







目录
1. 协同过滤
1.1 ItemCF
1.1.1实现原理
- 量化用户对物品的兴趣
like(user, item)。例如:点击、点赞、收藏、转发各算一分 - 物品相似度计算:
Jaccard相似度,没有考虑不同行为的偏好程度
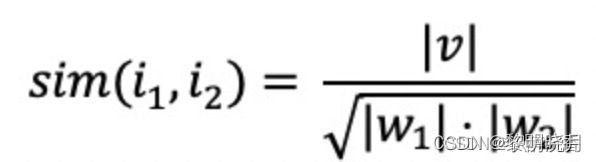
余炫相似度,考虑用户喜欢的程度,其中V为喜欢item1和item2的用户交集.
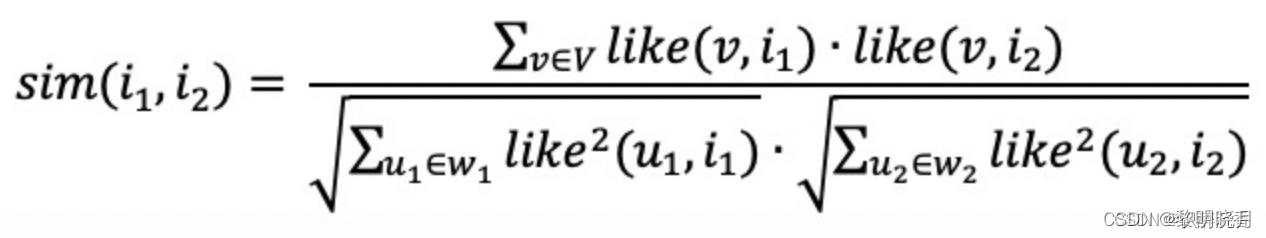
- 预估用户对候选商品的兴趣:
j为用户历史交互商品集合
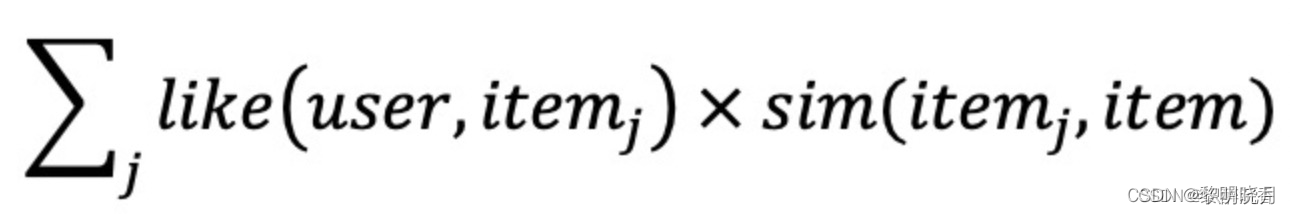
1.1.2 完整流程
用索引,离线计算量大,线上计算量小
1. 事先做离线计算,建立两个索引
- 建立
user——>item的索引:记录每个用户最近点击、交互过的物品ID- 目的:给定任意用户
id,可以找到他近期感兴趣的物品列表 - 存储形式:
user_id: [(item_id, score兴趣分)
- 目的:给定任意用户
- 建立
item——>item的索引: 给定任意item_id,可以快速找到它最相似的k个items- 计算物品之间两两相似度
- 对于每个物品,索引它最相似的
k个物品 - 存储形式:
item_id:topK个最相似的[items_id, 相似度]
2. 线上做召回,用于实时推荐
query用户id,通过user--> item索引,找到用户近期感兴趣的物品列表last-n。- 对于
last-n列表中每个item,通过item--> item的索引,找到top-k相似物品 - 对于取回的相似物品(最多有
nk个),用公式预估用户对物品的相似分数 - 返回分数最高的100个物品,作为
itemCF通道的返回结果。重复的把分数加起来,去重
1.2 UserCF
1.2.1 原理
- 用户相似度计算:降低热门物品权重
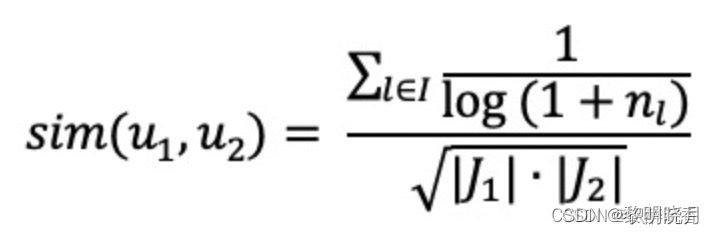
注:nl: 用户喜欢物品l的用户数量,反应物品的热门程度,I为用户u1和u2喜欢物品集合的交集 - 预估用户
user对候选物品item的兴趣:
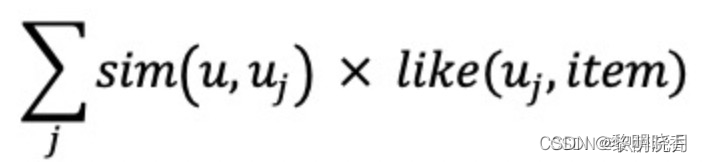
1.2.2 完整流程
1. 事先做离线计算
- 建立
user--> item的索引:- 记录每个用户最近点击、交互过的物品
ID - 给定任意用户
ID,可以找到他近期感兴趣的物品list user_id:[(item_id, 兴趣分数),......]
- 记录每个用户最近点击、交互过的物品
- 建立
user-->user的索引:- 对于每个用户,索引他最相似的
k个用户 - 给定任意用户
id,可以快速找到他最相似的k个用户 user_id: 最相似的k个【(user_id, 相似度),…】
- 对于每个用户,索引他最相似的
2. 线上做召回
- 给定用户
ID,通过user_id--->user_id索引,找到top-k相似用户 - 对于每个
top-k相似用户,通过user_id-->item索引,找到用户最近感兴趣的物品列表last-n - 对于召回的
nk个相似物品,用公式预估用户对每个物品的兴趣分数
2. 图召回
2.1 Swing算法
背景:假如重合的用户是一个小圈子,当两件物品的受众完全不一样,圈子里很多人交互,这时就需要降低小圈子的权重,希望两个物品重合的用户广泛且多样。
模型原理:给用户设置权重,解决小圈子问题
物品相似度计算:
- 定义两个用户的重合度:J为用户喜欢商品的集合
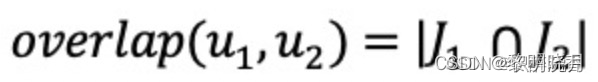
- 物品相似度

overlap越大,用户u1和u2的重合度越高,则他们可能来自一个小圈子,要降低他们的权重
2.2 DeepWalk
- node2vec
- EGES
- GraphSAGE
3. 向量召回
本质上讲是将召回建模成在向量空间内的近邻搜索问题,将用户和物品均由向量表示,离线构建索引,在serving时模糊近邻查找。
3.1 算法模型
- DSSM 双塔召回:基本结构就是
user和group侧分别用NN网络来拟合,最上层的神经元可认为是user和group的向量表征。CTR召回可以直接用点积+sigmod得到loss,时长模型可以用cos距离+mse计算loss - SENet双塔模型
- FM召回:主体思路依旧是构建向量,然后离线建
group_emd,线上计算user_emd再近邻查找。
3.2 具体实现
- 离散特征处理
- 建立字典:把类别映射成序号
- 向量化:将序号映射成向量
One-hot编码:把序号映射成高维稀疏向量Embedding:把序号映射成低维稠密向量
- 向量模型存储
- 用户矩阵向量:列向量储存到
key-value表 - 物品矩阵向量:
- 近似最近邻查找
- 集成好的支持最近邻查找的系统:
Milvus、Faiss、HnswLib - 衡量最近邻的标准:
- 欧式距离最小:
L2距离 - 向量内积最大(内积相似度)
- 向量夹角余弦最大(
cosine相似度):工业界最常用。
有些系统不支持,但只需要将向量做归一化,使二范数全等于1,内积就等于余弦相似度
- 欧式距离最小:
- 向量数据预处理,划分不同的区间。
- 方法:根据衡量最近临的标准划分,比如,余弦相似度,将空间划分成扇形区域
- 每个区域用一个向量表示,然后建立索引,
key:每个区域的向量,value:区域中所有点的列表
3.3 双塔模型
3.3.1模型结构
- 用户塔
拼接向量经过DNN输出用户表征向量,用户id:embedding Layer映射成embedding
用户离散特征:one-hot—>embedding Layer
用户连续特征:归一化、长尾特征取log、分桶等处理 - 物品塔: 同用户塔
3.3.2 模型训练方式
-
Pointwise: 把召回看作二元分类任务- 正样本:鼓励
cos(a,b)接近于+1 - 负样本:鼓励
cos(a,b)接近于-1 - 经验:控制正负样本数量为
1:2或者1:3
- 正样本:鼓励
-
Pairwise:- 训练样本:输入是一个三元组,(正样本、用户、负样本)
- 计算
cos(a,b+)以及cos(a,b-)基本想法:鼓励cos(a,b+)大于cos(a,b-) - 损失函数:如果
cos(a,b+)大于cos(a,b-) +m,则没有损失
否则,损失等于cos(a,b-)+m - cos(a,b+)
Triplet hinge loss:
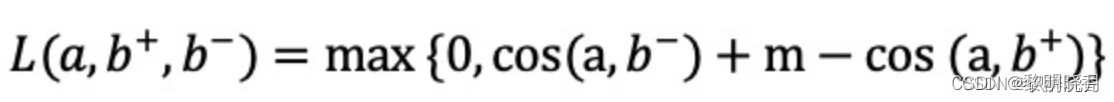
Triplet logistic loss:
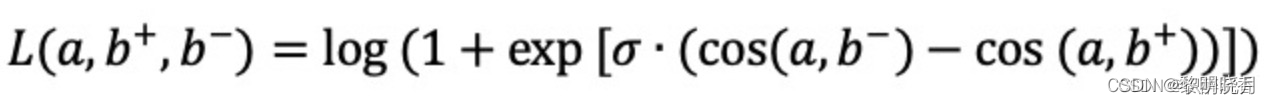
-
Listwie:
- 训练样本:一个用户,一个正样本,多个负样本
- 分别计算:

- 将上面计算的
cos值通过softmax激活函数,得到n个预测值s,和为1
通过CrossEntropyLoss(y,s):y取1或0,所以也是最大化正样本的余弦相似度
3.3.3 正负样本
选择负样本的原理:
召回目标:快速找到用户可能感兴趣的物品
排序目标:区分比较感兴趣和非常感兴趣的物品
正样本
- 曝光且有点击的用户–物品二元组
- 问题:少部分物品占据大部分点击,导致正样本大多是热门物品
- 解决方案:过采样冷门物品或降采样热门物品
降采样:以一定的概率(和出现次数正相关)抛弃一些样本,
负样本:
召回|粗排模型负样本选择策略
-
简单负样本:
- 未被召回的物品,大概率是用户不感兴趣的
- 从全体物品中做抽样,作为负样本
- 均匀抽样:对冷门物品不公平。28法则, 正样本大多是热门物品,如果均匀抽样产生负样本,负样本大多是冷门物品
- 非均匀抽样:目的是打压热门物品,负样本抽样概率与热门程度(点击次数)正相关
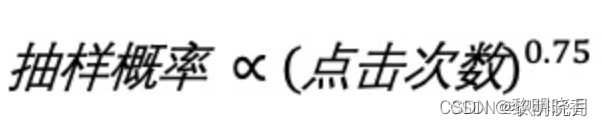
Batch内负样本- 一个
batch内有n个正样本,一个用户和n-1个物品组成负样本,这个batch内一共有(n-1)个负样本 - 问题:这里有个问题,物品成为负样本的概率正比于点击次数,但应该正比于
0.75次方,导致热门物品成为负样本的概率过大。 - 修正:物品i被抽样到的概率为
pi,则在做训练的时候,调整为cos(a,bi) - logpi。但线上做召回的时候仍旧使用cos(a,b)
- 一个
-
困难负样本:
- 被粗排淘汰的物品(比较困难):能进入粗排的多多少少符合用户兴趣,但是不是那么强烈
- 精排分数靠后的物品(非常困难):符合用户兴趣,但未必是用户最感兴趣的,所以在精排中排名靠后的可以被视为负样本
对于双塔模型做召回,二元分类任务,让模型区分正负样本:
- 把全体物品作为负样本,分类准确率高,因为负样本明显和用户兴趣不符
- 被粗排淘汰的作为负样本,但他们多少和用户兴趣有些相关,分类准确率较低一些
- 精排分数靠后的物品更容易分错
工业界训练数据:混合几种负样本,50%的负样本是全体物品,50%的负样本是没通过排序的物品。对于曝光但是没有点击,训练召回模型不能用这类负样本,训练排序模型会用这类负样本。
3.3.4 线上召回和更新
- 线上召回
-
离线存储
- 完成训练之后,用物品塔计算每个物品的特征向量b
- 把
<特征向量,item_id>保存到ANN框架向量数据库Milvus、Faiss - 向量数据库建索引,以便加速最近邻查找
-
用户塔:用户的兴趣动态变化,而物品特征相对稳定(可以离线储存用户向量,但不利于推荐效果)
- 给定用户id和特征,在线上计算向量a
- 将向量
a作为query调用向量数据库做检索查找 - 返回余弦相似度最大的
k个物品,作为召回结果
- 模型更新
-
增量更新
- 做
online learning更新模型参数,用户的兴趣会随时发生变化 - 实时收集线上数据,做流式处理,生成
TFRecord文件 - 对模型做
online learning, 增量更新ID embedding参数。(不更新神经网络其他部分的参数) - 增量更新问题:小时数据有偏,分钟级数据偏差更大
- 做
-
全量更新
- 在昨天的模型参数基础上做训练,并不是更新增量模型
- 用昨天的数据,
random shuffle,训练1 epoch,即每天的数据只用一遍 - 发布新的用户塔神经网络和物品向量,供线上召回使用
随机打乱优于按顺序排列数据,全量训练优于增量训练
4. 行为序列建模召回
- RNN序列召回
- MIND多兴趣召回:其基本思想是用户兴趣多样,仅用一个向量表征用户兴趣是有偏的,如果能构建多个user_emd某种程度上就能召回出更全的候选,该论文采用胶囊网络来建模用户多种兴趣。
- SDM长期兴趣建模
5. 其他召回通道
- 地理位置召回
用户可能对附近发生的事感兴趣
GeoHash: 对经纬度的编码,地图上一个长方形区域
索引:GeoHash-->优质物品列表(按照时间倒排)- 同城召回:索引:
城市---> 优质内容列表
- 作者召回
- 用户对关注的作者发布的内容感兴趣
- 有交互的作者召回
- 相似作者召回
- 缓存召回
背景:精排输出几百个物品,送入重排,重排做多样性抽样,选出几十篇,精排结果一大半没有曝光,被浪费。
想法:复用前n次推荐精排的结果,精排前50,但是没有曝光的,缓存起来,作为一条召回通道,缓存大小固定,需要退场机制
- 一旦商品成功曝光,就从缓存退场
- 如果超出缓存大小,就移除最先进入缓存的物品
- 每个物品最多被召回10次,达到10次就退场
6. 冷启动
6.1评价指标
- 主播侧指标:发布渗透率、人均发布量
- 用户侧指标:新专辑指标:新专辑的点击率、交互率
-
新笔记的点击率、交互率:
- 问题: 曝光的基尼系数很大,少数头部新笔记占据了大部分的曝光
-
分别考察高曝光、低曝光新笔记
- 高曝光:比如> 1000次曝光
- 低曝光:比如<1000次曝光
- 大盘指标:消费时长、日活、月活
- 内容侧指标:高热专辑占比
6.2 简单的召回通道
-
双塔模型做
id embedding是,让所有新专辑共享一个id,而不是使用自己真正的id。default embedding
改进: 使用相似物品的embeddding,取topk个高曝光的相似物品 -
类目召回、关键词召回:按照刚刚发布的时间顺序召回
6.3 聚类召回
基本思想:如果用户喜欢一件物品,那么那会喜欢内容相似的物品
- 事先需要训练一个神经网络,基于专辑的类目和图文内容,把专辑映射到向量。
- 对专辑向量做聚类,划分为
1000cluster,记录每个cluster的中心方向。(k-means聚类,用余弦相似度) - 给定用户id,找到他的
last-n交互的专辑列表,把这写专辑作为种子专辑,把每篇种子专辑映射到向量,寻找最相似的cluster。(知道了用户对哪些cluster感兴趣) - 从每个
cluster的专辑列表中,取回最新的m张专辑 cnn提取图片,bert提取文本特征
6.4 Look-Alike召回
6.5 流量调控
流量怎么在新、老物品中分配,目的:
- 促进发布,增大内容池。新专辑获得的曝光越多,作者的创作积极性越高。反映在发布渗透率、人均发布量。 挖掘优质笔记。
- 挖掘优质笔记。做探索,让每篇新专辑都能获得足够曝光,挖掘的能力反映在高热专辑占比。
工业界的做法:PID技术
- 假设推荐系统只分发年龄小于
30天的专辑 - 假设采用自然分发,新专辑(年龄小于
24h)的曝光占比为1/30 - 扶持新专辑,让新专辑的曝光占比远大于
1/30
流量调控技术的发展:
- 在推荐结果中强插新物品
- 对新物品的排序分数做提权
boost:在排序阶段加上或乘上一个系数 - 通过提权,对新物品做保量
- 差异化保量
6.6 物品冷启动AB测试
指标:
- 用户侧:对新专辑的点击率、交互率
- 大盘侧:消费指标,消费时长、日活、月活
5%的用户侧实验
限定:保量100次曝光
假设:新笔记曝光越多,用户使用APP时长越低
新策略:把新专辑排序时的权重增大两倍。
结果(只看用户消费指标):AB测试的diff是负数,实验组不如对照组,如果推全,diff会缩小


















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









