







论文《Structural Information Enhanced Graph Representation for Link Prediction》阅读
论文概况
本文是2024年AAAI上的一篇论文,文章从理论上分析了 GNN 在信息感知和传输方面对于链路预测的两个固有缺陷,并通过实验发现了邻居节点特征的有害影响。为了解决这些问题,作者提出了一种结构信息增强的链接预测框架,该框架涉及去除邻居节点特征,同时通过 GNN 拟合更集中的邻居结构,并引入 BST 来编码目标节点之间的结构关系,补充 GNN 的缺陷。
Introduction
链接预测是根据图中现有的节点和边来预测缺失或潜在的边的任务,其典型应用包括知识补全、推荐等。链路预测的方法有很多种,其中基于图神经网络(GNN)的方法因其良好的性能和效率而成为主流。
GNN在许多领域取得了很好的成果。它们以某个节点为中心,通过消息传递(MP)将相邻节点和边的特征聚合到中心节点,善于学习节点表示。
但是GNN对图进行编码时,专注于捕获以节点为中心的邻居信息,而没有感知目标节点对的结构关系。
最近,一些工作尝试通过节点标记技巧来解决这个问题。例如:ID-GNN:对目标节点进行着色以将其与邻居节点区分开来;SEAL:计算封闭子图中所有节点的 DRNL(双半径节点标签)。
问题一:现有的节点标记技巧只能帮助感知路径深度,而缺乏对路径“宽度”的感知,例如节点度或路径数量
此外,它们仍然受到 GNN 的 MP 范式的限制,导致链路预测的信息感知和传输方面存在缺陷:一方面,邻居节点标记收敛到目标节点然后聚合成关系表示的方式是隐式且复杂的,可能存在信息丢失的风险。另一方面,GNN 的感受野可能不足以进行链接预测。
问题二:GNN 是以节点为中心的模型,其感受野是中心节点的邻域。然而,链路预测中的一些目标节点可能相距很远,GNN 很难捕获它们之间的远程信息。
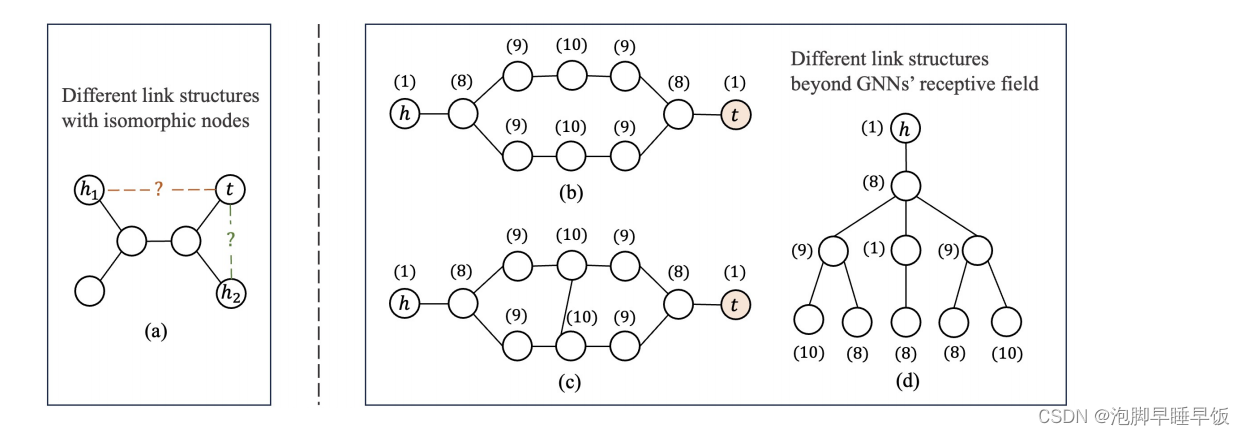
图 1:GNN 失败的链接预测案例。在(a)中,节点h1和h2是同构的,但链路(h1,t)和(h2,t)不是同构的。 (b)和©显示了两种不同的结构,(d)显示了头节点h的公共计算图。
图 的右侧部分显示了一个简单的示例,其中 ID-GNN 和最常用的 3 层 GNN 的 SEAL 都无法区分(b)和(c)中所示的两种链接结构。当使用 GNN 计算头节点 h 的表示时,两种结构中的计算图(包括节点的 DRNL)是相同的,如图(d)所示,尾节点t的颜色没有聚合。因此,即使使用标签技巧,3 层 GNN 也无法区分这两个链接结构。
问题三:为了增强 GNN 的远程信息捕获能力,需要增加 GNN 层数以扩大感受野,但这可能会导致过度平滑和过度拟合等问题。
在本文中,作者提出了一个额外的注意力模块来弥补 GNN 在捕获成对结构和直接学习目标节点之间的关系表示方面的不足。
自注意力是学习成对关系的强大机制,如Transformer,但它缺乏感知元素结构的能力。
问题四:计算是在所有元素之间成对执行的,导致计算复杂度呈二次方,并且大量参数导致数据饥饿问题。
为了捕获目标节点的成对结构特征,作者引入拓扑编码来编码成对启发式,例如最短路径距离(SPD)、Adamic-Adar等,并将它们融合到注意力中。
此外,作者的编码目标不是全局信息,而是 GNN 遗漏的目标节点的成对结构,将注意力计算限制在目标节点上,避免昂贵的计算和引入来自其他节点的噪声的风险。因此,所提出的注意力模块专注于目标节点并有效地编码结构特征:二元结构注意力(BSA)。
问题五:一些工作对图学习中的邻居提出了质疑,邻居特征在链接预测中的是否必要?
作者尝试删除邻居节点特征。以表 1 中的 SEAL(在 ogbl-ppa 和 ogbl-引用2 上使用 NGNN)为例,我们观察到没有邻居节点特征的情况下的改进(实验设置与实验部分和附录中描述的建议方法相同)。这种现象与直觉相矛盾,但似乎是可以解释的:在链路预测中,邻居节点特征可能与任务无关并且容易产生噪声。例如,在预测配偶关系时,关键信息可能是两个人有一个共同的孩子,但孩子的兴趣、电话号码和其他特征可能并不重要。
对于上述问题,作者提出了一种用于链路预测(Structural Information Enhanced GraphS,IEG)的结构信息增强图表示框架。一方面,我们使用GNN收集目标节点的邻域信息,去除邻居节点特征,使模型更加关注结构特征。另一方面,引入(二元结构注意力)BSA对目标节点的成对特征,特别是远程结构特征进行编码,以补充GNN的不足。该方法方法在六个流行的基准测试中显示出卓越的性能,包括在 ogblppa、ogbl-itation2 和 Pubmed 上排名第一。
Method
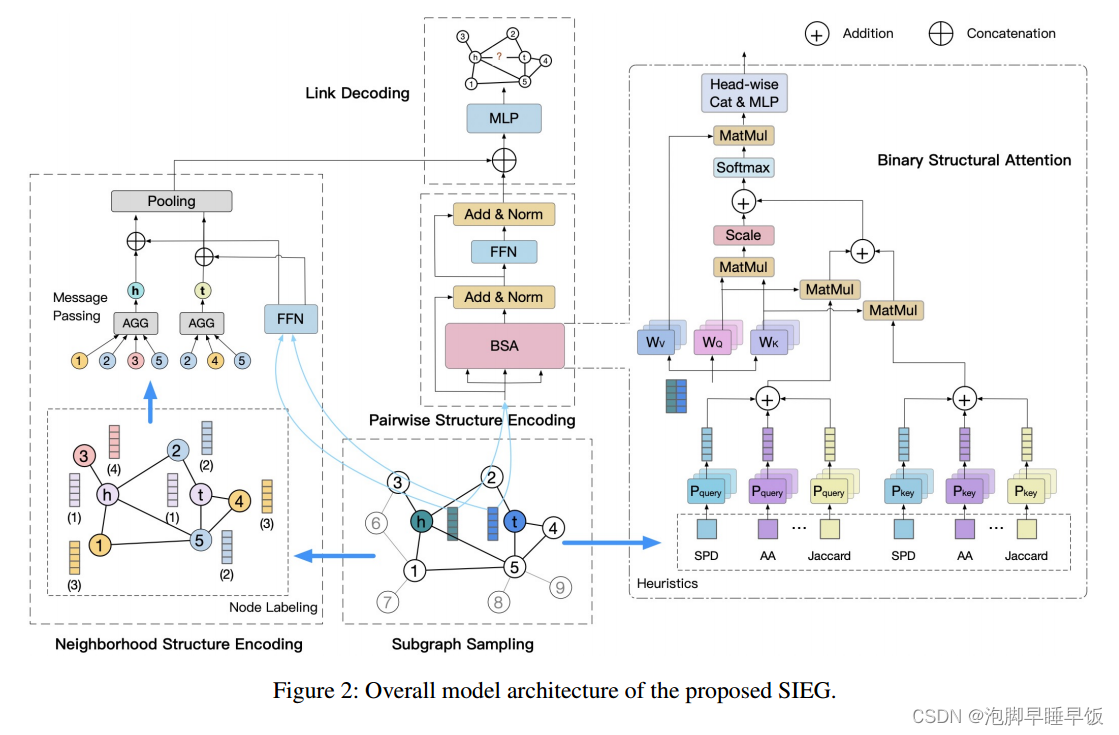
整体架构。如图2所示,所提出的链接预测框架由四个主要部分组成:子图采样、用于邻域结构编码的结构信息增强GNN、用于成对结构编码的二进制结构变换(BST)和链接解码
模块一:子图采样
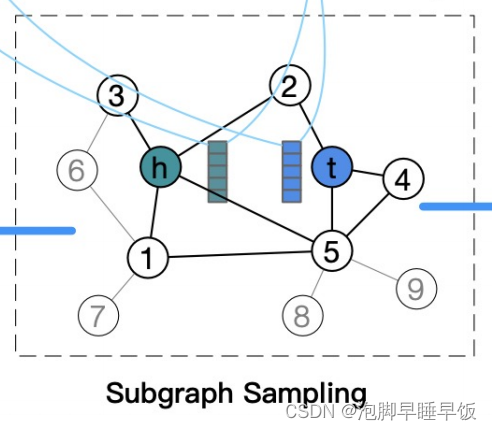
子图采样给定一个目标节点对 (vi , vj ),我们对其周围的 k 跳封闭子图进行采样。该子图由每个目标节点周围的两个 k 跳子图的并集组成,两个子图之间的边也被合并。例如,在图 2 中,超出 1 跳的附加边 e1,5 包含在目标节点对 (h, t) 的 1 跳封闭子图中。与普通子图相比,封闭子图为链接预测提供了更好的连接性和更多信息输入。 WLNM已经证明,不仅一阶和二阶启发式特征可以在封闭子图中直接计算,而且即使是高阶启发式特征在少量跳数下也是可行的。
模块二:邻域结构编码

为了对邻域结构进行编码并学习每个目标节点的表示,可以使用任何 GNN。 GNN 通过以节点为中心的 MP 聚合邻域信息,典型形式如下所示:

归一化邻接矩阵、单位矩阵、节点嵌入矩阵、线性参数矩阵。
通常,可以通过聚合目标节点的各自嵌入来获得相似性表示。在这项工作中,我们采用了SortPooling 形成相似度表示。
为了增强对结构信息的拟合,作者删除了邻居节点特征以避免潜在的噪声,使模型更加关注目标节点的邻居结构。具体来说,输入到 GNN 的信息不包含任何节点特征,而是采用 DRNL 编码的结构特征。 DRNL对子图中每个节点与目标节点之间的距离进行编码,具体形式为:

另一方面,目标节点的节点特征用附加的前馈网络(FFN)进行编码,然后在池化之前与 GNN 编码的结构表示连接。
模块三:成对结构编码
使用标签技巧,GNN 框架对于链接预测也存在两个局限性:由于感受野受限而缺乏远程结构信息,以及以节点为中心的模型和以链接为中心的任务之间的冲突。为了解决这些缺点,作者提出了BST来专门捕获目标节点之间的成对结构和特征相似性,直接表示关系并补充GNN的局限性。
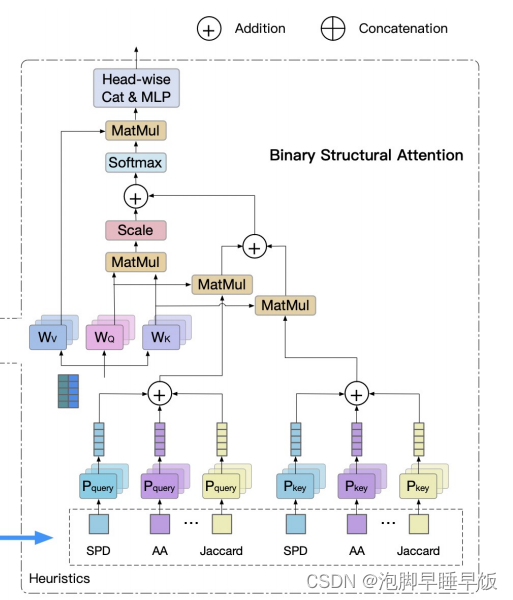
BST 的核心 BSA 的计算如图所示。该过程涉及两个输入:目标节点的特征和目标节点对的结构特征。后者使用启发式方法计算,如最短路径距离(SPD)、最短路径数(SPN)、公共邻居(CN)、杰卡德指数、阿达米克-阿达尔指数(AA)等。例如,Jaccard 和 AA 计算为

除了描述节点对的连接路径之外,Jaccard 和 AA还分别引入目标节点的边数和共同邻居的度,以进行归一化。此外,作者还采用结构查找嵌入结合节点特征嵌入来获得结构编码,从而增强结构信息的表示:
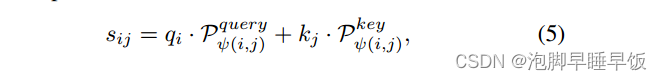
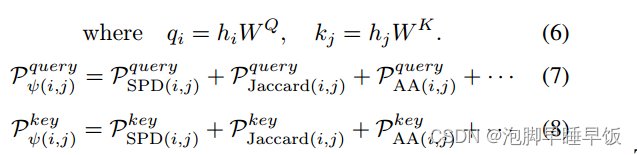
其中Pquery(SPD)和P key(SPD)表示以SPD作为两个单独的参数化表P query和 P key的索引 查找 获得的两个结构向量,从其他启发式方法获得的结构向量遵循相同的过程。然后,将所有查询结构向量用公式7,8聚合。
然后,通过公式5将两个结构向量分别与 qi 和 kj 相乘,并将它们相加以获得结构编码,记为 bij 。这里,qi和kj是目标节点特征的线性变换,WQ和WK表示变换矩阵。这有效地将丰富的启发式结构与节点特征融合起来,表征了目标节点的结构相关性。最后,将结构编码 bij 合并到注意力系数 aij 中:
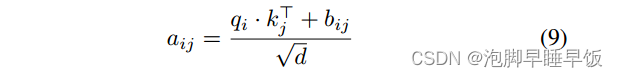
其中 d 是 qi 的维度。为了获得单头 BSA 的结果,我们将 softmax 归一化注意力系数与值嵌入相乘,然后将多个头连接起来形成多头 BSA:
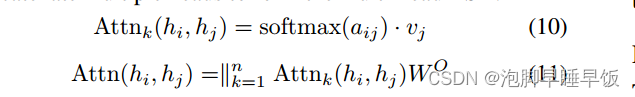
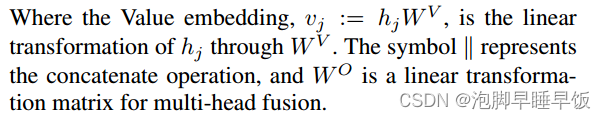
其中值嵌入 vj 是 hj 到 WV 的线性变换。符号∥表示concatenate操作,WO是多头融合的线性变换矩阵
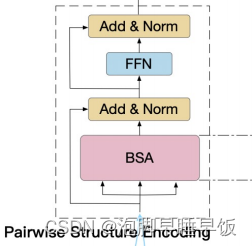
最后,BST 块由 BSA、层归一化 (LN)、残差连接 和 FFN 组件组成,如图 2 所示。与常规 Transformer 类似,成对结构编码模块 BST,是通过堆叠多个BST块得到的。
与常规 Transformer 相比,所提出的 BST 具有多个优点:
1.避免了远离目标的节点引入的潜在噪声和过度泛用风险。
2.收集更多与任务相关的结构信息。
3.计算复杂度大大降低。
模块四:链路解码
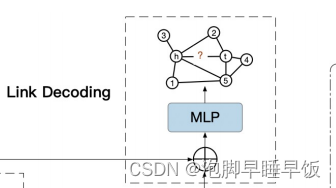
一般来说,邻域嵌入和成对嵌入可以与任何专门设计的技术融合,以获得良好的链接预测结果。模块最后连接嵌入以形成关系表示,并使用多层感知器(MLP)将其解码为链接分数。这个过程被表述为

复杂度计算

与 FCA 相比,BSA 显着降低了计算复杂度。 FCA 需要两个主要的计算成本:SPD 搜索和注意力计算,复杂度分别为 O(N(N + E) log N) 和 O(N2D + ND2 )。这里,N和E表示子图中的节点和边的数量,D表示节点特征的维度。相比之下,BSA 的计算复杂度远低于 FCA,如表 2 所示,SPD 的计算复杂度仅为 O((N + E) log N),Attention 的计算复杂度为 O(D2 )。
Transformer 的整体计算成本与 SPD 和 Attention 的计算成本之和成正比。因此,从全连接Transformer (FCT)到BST的加速比范围为N到N2,当N<D或N>D时,可以分别近似为N或N2。 BST 有效地解决了 Transformer 在链路预测中计算成本高昂的问题,使 SIEG 能够应用于更大规模的数据集。
表现力
Weisfeiler-Lehman 测试(Weisfeiler and Leman 1968)是一种广泛使用的图同构测试,并且已经证明(Xu et al 2018)消息传递 GNN(MPGNN)的表达能力,例如 GCN、GraphSAGE 和 GAT ,以一维 WeisfeilerLehman (1-WL) 算法为上限。具体来说,1-WL算法无法区分具有相同子树但不同子结构的节点。因此,基于 MPGNN 的 GAE 无法区分涉及这些目标节点的链路结构。相比之下,所提出的 SIEG 能够通过提供不同的表示来有效地区分此类结构,甚至超出 GNN 的感受野。这意味着 SIEG 超越了 1-WL 测试并克服了 GNN 的消息传递限制。
实验
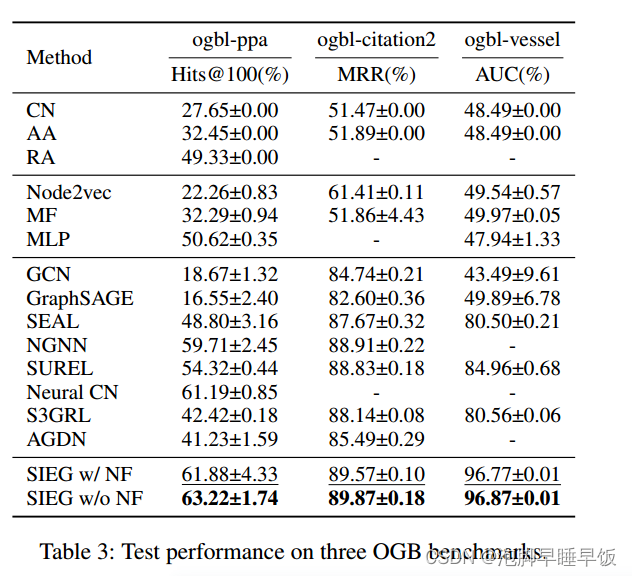
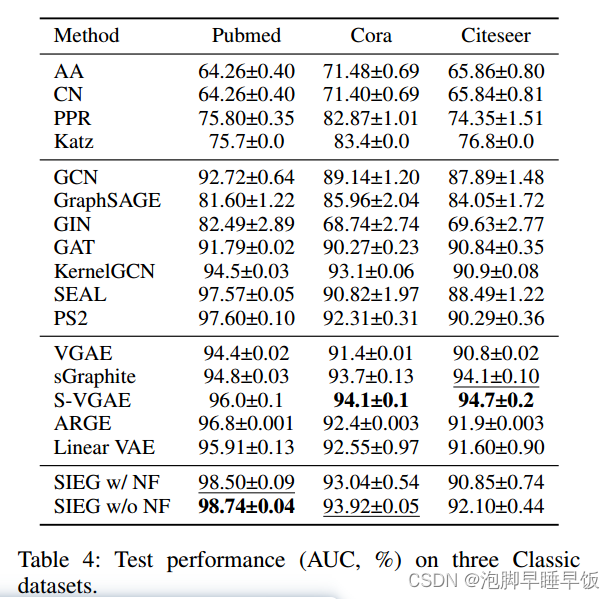
与基线的比较。表 3 报告了所提出方法的性能、具有和不具有邻居特征的 SIEG(带和不带 NF)以及三个 OGB 基准的基线。所有基线结果均取自 OGB 排行榜2。表 4 展示了 SIEG 和经典数据集上的基线的性能,基线结果取自相应的论文。
所提出的方法在所有数据集上都取得了有竞争力的结果,包括在 ogbl-ppa、ogbl-itation2 和 Pubmed 上排名第一。与较小或稀疏的图相比, SIEG 在较大或较密集的数据集上更为明显(附录中提供了每个数据集的统计数据)。对此的一种可能的解释是,较大的图可能包含更多的远程目标节点对,而较密集的图可能会引入更多来自邻居特征的噪声,而 SIEG 旨在解决这一问题。
消融实验
为了研究 SIEG 中不同模块和特征的影响,作者首先通过添加邻居特征、删除 BST 和删除 GNN 分别创建基于 SIEG w/o NF 的三个变体。其次,我们在 SIEG w/o NF 中用 FCT 替换 BST,得到 SIEG (FCT) w/o NF,然后通过添加邻居特征、删除 GNN 和基于 SIEG (FCT) w/o NF 创建了三个变体分别删除 FCT(导致与 SIEG 相同的变体,不含 BST)。表 5 列出了六个数据集上的结果。然而,由于二次复杂度,具有 FCT 的模型很难在 OGB 数据集上运行。
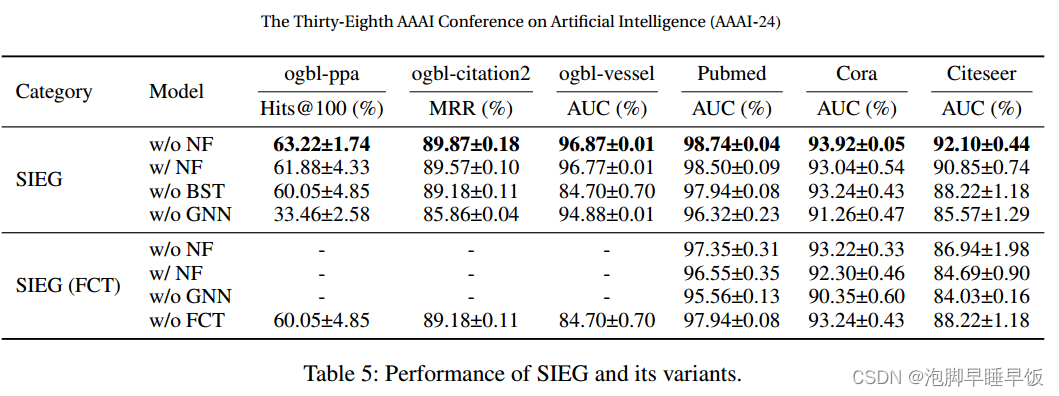
通过将 SIEG 的每个模型与 SIEG 的相应模型(FCT)进行比较来分析跨类别结果
计算效率
在图 3 中展示了 SIEG 和 SIEG (FCT) 在小型数据集 (Cora) 和中型数据集 (ogbl-itation2) 上的时间消耗结果。
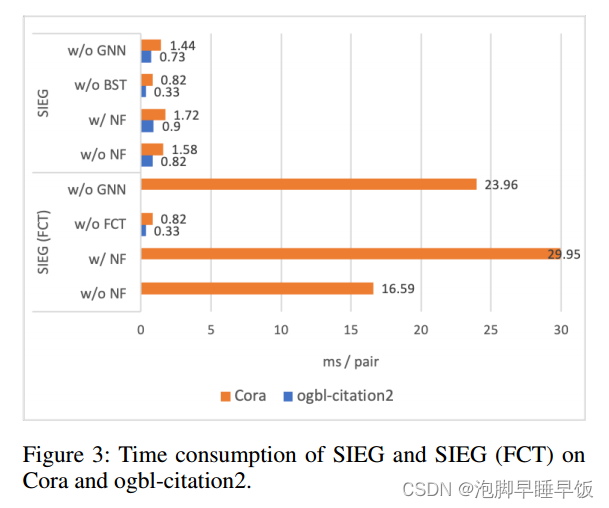
正如方法论部分的理论分析,FCT 和 BST 之间的计算成本比率范围为 N 到 N2 。实验上,Cora 上的结果表明,SIEG w/o NF 的运行速度比 SIEG (FCT) w/o NF 的运行速度快 10 倍,SIEG w/o GNN 的运行速度比 SIEG (FCT) w/o GNN 的运行速度快 16 倍,这证明了显着性BST相对于FCT的效率优势。当处理中等大小的ogbl-引用2时,带有FCT的模型几乎无法运行。
案例分析
用一个简单的例子来说明 SIEG 如何利用成对结构特征进行链接预测。在 Cora 测试集上,SIEG 为具有目标节点 ID(1111、1273)的正出版物对分配 8.22 的高分,并预测它们之间的引用关系。对该对的成对结构特征的检查显示 CN 分数为 4,AA 分数为 2.21,表明存在 4 个未被广泛引用的常见引用,这应该是SIEG推断其引用关系的重要原因。
总结
本文从理论上分析了 GNN 在信息感知和传输方面对于链路预测的两个固有缺陷,并通过实验发现了邻居节点特征的有害影响。为了解决这些问题,作者提出了一种结构信息增强的链接预测框架,该框架涉及去除邻居节点特征,同时通过 GNN 拟合更集中的邻居结构,并引入 BST 来编码目标节点之间的结构关系,补充 GNN 的缺陷。所提出的方法在六个流行基准上取得了显着的结果,包括在 ogbl-ppa、ogbl-itation2 和 Pubmed 上排名第一。














 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









