子表组成的有限序列。
广义表的长度是指广义表中元素的个数。
广义表的深度是指广义表展开后所含的括号的最大层数。
非空广义表的第一个元素称为表头,他可以是一个单元素,也可以是一个子表;除表头元素之外,由其余元素所构成的表称为表尾,非空广义表的表尾必定是一个表。
在构造广义表的时候,最重要的就是此处的表尾,因为他一直是一个表,所以专门设立最后一块内存记录表尾指针。如下图所示。
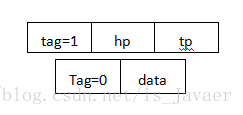
第一个值为标记,标记此时的表头是数据还是子表,而表尾统一为子表,无子表则设为空。
多维数组
多维数组的存储重点在于,找出某个节点i之前存储的数目与i和j的关系,然后根据这个关系写表达式即可。
额,比较简单,写的话当场找找关系就好,不能死记硬背,反正也背不过,变化还多~
特殊矩阵
重点也是看到这个矩阵的aij前面有多少个元素,跟二维数组差不多。
我觉得很容易理解。
但是要是让我把存起来的数据再变回到矩阵,可能就不是那么简单了,因为情况有点复杂,当然了,理解了之后怎么样都是简单的,还是要多多理解。
三元顺序表也很简单,通俗易懂,刚刚突然又顿悟了一下,算是全都明白了……
学习反思
这里没什么难的,也不是很简单。
难就难在太麻烦,懒得做。
简单就简单在不怎么考……咳咳咳,所以这里有点怠惰,应该反省一下,自己为什么会怠惰,果然是没有考试的鞭策不想学习???
啊,我果然还不够优秀,真正优秀的m某,一定是了解的很深刻的,呜……
绝对不能给自己低标准!加油!















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









