







Object Dedection一般分为one stage和two stage两种框架,one stage的代表有yolo系列、ssd等,two stage的代表有faster rcnn、light head rcnn、rfcn等,本系列会详细介绍这两种框架,会从yolov3 到 light head rcnn讲起:
首先是yolov3,下图贴出的是yolov3的框架图:

上述是yolov3的示意图,整个yolov3的完整可视化资源已上传网站,下载地址为https://download.csdn.net/download/weixin_41015185/10790747,如下载有问题请联系作者, 创建一个logdir文件夹,将下载内容放入,注意tensorflow版本是1.10,打开代码如下:
tensorboard --logdir=logdir
部分graph如下:
output_node:1

output_node:2

output_node:3

final_output:也就是decode的过程,网络输出的三种结果经过nms(非极大值抑制)处理生成最终结果:

此图是由pb文件生成,有了完整的graph我们就可以用c++做前向传播调用了,yolov3的完整输入输出结构,丢进一张图片,输出最终结果,即目标位置和分类,属于猫还是狗等,读者可以根据yolov3的相关代码结合此图了解整个框架。
假设我们有一张图片,如下所示:

模型训练时要做 random preprocessing for real-time data augmentation,也就是resize iamge(416,416)维数、flip image、distort image、correct box position等相关操作,获取如下图片结果示意:



这是通过data augment生成的训练数据。
如何从一张输入的图片得到用于训练的y_true值呢,也就是说我们整个网络三个output_node输出的结果是(1,13,13,3,4,1,80)、(1,26,26,3,4,1,80)、(1,52,52,3,4,1,80),其中3代表每个维度上对应的三个anchors,一共三个维度输出,一共9个anchors,4代表box坐标值,1代表box置信度,80代表目标分类得分,coco数据集是80分类,那么我们也要将输入的图片转换成相应维度的真值,我们原始输入是(416,416,3)维图片,box为(x1,y1,x2,y2,class)。那么我们将原始图产生的y_true(维度为[1,13,13,3,85]、[1,26,26,3,85]、[1,52,52,3,85])与预测产生的值也就是网络输出的三个output_node结果做loss进行优化。
y_true生成的过程:
首先我们给出的图片维度是(416,416,3),假设box的大小[241. 193. 275. 249. 0.],box的前四位数是box的坐标值,最后一维是class类别索引值,假如我们要做三个分类,那么输出维度就是[1,13,13,3,4,1,3],其他输出类似,比如这三个类别为猫、狗、羊,我们分别给猫狗羊打上标签为0,1,2 , 那么box的最后一个数就是代表那个分类。yolov3 给出了9个anchors,每三个anchors对应一个输出维度,通俗点讲,就是给除了9个大小不同的box,这9个box是根据给出的所有真值box聚类形成的,具体算法可以百度搜索k_means,这里假设是[10,13 16,30 33,23 30,61 62,45 59,119 116,90 156,198 373,326],数值为box的宽和高,这样既能感受大的物体,也能感受小的物体,[1,13,13,3,8]对应[116,90 156,198 373,326]三个box,[1,26,26,3,8]对应[30,61 62,45 59,119]三个box,[1,52,52,3,8]对应[10,13 16,30 33,23]三个box。好了,原始数据有了,那么我们怎么知道这个box[241. 193. 275. 249. 0.]是在[1,13,13,3,8]、[1,26,26,3,8]、[1,52,52,3,8]这三个维度当中那个坐标或者我们叫做索引值下呢,这里我将分类改成3个,而不是80分类,以便于理解。
下图为如何求解box中心格子位置索引(这里有个修正,2.5应该是2,以对应下面计算):

还有一个问题,我们一共由三个维度的输出(13,13)(26,26)(52,52),那么我们是如何知道这个box应该索引哪个维度呢,还记得吗,我们给出了9和anchors,每个维度对应三个anchors,那么最简单的原理就是我原始box和这9个当中哪个anchor最像,那么这个box的索引就是那个维度,同时我们也搞定了(1,13,13,3,8)(1,26,26,3,8)(1,52,52,3,8)的第三个数值3的位置,由此格子的位置和anchor的位置都有了。那么如何表述最像这件事情呢,用到的一个算法就是IOU,交并比的概念,不熟悉的可以百度。
[[0.06827731 0.25210084 0.39863445 0.81791626 0.48356511 0.27118644 0.18237548 0.06164206 0.01565815]],这里给出的是[241. 193. 275. 249. 0.]这个box和9个anchor求出的IOU值,在这里我们可以看出第三个索引值最像,也就是和[30,61]这个anchor最像,而这个anchor属于(1, 26, 26, 3, 8)这个anchor的第1个位置。
下面是对应的求解位置,读者可以自行验算:
box:[241. 193. 275. 249. 0.]
1.首先将box中心坐标和宽高归一化:[ 0.6201923 0.53125 0.08173077 0.13461539 0. ] 中心坐标计算(x2 + x1)/ 2 /416;(y2 + y1)/ 2/416;
2.属于(26,26)这个维度的第1个anchor位置;
3. (26,26)位置计算,0.6201923 × 26 = 16,0.53125 x 26 = 13;
4.那么将归一化的box填进y_true值,这里我们先前假设定义为(1,26,26,3,8)的零向量;y_true[1, 16, 13, 1, 0.6201923, 0.53125 , 0.08173077, 0.13461539, 1, 1, 0 ,0] ,因为我们box的最后一维是0,也就是属于猫类,做one_hot,也就是[1 0 0]代表猫,[0 1 0]代表狗[0 0 1]代表羊,第8个维度是1,代表box的置信度。
5.自此除了[1, 16, 13, 1]这个位置有值以外,其他位置全部为0,那么我们真实的y_true就这样产生了。
神经网络架构:
darknet采用了类似FPN的upsample和融合做法,最后融合了三个scale,这么做的目的是为了加强对小目标的检测,下面就主要说下这个是怎么实现的,也就是scale1,scale2和scale3之后的部分,之前的部分在很多博客中都有了,其实如果你下载了我给出的可视化资源链接,用tensorboard打开看一下,很清楚的就了解了darknet的整个网络架构了。如下图所示:

这是整个网络的基本结构。
loss函数及框的预测:
这里先将以下RCNN的框的预测,以便于好理解一点,看图:

其中tx = (Gx - Px)/ Pw; ty = (Gy - Px) / Ph; tw = log(Gw/Pw); th = log(Gh/Ph)。
关于Bounding-Box Regression论文中是这么说的,用一个分类检测器SVM(支持向量机)给每一个选择性搜索区域打分之后,用一个指定分类bounding box 回归器预测一个新的bounding box,输入到CNN里面的训练数据时{(Pi,Gi)},Pi定义为(Pxi,Pyi,Pwi,Phi),同样G也是如此定义,目的就是学习一种变换,将框P映射到真值G上。用四个公式dx(p),dy(P),dw(P),dh(P),来定义这种变换,前两个参数指定了P中心坐标的尺度不变变换,后两个参数指定了P的高和宽在log空间的变换,当学习完这些参数后,那么我们就可以将P变换成G^,如平移公式和缩放公式,最终到公式3。在预测框时,定义IOU值为大于0.6的进行回归,这样做是为了满足近似线性转换条件,想一下,如果P跟G离得很远,就是复杂非线性问题了,这样会导致训练的模型不work,为什么IOU较大时认为是近似线性变换呢,看公式1和公式2就大体了解了,那么问题就有答案了,看公式4和公式5,我们有了真正tx,ty,tw,th,我们学习一组参数Wi,,经过学习之后loss降到最低,现在Wi的值有了,我们丢进去一张proposal的图像,那么我们是否就预测出了tx,ty,tw,th的值了呢,有了这些值,是否就是可以计算最终回归的框了呢,答案是肯定的。
好了,RCNN的bounding box regressiogn的故事就讲完了,如果有误示,请指正,回归到YOLOV3本身上来,我们看下YOLOV3是怎么做的回归的。
同样是先把这个图和公式给贴上来:
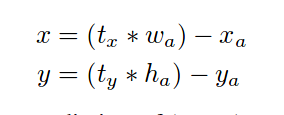

先做真实值,还记得RCNN吗,我们是怎么做的,由RCNN我们可以想到在训练的时候bx,by,bw,bh就是我们的ground truth,注意,我这里的说的训练的过程,而不是预测过程,不能混淆,那么先前我们已经定义了y_true了,我在这里在写一此,它的值为[1, 26, 26, 3, 8],那么就这么定义tw =log(y_true[..., 2:3] / anchors * 416),后先搞清楚一点bw是什么,因为y_true是我们归一化的框的值,那么我们是不是应该还原回去,乘以个416,所以bw = y_true[..., 2:3]*416,这是bw代表的ground truth是不是就有了呢,似曾相识的感觉,对了这就是RCNN的概念,这也是我要把RCNN贴出来做例子了,同样的道理,th也是这样计算的,那么在看tx和ty,因为这里有区别与RCNN,直接写,sigmoid(tx) = y_true[..., 0:1]*26 - grid,这里说下grid也就是论文中的cell,那么bx = y_true[..., 0:1]*26,很好理解吗,中心坐标也是归一化的,我要知道它在那个格子里面,是不是也要乘以26,这个前面已经提到了,到此位置我们用y_true产生的tx,ty,tw,th就产生了,这也就是anchor在这里的作用。















 4610
4610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









