






VGG网络:
2014年牛津大学著名研究组提出。
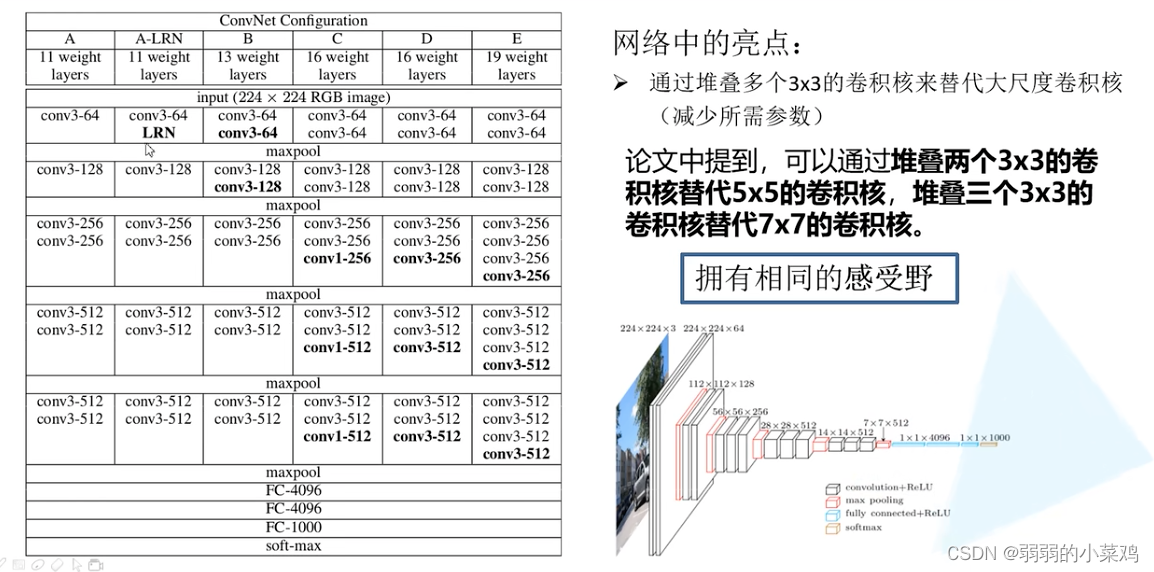
网络中的亮点:
小尺度的卷积核的堆叠可以替代大尺度的卷积核
小尺度的卷积核的堆叠和大尺度的卷积核具备相同的感受野。
那么什么是感受野?
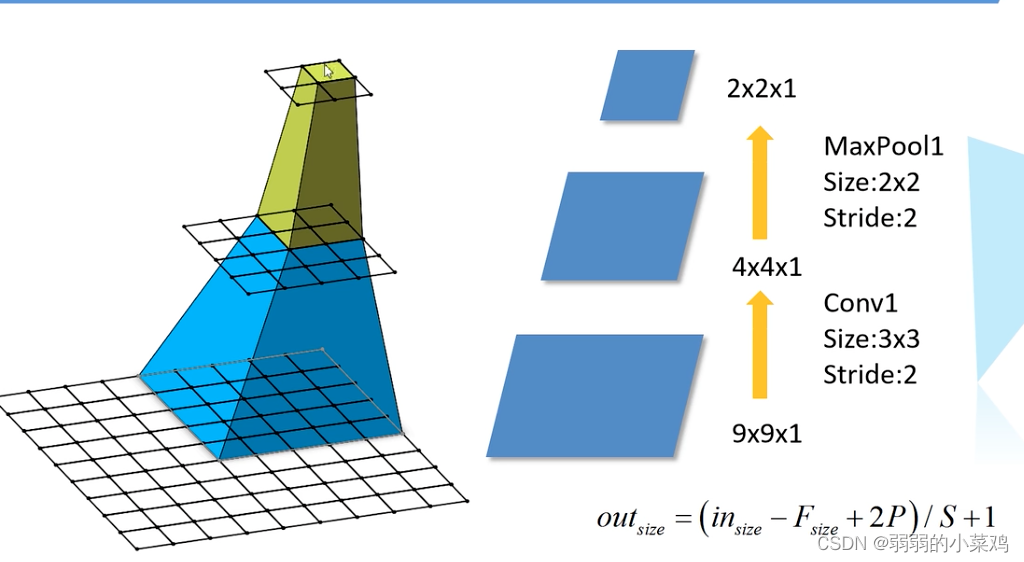
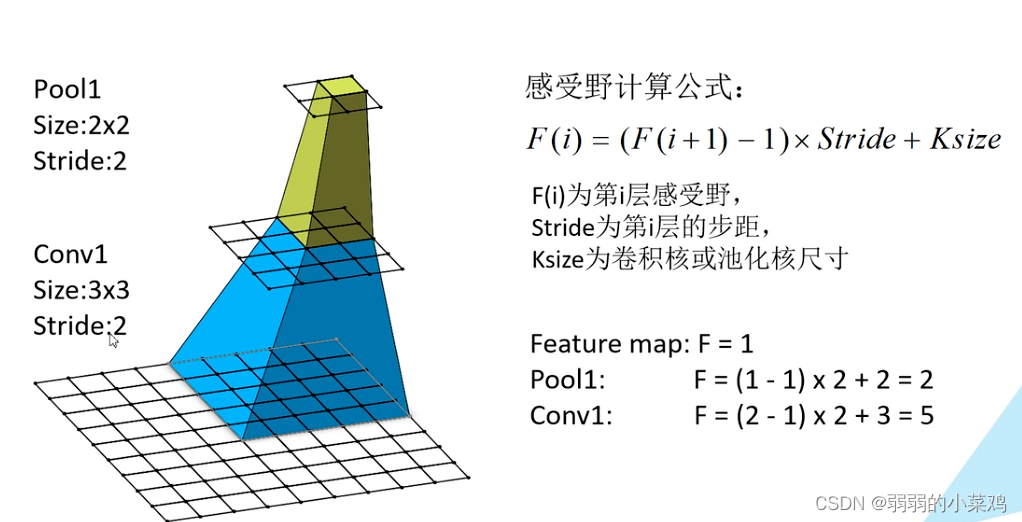
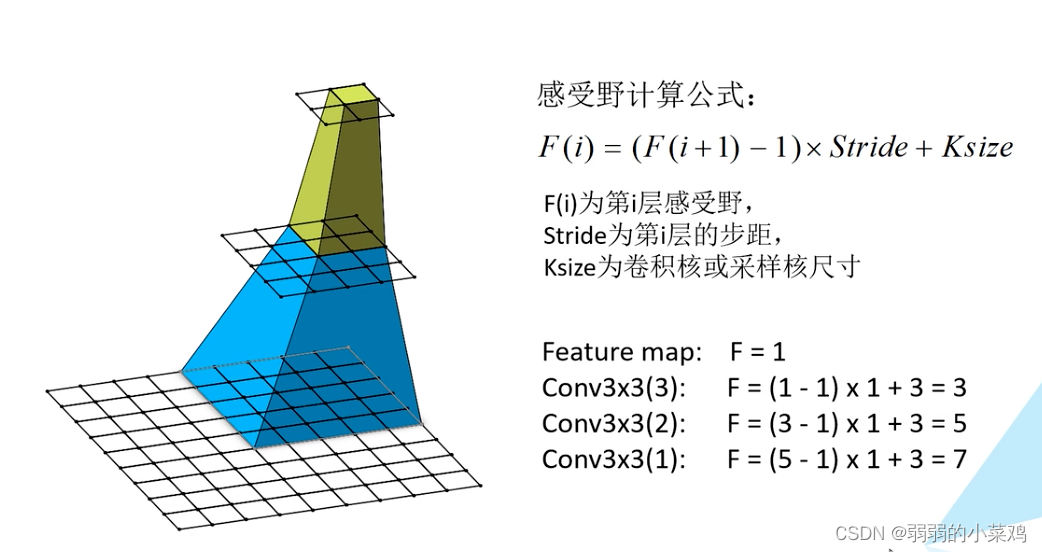
大尺度的卷积核卷积后的得到的feature_map 中的一个对应的原图中的尺度,称之为感受野。
使用这个操作的原因
这种小尺度的卷积核的堆叠的操作可以大幅度的减少我们的参数的量
比如我们用三层的3*3的卷积核的参数为:
d
a
t
a
=
3
∗
3
∗
c
∗
c
∗
3
=
27
c
2
data=3*3*c*c*3=27c^2
data=3∗3∗c∗c∗3=27c2
d
a
t
a
=
7
∗
7
∗
C
∗
C
=
49
∗
c
2
data=7*7*C*C=49*c^2
data=7∗7∗C∗C=49∗c2
通过上面的操作我门可以看到使用多个小尺度的卷积层的操作可以和大尺度的卷积层具有相同的感受野,但是却具备更少的参数量。
VGG网络的结构:

根据上面的网络的结构图,我们进行网路的构建如下:
model.py
import torch.nn as nn
import torch.nn.functional as F
import torch
#传入的cfg 是一个配置变量,
#定义一个初始化的VGG的类
#features有外部定义好后传入我们所定义好的VGG的类中
class VGG(nn.Module):
def __init__(self,features,clss_num=1000,init_weights=False):
super(VGG,self).__init__()
self.features=features
self.classifier=nn.Sequential(
nn.Dropout(p=0.5),
#随机失活百分之五十,减少过拟合
nn.Linear(512*7*7,2048),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048,2048),
nn.ReLU(True),
nn.Linear(2048,clss_num)
)
if init_weights:
self._initialize_weights()
def forwarf(self,x):
x=self.features(x),
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
# 初始化我们的权重
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
#nn.init.kaiming_normal_(m.weight, mode='fan_out', )
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias,0)
def make_features(cfg: list):
layers=[]
#定义一个空列表存储我们的定义的层结构
in_channels=3
for v in cfg:
if v=="M":
layers+=[nn.MaxPool2d(kernel_size=2,stride=2)]
else:
conv2d=nn.Conv2d(in_channels,v,kernel_size=3,padding=1)
layers+=[conv2d,nn.ReLU(inplace=True)]
in_channels=v
return nn.Sequential(*layers)
#非关键参数的传入
#我们网络的配置结构列表。
cfgs={
'vgg11':[64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'],
'vgg13':[64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'],
'vgg16':[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'],
'vgg19':[64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,512,'M',512,512,512,512,'M'],
}
def vgg(model_name="vgg16",**kwargs):
try:
cfg=cfgs[model_name]
except:
print("warning: model number {} not in cfgs dict:".format(model_name))
exit(-1)
model=VGG(make_features(cfg),**kwargs)
#定义的可变长度的字典变量
return model
vgg_model=vgg(model_name='vgg16')
print(vgg_model)
train.py
import torch
import os
import torchvision
import torch.nn as nn
from model import vgg
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import transforms,datasets,utils
import numpy as np
import json
import time
#导入一些必须的库
def main():
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform={
"train": transforms.Compose(
[transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]
),
#transfoerm 是图像的预处理的方法
#transforms.RandomHorizontalFlip()
#transform.Totensor :Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
#本质就是将读入的图片转换为tensor,并将原始的图像的维度由长乘以宽乘以通道数,变为通道数乘以长乘以宽
#Normalize就是对数据进行标准化的处理
"val": transforms.Compose(
[
transforms.Resize(224,224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)}
#获取根目录
data_root=os.path.abspath(os.path.join(os.getcwd(),"./."))
image_path=data_root+"/data_set/flower_data/"
train_dataset=datasets.ImageFolder(root=image_path+"/train",
transform=data_transform["train"]
)
train_num=len(train_dataset)
flower_list=train_dataset.class_to_idx
cla_dict=dict((val,key) for key,val in flower_list.items())
json_str=json.dumps(cla_dict,indent=4)
with open('class_indices.json','w') as json_file:
json_file.write(json_str)
batch_size=32
train_loader=torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
#windows 表示线程的数目,这里我们采用的是0
validate_dataset=datasets.ImageFolder(
root=image_path+"/val",
transform=data_transform["val"]
)
val_num=len(validate_dataset)
validate_loader=torch.utils.data.DataLoader(
validate_dataset,
batch_size=4,
shuffle=True,
num_workers=0
)
#查看训练集和测试集的batch中的图片的信息和label的信息
test_data_iter=iter(validate_loader)
test_image,test_label=test_data_iter.next()
# def imshow(img):
# img=img/2+0.5
# npimg=img.numpy()
# plt.imshow(np.transpose(npimg,(1,2,0)))
# plt.show()
# print(' '.join('%5s' %cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net=vgg(model_name='vgg16',clss_num=5,init_weights=False)
#实例化我们的模型,我们的model_name的网络的v g g 16
net.to(device)
#将我们的网络移植到初始化的设备上,cpu 或者GPU版本
Loos_function=nn.CrossEntropyLoss()
#定义我们的损失函数
optimizer=optim.Adam(net.parameters(),lr=1e-3)
save_path='./Alex.pth'
best_acc=0
#定义最佳的模型。
#定义我们自己的优化器
for epoch in range(10):
#此处调用这个可以在训练的过程中调用我门的dropoot方法
net.train()
running_loss=0
t1=time.perf_counter()
for step,data in enumerate(train_loader,start=0):
inputs,label=data
optimizer.zero_grad()
outputs=net(inputs).to(device)
loss=Loos_function(outputs,label.to(device))
loss.backward()
optimizer.step()
running_loss+=loss.item()
rate=(step+1)/len(train_loader)
a="*"*int(rate*50)
b="."*int((1-rate)*50)
print("\rtrain loss:{:^3.0f}%[{}->{}]{:.3f}".format(int(rate*100),a,b,loss),end="")
print(time.perf_counter()-t1)
#测试GPU设备
net.eval()
acc=0
#启动net.eval之后模型将开始关闭dropout的操作,防止继续进行模型的权重丢失的操作
with torch.no_grad():
#晴空梯度的信息
outputs = net(test_image).to(device)
predict_y = torch.max(outputs, dim=1)[1]
acc+=(predict_y==test_label.to(device).sum().item())
accurate_test=acc/val_num
if accurate_test>best_acc:
best_acc=accurate_test
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss:%.3f test_acc:%.3f'%(epoch+1,running_loss,acc/val_num))
print("finished training!")
if __name__=='__main__':
main()
predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import vgg
import json
import matplotlib.pyplot as plt
transform=transforms.Compose(
[transforms.Resize(224,224),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
#transfoerm 是图像的预处理的方法
classes={'daisy','dandelion','roses','sunflowers','tuplips'}
net=vgg(model_name='vgg16',clss_num=5)
net.load_state_dict(torch.load('vgg.pth'))
im=Image.open('1.jpeg')
plt.imshow(im)
im=transform(im)
im=torch.unsqueeze(im,dim=0) #[N,C,B,W]
#进行升维度的操作
#扩充维度
try:
json_file=open('./class_indices.json','r')
class_index=json.load(json_file)
except Exception as e:
print(e)
exit(-1)
with torch.no_grad():
output=torch.squeeze(net(im))
#进行降维度的操作
predict=torch.softmax(output,dim=0)
predict_cla=torch.argmax(predict).numpy()
print(class_index[str(predict)],predict[predict_cla].item())
plt.show()















 6920
6920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









