






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
在本周,主要是动手实现上周复习的卷积神经网络,代码实现验证码辨认,整个实现过程主要分为几个步骤,收集训练数据、构建网络结构、训练模型、测试模型。在其中获取数据方面,是利用电脑自动生成,这样就能快速拥有标注过的数据。网络结构则是三层卷积层以及两层全连接层。经过几次训练可以得到结论,随着数据量的增加,模型辨认的准确度越来越高。
Abstract
This week, I mainly implemented the Convolutional Neural Network that we reviewed last week to recognize captcha. The whole implementation process is mainly divided into four steps: collecting training data, building network structure, training model and testing model. In the aspect of data acquisition, I used the computer to generate automatically so that I can quickly have the labeled data. The network structure includes three layers of convolutional layers and two layers of fully connected layers. After several training sessions, we can draw a conclusion that the accuracy of model recognition is getting higher and higher with the increase of data size.
CNN模型训练–验证码辨认
1、代码实践
上周的任务主要是回顾已经学过的卷积神经网络CNN模型的相关知识,对其这个框架的认识再次刷新,印象更加地深刻。当然除框架之外,还对其框架的各层次(卷积层、激活层、池化层、全连接层和输出层)的工作细节都复习了一遍,再次了解这些知识以后,就要开始收集资料,学习相关知识,动手对这些知识进行复现,这样能让自己对这些知识的认识更加地深透。
2、明确训练需求
因为在本科时候,因为疫情的原因,需要每天进行健康打卡,因为过程繁琐,于是想弄一个电脑脚本能自动进行健康打卡,万万没想到,最后因为需要进行验证码验证让整个过程无法再进行下去。在学习完机器学习的相关课程之后,验证码的难题可以通过卷积神经网络对其进行学习辨认得到,于是这次的代码实现就想实现这个未了结的心愿。
3、收集训练数据
神经网络的训练对数据要求比较高,为了获得更好的神经网络模型,就需要准备高质量、多样性、被标注和平衡的数据集。在从前可能比较难收集相关数据,但是现在有许多的数据类型数据库,比如对于CNN友好的ImageNet图像数据库。这次的验证码的数据可以通过captcha封装类的方法来自动生成,这样就能有效地获得高质量,满足神经网络成长的数据。具体的生成代码如下:
from captcha.image import ImageCaptcha
from PIL import Image
import random
NUMBER = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
ALL_CHAR_SET = NUMBER + ALPHABET #定义验证码的内容,为数字和字母
ALL_CHAR_SET_LEN = len(ALL_CHAR_SET) #所有数据集的长度
MAX_CAPTCHA = 4 #验证码的个数
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
def random_captcha(): #生成对应的验证码文本
captcha_text = []
for i in range(MAX_CAPTCHA):
c = random.choice(ALL_CHAR_SET)
captcha_text.append(c)
return ''.join(captcha_text)
def gen_captcha_text_and_image(): #生成验证码图片
image = ImageCaptcha()
captcha_text = random_captcha()
captcha_image = Image.open(image.generate(captcha_text))
return captcha_text, captcha_image
4、CNN网络架构
根据学习的相关资料,利用Pytorch简单地定义了一个简易型的卷积神经网络,该卷积神经网络主要包括有三个卷积层,两个全连接层。具体代码定义如下:
import torch.nn as nn
import captcha_setting #验证码相关参数定义集
# 定义了一个卷积神经网络(CNN)的模型,包括三个卷积层(layer1,layer2,layer3)和两个全连接层(fc,rfc)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential( #定义第一层的卷积层
nn.Conv2d(1, 32, kernel_size=3, padding=1), #2D卷积层,输入通道数为1,输出通道数为32,卷积核大小为3,使用padding为1
nn.BatchNorm2d(32), #2D批量归一化层,用于规范化每个batch的数据
nn.Dropout(0.5), #Dropout层,随机将50%的神经元设为0,以防止过拟合
nn.ReLU(), #ReLU激活函数层
nn.MaxPool2d(2)) #2D最大池化层,使用2x2的池化窗口
self.layer2 = nn.Sequential( #以下两个卷积层的定义类似
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer3 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Sequential(
nn.Linear((captcha_setting.IMAGE_WIDTH//8)*(captcha_setting.IMAGE_HEIGHT//8)*64, 1024),
# 定义了第一个全连接层fc,输入节点数为括号内容(验证码图片的大小),输出节点数为1024。
nn.Dropout(0.5),
nn.ReLU())
self.rfc = nn.Sequential(
nn.Linear(1024, captcha_setting.MAX_CAPTCHA*captcha_setting.ALL_CHAR_SET_LEN),
# 定义了第二个全连接层rfc,输入节点数为括号1024,输出节点数为括号内容(生成验证码总数的可能数量)
)
5、模型训练
模型的训练需要了解两个重要的过程,epoch和batch,它们两是深度学习中常用的训练参数,epoch和batch共同控制着训练过程的粒度和组织方式。其中,epoch定义了整个训练数据集通过模型的次数,而batch则定义了一次训练过程中处理的样本数量。,它们在训练过程中的作用如下:
- epoch指的是一个完整的训练过程,即使用整个训练集进行训练一次。当一个完整的数据集通过了神经网络一次并且返回了一次,即进行了一次正向传播和反向传播,这个过程称为一个epoch。
- batch是指一次训练模型所使用的样本数量。在训练过程中,通常将大量的训练样本划分为多个批次进行处理。每个批次中的样本被一起输入到模型中,通过前向传播和反向传播计算损失并更新模型参数。每个阶段包含多个批次的训练过程。在每个批次中,模型接收一批训练样本进行前向传播和反向传播,并更新参数。
import torch
import torch.nn as nn
from torch.autograd import Variable
import my_dataset # 处理输入模型的数据
from captcha_cnn_model import CNN # 载入定义好的cnn模型
# 训练参数
num_epochs = 30
batch_size = 100
learning_rate = 0.001
def main():
cnn = CNN() #初始化CNN模型
cnn.train()
print('init net')
criterion = nn.MultiLabelSoftMarginLoss() #定义损失函数
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate) #定义优化器,选择Adam作为优化方法
train_dataloader = my_dataset.get_train_data_loader() # 加载训练数据
for epoch in range(num_epochs): #根据上述的训练参数来训练多少次epoch
for i, (images, labels) in enumerate(train_dataloader):# 根据生成的每一轮数据量来决定训练次数
images = Variable(images)
labels = Variable(labels.float())
predict_labels = cnn(images)
loss = criterion(predict_labels, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 10 == 0:
print("epoch:", epoch, "step:", i, "loss:", loss.item())
if (i+1) % 100 == 0:
torch.save(cnn.state_dict(), "./model.pkl") #将100次训练结果保存到model.pkl中
print("save model")
print("epoch:", epoch, "step:", i, "loss:", loss.item())
torch.save(cnn.state_dict(), "./model.pkl") #训练完的数据保存到model.pkl中
print("save last model")
5、训练测试
训练的思路是让训练好的模型辨认测试集中的验证码图片,将测试的验证码抽离出来,与其标签进行比较,如果一致则将正确累加器进行累加,最后统计全部的数据得到最终的正确率。
import numpy as np
import torch
from torch.autograd import Variable
import captcha_setting
import my_dataset
from captcha_cnn_model import CNN
import one_hot_encoding
def main():
cnn = CNN()
cnn.eval()
cnn.load_state_dict(torch.load('model.pkl'))
print("load cnn net.")
test_dataloader = my_dataset.get_test_data_loader() # 加载测试数据集
correct = 0 # 正确个数
total = 0 # 验证总数
for i, (images, labels) in enumerate(test_dataloader):
image = images
vimage = Variable(image)
predict_label = cnn(vimage)
# 抽离验证码中的四个数据
c0 = captcha_setting.ALL_CHAR_SET[np.argmax(predict_label[0, 0:captcha_setting.ALL_CHAR_SET_LEN].data.numpy())]
c1 = captcha_setting.ALL_CHAR_SET[np.argmax(predict_label[0, captcha_setting.ALL_CHAR_SET_LEN:2 * captcha_setting.ALL_CHAR_SET_LEN].data.numpy())]
c2 = captcha_setting.ALL_CHAR_SET[np.argmax(predict_label[0, 2 * captcha_setting.ALL_CHAR_SET_LEN:3 * captcha_setting.ALL_CHAR_SET_LEN].data.numpy())]
c3 = captcha_setting.ALL_CHAR_SET[np.argmax(predict_label[0, 3 * captcha_setting.ALL_CHAR_SET_LEN:4 * captcha_setting.ALL_CHAR_SET_LEN].data.numpy())]
predict_label = '%s%s%s%s' % (c0, c1, c2, c3)
true_label = one_hot_encoding.decode(labels.numpy()[0])
total += labels.size(0)
if(predict_label == true_label):
correct += 1
if(total%200==0):
print('Test Accuracy of the model on the %d test images: %f %%' % (total, 100 * correct / total))
print('Test Accuracy of the model on the %d test images: %f %%' % (total, 100 * correct / total))
6、测试结果
6.1、1K验证码图像数据
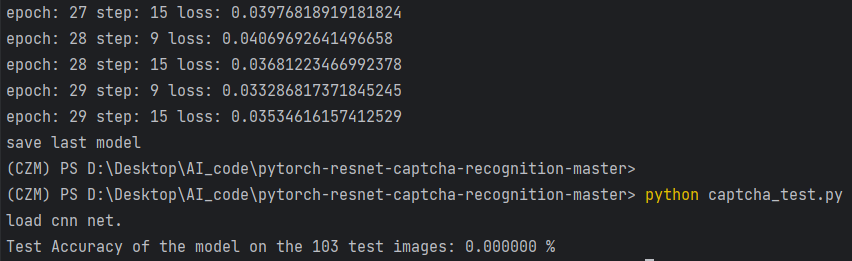
通过对生成1K个验证码图像数据训练得出的模型数据进行测试,其中测试集的数据为103个验证码数据,如下图所示,经过测试得到最终的准确率为0%,准确率比较低。
6.2、1W验证码图像数据
通过对生成1W个验证码图像数据训练得出的模型数据进行测试,其中测试集的数据为103个验证码数据,如下图所示,经过测试得到最终的准确率为3.88%,准确率依然比较低。

6.3、10W验证码图像数据
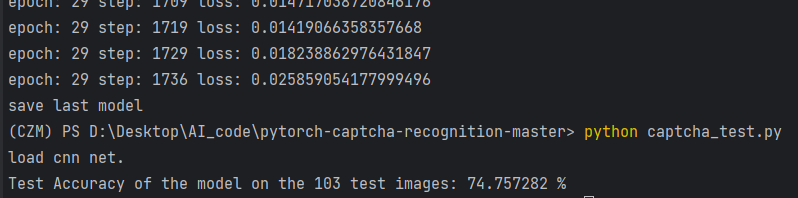
通过对生成1W个验证码图像数据训练得出的模型数据进行测试,其中测试集的数据为103个验证码数据,如下图所示,经过测试得到最终的准确率为74.76%,准确率较高。
7、结果反思与后续改进思路
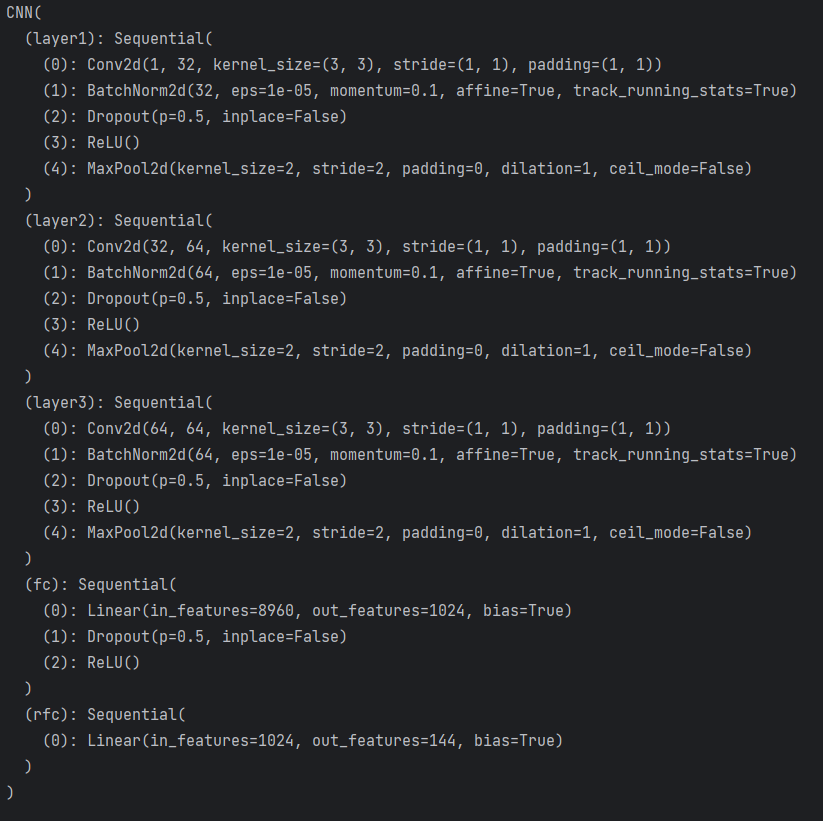
经过不同样本的训练得到的不同性能模型,经过测试得到的结论就是,在模型确定的情况下,整个CNN结构如下图所示,随着数据的数量级增加,整个模型的辨认验证码的性能在不断地提高。但是因为利用CPU训练模型的速度很慢,导致得到数据结果很慢,最后改成用GPU来对模型进行训练,速度快了很多,后续的训练将会继续使用GPU进行训练,能够更快的地得到结果。
后续想通过改变神经网络模型的层数来验证其神经网络深度对模型性能的影响,除此之外还想通过引入先前学习的ResNet、DenseNet相关框架进行验证其在改应用上的提升。
总结
这些天不断地在动手实现CNN的模型,让CNN实现验证码的辨认,因为本科的时候没有学习到相关的知识,于是便卡在了此处,这次在学习到CNN之后,便重新产生这个想法。通过不断地寻找相关知识,查询相关函数的原理,对整个代码的实现有了更好的理解,相信未来能利用机器学习实现更多有趣的想法。当然后续要使用GPU来实现训练,使用CPU训练真的花了很多时间,在这长记性了。















 6092
6092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









