









留个笔记自用
REFORMER: THE EFFICIENT TRANSFORMER
做什么
点云的概念:点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量点集合,在获取物体表面每个采样点的空间坐标后,得到的是点的集合,称之为“点云”(Point Cloud)。
点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等,不一一列举。
一般的3D点云都是使用深度传感器扫描得到的,可以简单理解为相比2维点,点云是3D的采样

做了什么
众所周知的大型transformer这种东西很费时间,时间复杂度是O(n2)级别的,这里引入了两种方法来提高效率,首先第一是用位置敏感散列来代替矩阵的点积,从n2变为L×logL,这里的L是序列长度。第二种是用逆残差层来代替标准残差,这两者就构成了这篇文章所构建的变种结构,reformer
怎么做
首先依然是回顾一下传统transformer的做法
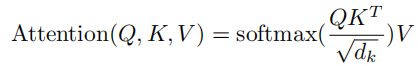
这里的QKV就是常见里的query查询矩阵、Key键矩阵、Value值矩阵
显而易见的就是这里用的矩阵点积来计算QKT这是一个非常消耗资源的方法,假设序列长度为64K那得到的结果就是一个64K×64K的矩阵,大的离谱,所以就产生了一种简单的内存优化方法
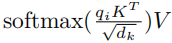
也就是不采用矩阵直接相乘的方法,而是采用向量和矩阵相乘,这样存储的结果仅仅只需要64K
而至于构造QKV的方法,常常是用的不同的线性层直接构造然后
这里提到了一种的LSH attention(Locality sensitive hashing),则是构造成了Q=K,V单独的形式,除此之外,为了效率就使用了前面的Locality sensitive,也就是局部敏感,构造的方法就是对于每个qi,原本前面提出的方法是根据每个q向量单独和K矩阵计算,得到的结果仍然是64K的,但常常需要计算关系的邻居仅仅只需要少量attention,所以就打算只取32或64个最接近的键,最大程度的减小内存消耗
所谓的Locality sensitive也就是对向量哈希,能在高维空间比如前面说的64K空间中找到最相邻的64个邻居
接下来就是哈希的方法

先看看图,存在两个点x和y,假设对其做一个旋转,通过argmax来对其进行2d投影,对于三个不同的角散列,两个点x和y不可能共享相同的散列桶,除非它们的球状投影接近
简单来说这里就是构造了一个类线性的方式对点嵌入进行投影,使其邻近关系更容易被寻找到
首先创造一个随机矩阵R∈Rdk×b/2,然后定义哈希方式是
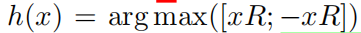
这里的x是序列中每个词(点云中每个点)的嵌入向量,计算xR和-xR后concat起来,再使用一个argmax得到哈希值
接下来就是计算LSH attention的方法
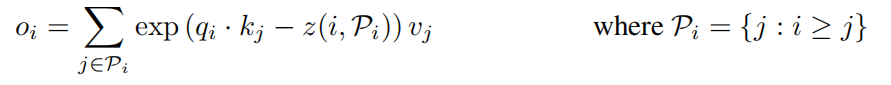
这里的z是分区函数,文中说是softmax里的norm函数,Pi就是对位置i的查询关注的集合,也就是i>j的点,因为理论上来说,注意力是无法从未来照顾现在的。
简单理解一下,就是对每个点i的qi,计算它和第j个点的k向量,然后减去i相对于集合pi中其他点的嵌入正则值,也就是对i点的嵌入做一个正则化,然后乘上点j的值向量后exp累加,也就是softmax那一套,这里就用到了前面说的内存节约方式,采用逐向量计算而不是矩阵计算
然后构造成batch处理形式

整体架构跟前面的差不多,这里就是构造了一个m去屏蔽那些Pi里没有的元素,当然这种情况只会在批处理中出现
然后ASH的关注点可以限制在一个查询位置上

这里的h是哈希函数,也就是让点i的查询向量和点j的键向量高维度邻近

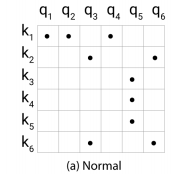
上图展示了哈希attention的好处,常见的attention就是a情况,很显然矩阵是非常稀疏的,因为理解上来说每个点之间的关系是有限的,自然矩阵就是稀疏的,但常见的点积运算没有使用到稀疏这一特点。
在B情况下,bucketed也就是哈希桶排序,Q和K已经进行了排序,这样的情况下,相似也就是邻域很大肯能会落在同一个桶也就是同一个哈希位置中,这时候只允许它同哈希位置桶内进行attention,效率较高且效果也不错,但因为桶位置是根据前面的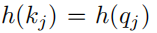
计算的,每个哈希桶内元素不定
这里设置了
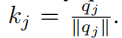
为了确保元素数量相同
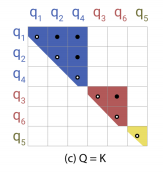
接下来因为矩阵采用了LSH attention的方式,也就是Q=K的情况,使得产生了上图的C情况也就是关系点集中于对角线,就可以采用chunk方式

简单来说,这里就是对根据前面定义的attention矩阵计算方法得到的那个关系矩阵进行改变

首先先是q和k分别进行排序,这样使得矩阵稀疏点大部分集中
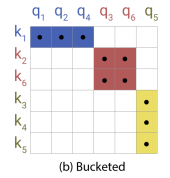

然后ASH attention中Q=K的情况

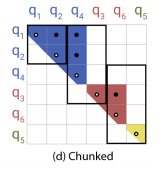
最后则是设置了一个chunk其实就是分块计算块内attention,m个连续查询的块互相关注,每个bucket里的query都可以attend to自己以及前一个bucket中相同哈希值的key

然后又加了一个常见的做法,mul-head
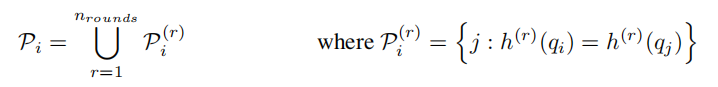
主要和常见的mul-head的区别是这里要采用多种哈希函数,因为哈希做法始终不能保证相似的输入一定在一个bucket中,它可能是相邻的,但仅仅差了一点点(指在边界)就会完全不相同
这就是文章的第一部分,也就是前面说的位置敏感散列代替点积的方法
然后是第二部分逆残差层
这里使用的是2017的一个网络Revnets,主要思想是每一层的activation可以根据下一层的activation推导获得,从而不需要在内存中存储每层的activation,在原本计算中比如Resnet,得到输出的方法是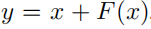
也就是输出等于当前层和未来层构成的F函数(残差函数)一起组成
而在Revnets当中,首先将输入x分成两个部分x1和x2,通过两个不同的残差函数F和G分别得到

显然这里就可以构成上面的说法,从未来层得到当前层的activation,这里仅仅只需要一个小小的移项

同理就可以用在Transformer当中以减小内存用量

也就是不用存每层的activation值
最后再将前馈层分块
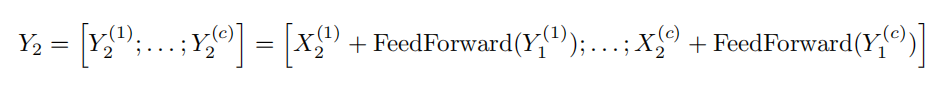
总结
1.这篇主要是为了解决NLP中大序列的问题,而我所需要的领域是点云领域,所以参考价值不算很大,但哈希的方法可以借鉴,这种sort方法和Sinkhorn Attention比较相似















 795
795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









