







 该论文提出了一种实时动态3D重建系统,通过遮挡融合技术解决了在线和离线方法的质量差距。利用LSTM和图神经网络,结合时空信息,对包括遮挡区域在内的物体全3D运动进行准确且高效的估计。实验结果显示,该系统在实时性能上超越了现有的离线方法。
该论文提出了一种实时动态3D重建系统,通过遮挡融合技术解决了在线和离线方法的质量差距。利用LSTM和图神经网络,结合时空信息,对包括遮挡区域在内的物体全3D运动进行准确且高效的估计。实验结果显示,该系统在实时性能上超越了现有的离线方法。
一、论文简述
1. 第一作者:Wenbin Lin
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:单目、3D重建、实时性、遮挡、LSTM
5. 探索动机:在基于单一视图的解决方案中,在线方法和离线方法之间存在显著的质量差距。在在线方面,现有的方法采用迭代几何拟合、稀疏图像特征匹配或光度约束来估计目标运动。然而,这些实时技术不能给出非常可靠的时间对应,因此运动估计的准确性是有限的。随着误差的累积,这些技术往往无法跟踪长序列或具有挑战性的运动。另一方面,离线方法可以在不考虑计算复杂度的情况下建立更精确的时间对应关系,从而得到更好的重建结果。
在基于单视图的三维动态重建中,遮挡是一个关键障碍,因为遮挡区域需要在没有运动观测的情况下进行重建。另一方面,遮挡区域不会任意移动。可见区域的运动和历史运动信息提供了强大的先验知识来约束被遮挡区域的运动估计。
6. 工作目标:结合在线和离线的优势,并且解决遮挡区域。
7. 核心思想:提出了遮挡融合,填补了在线和离线方法之间的质量差距,具有实时性能,甚至与离线方法相比具有最先进的准确性。这是通过更好和更有效地探索空间和时间的运动先验来实现的。在此基础上,提出训练神经网络,利用可见区域的运动以及历史信息来估计包括被遮挡表面在内的整个物体的全3D运动。通过在连续帧之间获得完整的物体运动,既不需要像DeepDe- form那样的完全对应计算,也不需要像Bozic等人那样的多帧之间的长距离对应计算。这两种方法都涉及到沉重的计算成本,从而阻碍了实时性能。
- We proposed a robust real-time dynamic 3D reconstruction system with a light-weight graph neural network for full 3D motion estimation.
- The graph neural network involves LSTM structure to leverage both the spatial and temporal information to predict the full object motion accurately and efficiently.
- Per node motion confidence is estimated by modeling the predicted motion using a Gaussian distribution, which gives more information for the reconstruction system to achieve high robustness.
8. 实验结果:
Various results including the one on public benchmark show that our real-time system outperforms the state-of-the-art offline methods.
9.论文下载:
https://wenbinlin.github.io/OcclusionFusion
二、实现过程
1. 方法
构建了一个基于RGB-D的单视图动态三维重建系统,该系统能够逐帧重建体模型和求解非刚体表面运动。输出运动通过节点图的变形参数化。为了处理遮挡节点的运动跟踪,设计了一个可感知遮挡的运动估计网络。该网络基于时空运动观测,推导出整个节点图的运动和运动置信度。完整的节点运动估计流程如下图所示。在给定一幅输入RGB-D图像和当前重建模型的节点图的情况下,首先用一个神经网络估计前一幅图像到当前输入图像的二维光流。然后,利用二维光流图像和深度图像,计算出可见节点的三维运动。将可见节点的三维运动和完整的节点图都输入到图神经网络中。同时,引入LSTM模块来整合节点的历史运动,将时间信息传递到图神经网络中。最后,图神经网络以每个节点的置信度预测全节点运动。利用预测的节点运动和置信度,进一步优化图节点的变形参数,构建鲁棒非刚性重构系统。
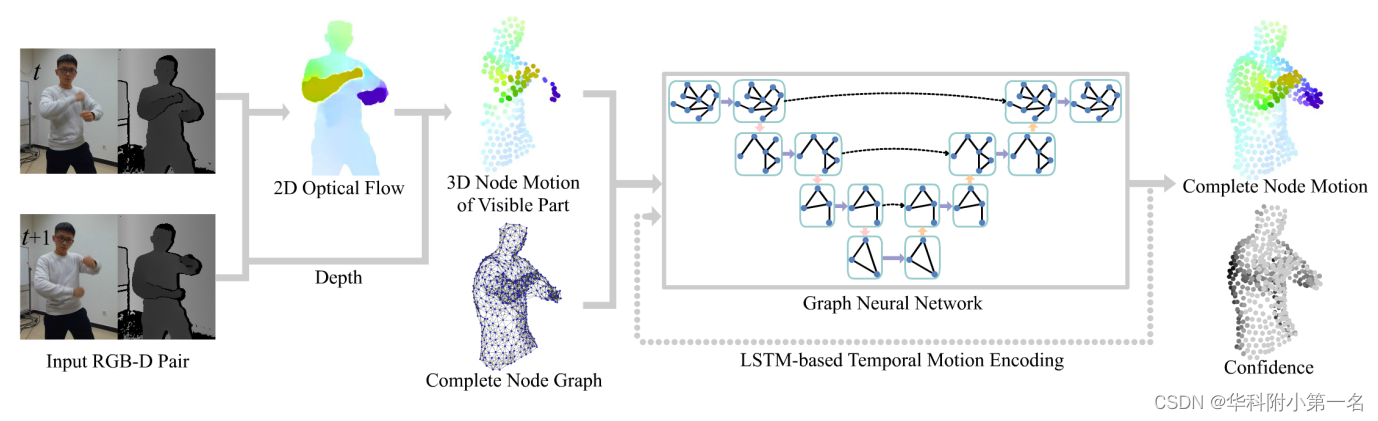
全节点运动估计的管道。给定帧t和t+1处的输入RGB-D图像以及帧t处的完整节点图,首先使用神经网络估计输入图像对之间的2D光流。然后,结合二维光流和深度图像计算可见节点的三维运动。图神经网络使用可见节点的运动和完整的节点图作为输入。与此同时,图神经网络通过LSTM模块来整合历史节点运动来估计完整节点运动和每个节点置信度。
2. 遮挡感知的运动估计网络
使用基于图的表示,用稀疏图节点来参数化物体运动。在目标曲面上对图节点进行均匀采样。物体表面上的点是由图节点的形变驱动的。然而,在单视角RGB-D相机中,当出现遮挡时,图节点的运动是很难解决的。为了解决这个问题,提出了一个使用图神经网络的遮挡感知运动估计器。
网络架构。图神经网络根据输入节点图的节点连接性在节点之间进行消息传递。如上图所示,图神经网络的目标是用每个节点的置信度预测整个节点图的运动。网络的输入包含完整的图结构、可见节点的运动和历史帧的运动。
具体来说,输入节点特征包括节点的3D位置和节点可见时的3D运动。对于被遮挡的节点,将它们的运动赋值为零。此外,添加一个额外的维度来表示节点的可见性。可见的值为1,遮挡的值为0。此外,根据可见节点的运动,通过在SE(3)中计算一个刚体变换,从总运动中提取刚体运动。因此,神经网络只需要预测非刚体运动。
由于单帧的观测强度不足以约束被遮挡运动,将历史运动和当前帧的观测相结合来计算图节点的特征。为了整合历史运动,通过引入LSTM模块来维护每个节点的运动状态。对于每个节点,LSTM使用估计的历史运动和置信度来预测节点在当前帧的运动和置信度。
为了对3D节点运动进行了有置信度的建模,采用对角协方差为N(µ,σ)的高斯分布来表示每个节点的运动,其中µ为预测的3D运动,σ为反映置信度的标准差。
对于节点间的消息传递,基于输入节点图,构造了一个多尺度图金字塔{G1,G2, G3,G4}。该网络,包含节点特征下采样、上采样,即同一层次金字塔之间的跳跃连接,如U-Net。基本的图卷积模块是图transformer。此外,在图卷积模块中增加了一个残差连接。
网络训练。为了监督网络训练,用预测的高斯分布对目标节点运动进行建模,并使用标准的对数似然损失:
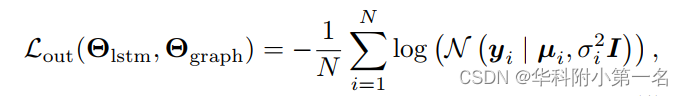
其中Θlstm和Θgraph是LSTM模块和图神经网络的参数,µi和σi是网络的最终输出,N是节点图中的节点数,yi 是第i个节点的gt运动。
对于LSTM模块的时域运动编码,对LSTM模块的输出施加另一个对数似然损失:
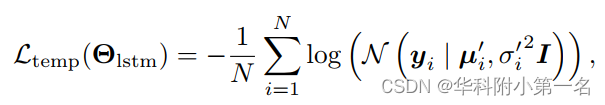
其中µi′和σi′为LSTM模块的输出。此外,发现截断σi的最小值和σi′到0.1会带来更好的性能。
总损失是上述两项的加权组合:
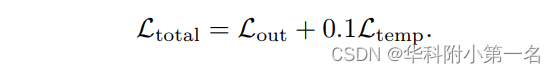
3. 置信度引导非刚性重建
对于非刚性RGB-D重建,遵循经典的体管道,使用截断符号距离场(TSDF)来存储标准模型和运动场来warp标准模型,使其与输入图像序列对齐。
我们使用基于图的表示来参数化非刚体运动。运动场W可以用变形图G = {[pi,Ti},其中pi∈ R3是第i个节点的位置,是Ti∈SE(3)是第i个节点的变换。运动场可以通过相邻节点transform的凸组合来计算。
给定重构模型Mt−1和输入RGB-D图像对{Ct−1,Dt−1}和{Ct, Dt},优化如下能量来求解Wt。
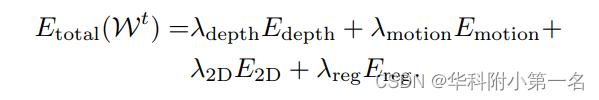
对于深度项Edepth,在深度图像Dt和warp的模型之间采用密集点对面对齐:
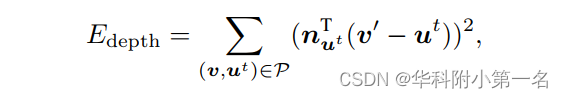
v是标准模型M上的一个顶点,v′是由Wt给出的warp顶点。ut是一个从深度图像Dt投影出来的3D点,其法线表示为nut 。P是顶点对集。我们首先在t−1处将warp后的模型Mt−1渲染到相机视图,并得到所有可见顶点的投影2D坐标。设Π为投影函数,对于Π(v'),利用计算得到的二维光流找到Π(ut)所在的对应像素。
基于神经网络的输出运动和置信度,将运动场约束为接近网络的预测,构造运动能量项如下:
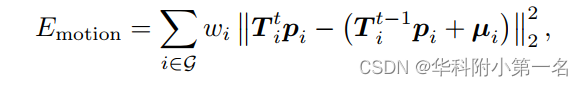
其中µi表示神经网络在第i个节点预测的运动,wi是通过µi和σi计算的权重:
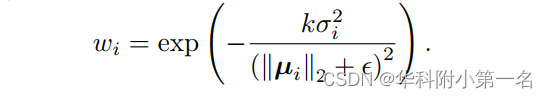
考虑到连续图像之间的密集对应关系,二维项将warp后的顶点的投影约束为与二维光流的对应关系一致:
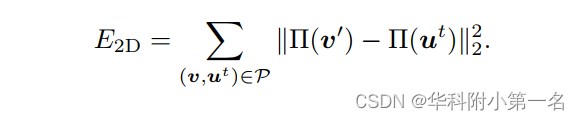
Ereg 是尽可能刚性的正则化,
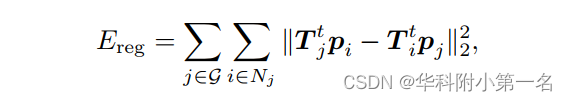
其中Nj表示第J节点的相邻节点。
在解出运动场Wt之后,更新规范后的TSDF体。如果存在超出当前节点图覆盖范围的区域,则将插入新的节点。
4. 实施细节
多尺度图金字塔构建。给出一个在目标曲面上采样的节点图,通过对具有不同节点间隔的节点进行下采样,构造了一个多尺度图金字塔。第(l+1)级的节点是第l级节点的子集。级别越高,间隔越大。对于节点间的边,在欧氏空间的第一层计算每个节点的k近邻。然后在图上使用宽度优先搜索来计算更高层次的邻居。
数据生成。网络训练依赖于对物体的全三维运动的监督。作者利用DeformingThings4D数据集,其中包含了1,972个动画,跨越了31个类人和动物类别。
为了模拟三维重建场景,首先对物体表面上的图节点进行均匀采样。然后,引入一个虚拟摄像机,使移动的物体保持在渲染的深度图像的中心。一旦一个图节点被摄像机看到,该节点将被添加到一个观察节点集n中。因此,观察节点的数量将随着时间的推移而增加。对于帧t,构建当前观测节点集Nt的图金字塔。根据节点的可见性,Nt可分为Nvist和Nocct。对于每个节点,计算时间相邻帧之间的3D位移作为它的运动,而只是Nvist的运动输入到网络。另外,将目标随机调整为1m×1m×1m到2m×2m×2m的三维边界框里,这是动态重建系统常用的体。
3D重建系统。在三维重建系统中,利用最先进的二维光流预测方法RAFT来估计输入图像对之间的光流。由于输入图像包含深度信息,我们在合成光流数据集sintel、FlyingThings3D和monka上使用RGB-D四通道输入对RAFT网络进行再训练。额外的深度通道有助于实现更高的精度,特别是当运动模糊发生在彩色图像。然后,利用深度图像计算图节点的可见性,将二维图像坐标反投影到三维空间,得到可见节点的三维运动。对于历史帧的3D运动,使用3D重建系统的输出,而不是网络的输出,因为它集成了更多的约束,通常更准确。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











