







目录
时隔三个月,忙活了很久的中文点选验证码的识别,终于尘埃落定了,浅浅记录一下吧。前期为了偷懒,试过模板匹配、特征匹配、ocr文字识别(使用的是ddddocr)等方法,最终都以失败告终。无奈之下,还是使用了孪生神经网络,当然,不得不感慨孪生神经网络的强大,最终也是实现了95%以上的准确率。。。但有一种杀鸡焉用宰牛刀的感觉hhhh。anyway,终于得空整理这些东西了,整理出来发出来给大家参考一下。。。
先来看看验证码是啥样的吧,参考下图
想要训练模型,需要的数据当然不是一张图就能行的啦,所以,通过爬虫准备大量数据,爬虫到的图片格式是这样滴: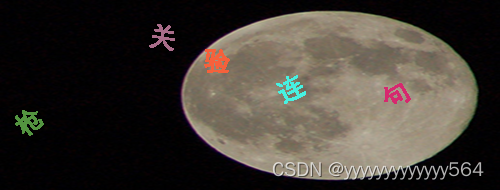

是的,一张验证码是由一张大图和一张小图共两张图片组成的。想在大图中找到小图中的四个字,当然应该想一些办法啦,比如把小图中的字截下来与大图中的进行比对,笔者试过诸如图像匹配、ddddocr文字识别等方法(希望工作量小一点),最终都以失败告终。最后还是妥协给了孪生神经网络。
第一步,需要将大图中的5个汉字截取下来,目标检测是一个很好的办法,也作为笔者对最新的YOLO模型的初次尝试吧。
解法流程
先把解决这个问题的流程放在文章开头吧,之后需要那一部分在目录跳转就可以。
YOLOv8
YOLOv8是Ultralytics公司最新推出的YOLO系列目标检测算法,可以用于图像分类、物体检测和实例分割等任务。根据官方描述,Yolov8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。
此外,Yolov8还有一个特点就是可扩展性,ultralytics将开源库命名为:“ultralytics”,而不是YOLOv8,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
- 融合众多当前 SOTA 技术于一体
- 未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
虚拟环境
新建虚拟环境
conda create -n your_env_name python=x.x
注意,YOLOv8要求:Python>=3.7,PyTorch>=1.7.
查看虚拟环境是否新建成功,有哪些虚拟环境,可以通过以下命令:
conda env list
conda info -e
激活虚拟环境
conda activate your_env_name
查看虚拟环境中有哪些包,可以使用下面的命令
pip list
conda list
删除虚拟环境
conda remove -n your_env_name --all
安装
pip安装(本人使用,非常简单)
pip install ultralytics
一般情况下,直接输入上面的命令特别特别慢,可以添加镜像(附一个镜像汇总链接:https://zhuanlan.zhihu.com/p/298372291),比如使用清华镜像:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
剩下的就不用管了,只需要等待安装完成即可。
源码安装
源码安装可以看这篇blog:https://blog.csdn.net/weixin_45662399/article/details/134499605
训练
下载预训练权重(建议事先下载好,模型自己下载太慢了)
预训练权重在下面地址中可以下载:
https://gitcode.com/ultralytics/ultralytics/overviewutm_source=csdn_github_accelerator&isLogin=1
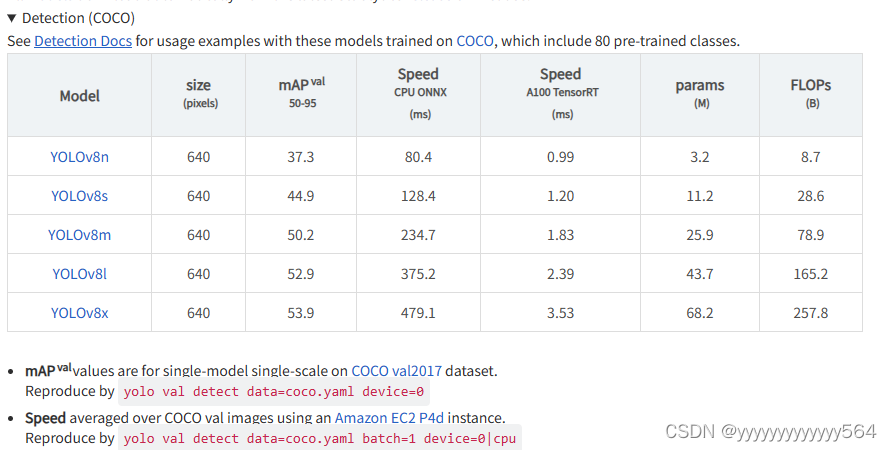
官方给出5个预训练权重,从小到大分别为YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x,当然啦,模型大了,对应的速度也就慢一点了,所以选择合适的模型是很重要的。本人使用的是YOLOv8n和YOLOv8s。
数据标注
在这个例子中,将大图中的字看成一类,只需要识别出大图中的5个汉字就好了。
说实话,数据有点多,为了偷懒,用百度easydl标注的数据。
具体用法:
第一步,先在数据总览中创建数据集

第二步:先自己手动标注,保证每一个标签都有不少于10个时,在数据标注中选择智能标注,剩下只需要大致检查一下标注就行了。
第三步,在数据总览的数据集后面选择多人标注,就会进入到下面这个页面,点击导出,就能导出标注信息了。
不足的是,导出的数据格式并不是YOLO格式的,因此需要转为YOLO格式,我导出的是voc格式,voc转YOLO格式可参照这篇blog:
https://blog.csdn.net/qq_43161211/article/details/122959052
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"] ### 注意与自己的类对应,对应,对应,不然转好的txt文件是空的
#classes=["ball"]
TRAIN_RATIO = 80 ### 按自己的要求划分,这里代表是train:test=8:2
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
修改.yaml配置文件
.yaml配置文件包括训练集、验证集、测试集的路径,nc表示类别数量,names为类别名称。创建data文件夹,创建一个data.yaml文件:
train: C:/Users/admin/Desktop/images/train #训练集路径
val: C:/Users/admin/Desktop/images/val #验证集路径
test: C:/Users/admin/Desktop/images/test #测试集路径
# number of classes
nc: 1
# class names
names: ['1']
训练代码
YOLOv8支持命令行命令,也支持python代码。
命令行
yolo train data=data.yaml ( 你的配置文件(xx.yaml)) model=yolov8n.pt epochs=300 imgsz=640 batch=8 workers=0 device=0
python代码
from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n.pt')
# 训练模型
results = model.train(data='data.yaml', epochs=300, imgsz=640)
训练结果
训练结果保存在runs/detect/train文件夹,文件夹内容如下: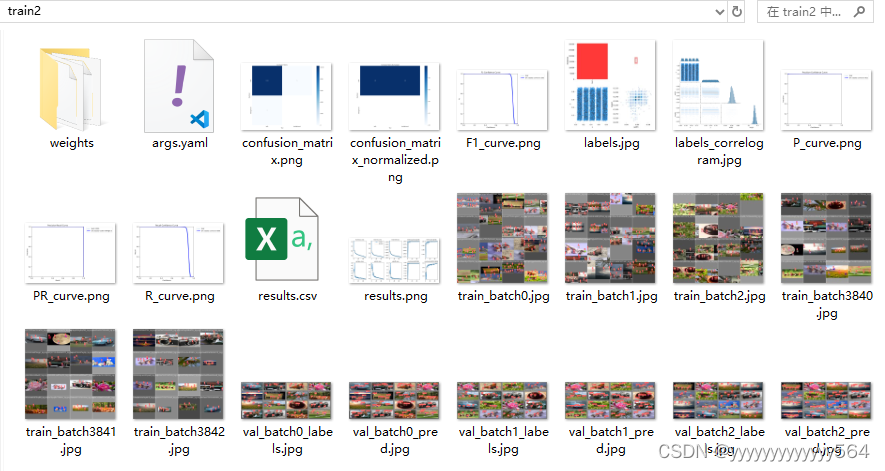
weights文件夹
在weights文件夹中包含best.pt和last.pt,best.pt是损失值最小的模型文件,last.pt是最后一次训练的权重。
训练结果分析可参照https://blog.csdn.net/weixin_45277161/article/details/131046636.
预测
通过训练,得到了YOLOv8模型,记下来就是根据图片进行预测啦。同样地,预测也可通过命令行方式和python代码实现。
命令行
yolo predict model=runs/detect/train/weights/best.pt source=C:/Users/admin/Desktop/image1.png
pyhton代码
from ultralytics import YOLO
# 加载模型
model = YOLO('best.pt')
# 模型预测,save=True 的时候表示直接保存yolov8的预测结果
metrics = model.predict('image1.jpg', save=True)
孪生神经网络(Siamese network)
呼,终于码完YOLOv8了,接下来就该码孪生神经网络了。本文使用的孪生神经网络代码来自于https://github.com/bubbliiiing/siamese-pytorch/tree/bilibili。
孪生神经网络的背景我就不介绍了,毕竟在使用的时候并不考虑背景。我们直接来看应用场景。
应用场景
Siamese network就是“连体的神经网络”,两个神经网络共享权值,用于处理两个输入"比较类似"的情况。比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合。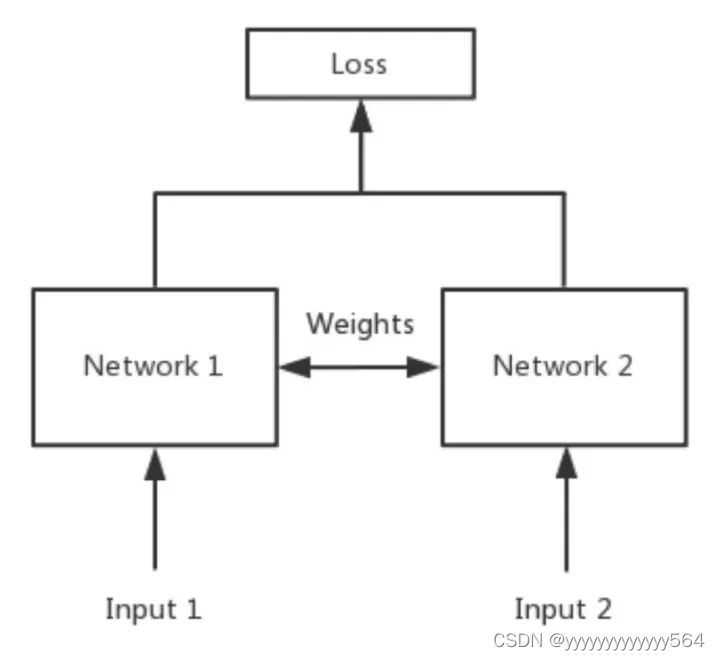
当两个神经网络的权值不共享时,称为伪孪生神经网络。在伪孪生神经网络中,两个神经网络可以是不同的神经网络。(比如一个是lstm一个是cnn)伪孪生神经网络适用于处理两个输入"有一定差别"的情况。如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用伪孪生神经网络。
准备数据集
训练之前,还是要标注数据的。说到标注数据,这可是个麻烦事了。对于大图中的汉字,采取先裁剪后标注的两步骤方法。在标注之前,先将大图上汉字的图片用YOLOv8切割。
from ultralytics import YOLO
import cv2
import hashlib
import numpy as np
import os
#切割大图
model = YOLO('best.pt') #加载yolo模型
def cai_save(img_big):
results = model.predict(img_big)
img_big_cai = [] #裁剪图片并保存在列表中
for i in results[0].boxes.xyxy:
i = list(map(int, i))
img_c = img_big[i[1]:i[3],i[0]:i[2]]
img_big_cai.append(img_c)
for img_array in img_big_cai:
fd = img_array * np.random.randint(10)
fmd5 = hashlib.md5(fd).hexdigest() + '.jpg'
cv2.imwrite(os.path.join('./cai_big_images', fmd5), img_array)
dir_path = './big_images'
files = os.listdir(dir_path_train)
for file in files:
img = cv2.imread(dir_path+file)
cai_save(img)
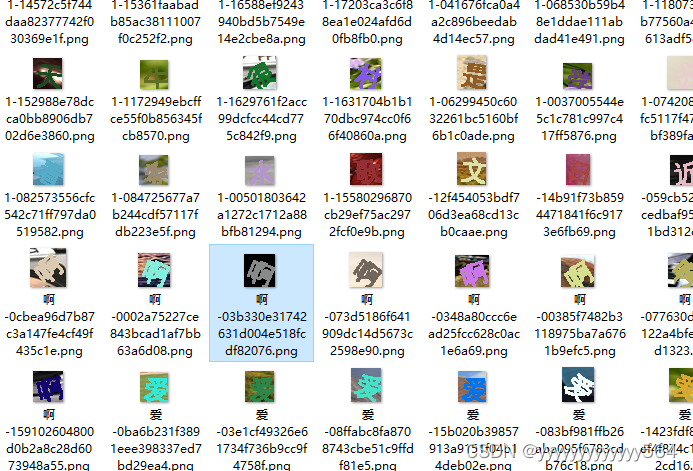
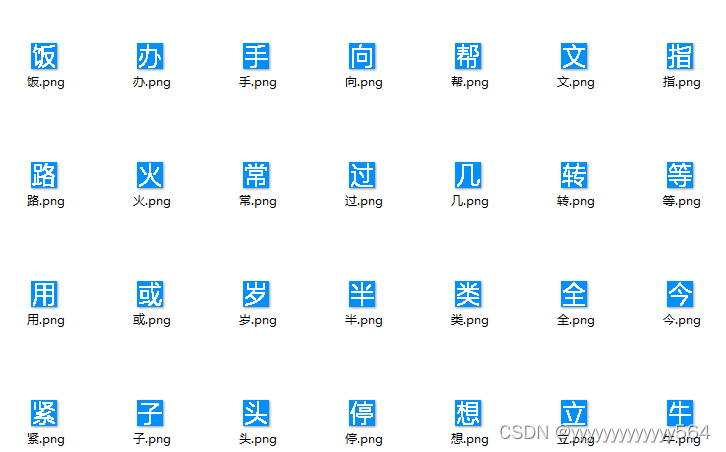
由于小图中需要验证的汉字坐标是固定的,因此直接裁剪+标注一步完成。接着借助https://blog.csdn.net/aaronjny/article/details/109732693中的标注脚本,来标注数据。因为小图中汉字的字体是一样的,因此将它们单独放到了一个文件夹correct_words,将标注的大图中的汉字放到了文件夹gen_words(emmmm,裁剪出来几万张图片实在标注不完,只标注了一部分)。
import os
from glob import glob
import cv2
from tqdm import tqdm
def extract_correct_word():
save_dir = './correct_words/'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
images = glob('img_small/*.png')
cai = [[166, 12, 192, 38], [199, 12, 225, 38], [232, 12, 258, 38], [265, 12, 291, 38]]
for image_path in tqdm(images):
image_small = cv2.imread(image_path)
for coord in cai:
im = image_small[coord[1]:coord[3], coord[0]:coord[2]]
cv2.imshow('text', im)
cv2.waitKey(100)
word = input('请输入当前选中汉字:')
name = word+'.png'
# cv2.imencode(保存格式, 保存图片)[1].tofile(保存路径)
re = cv2.imencode('.png', im)[1].tofile(os.path.join(save_dir, name))
del im
cv2.destroyAllWindows()
os.remove(image_path) #每标注一张图,从原来文件夹img_small中删除这张图,将标注图片和信息保存到新的文件夹correct_words中
def extract_gen_word():
save_dir = './gen_words/'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
images = glob('cai_big_images/*.png')
for image_path in tqdm(images):
num = image_path.split('/')[-1].split('.')[0]
im = cv2.imread(image_path)
cv2.imshow('text', im)
cv2.waitKey(100)
word = input('请输入当前选中汉字:')
name = word+'-'+num+'.png'
# cv2.imencode(保存格式, 保存图片)[1].tofile(保存路径)
re = cv2.imencode('.png', im)[1].tofile(os.path.join(save_dir, name))
del im
cv2.destroyAllWindows()
os.remove(image_path)
if __name__ == '__main__':
#extract_correct_word()
extract_gen_word()
对于大图中的汉字,标注命名方式为:字-hash值.png,不认识或者不好辨认的字全部标注为1-hash值;小图中的汉字直接命名为 汉字.png。
训练孪生神经网络
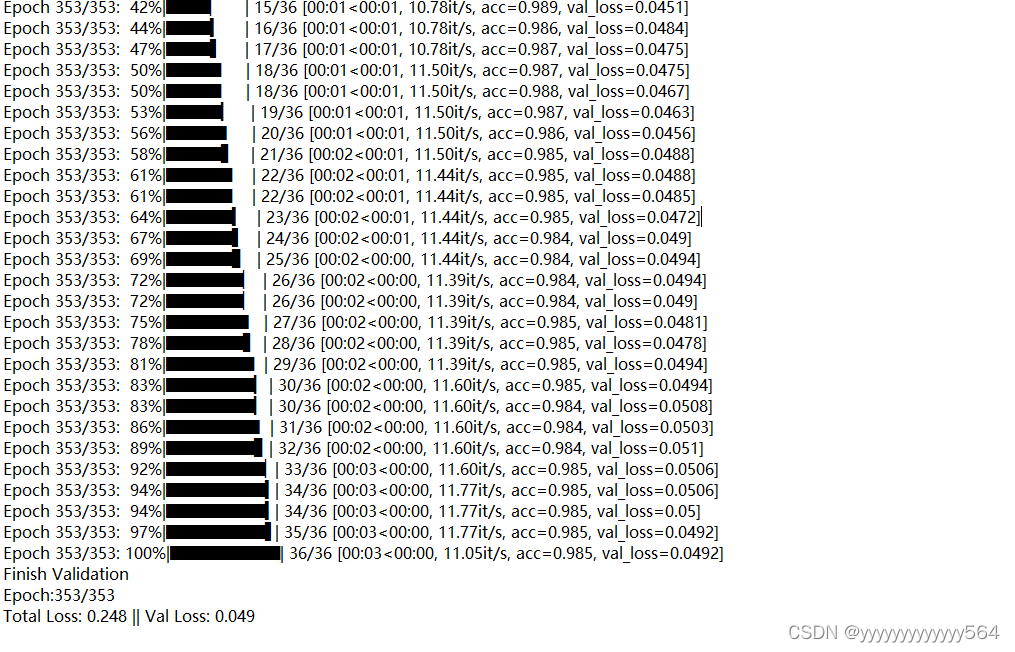
孪生神经网络的输入是一个正样本一个负样本,在本次训练中,正样本和负样本分别取自gen_words和correct_words两个文件夹,因此本次训练的数据集格式与https://blog.csdn.net/weixin_44791964/article/details/107343394不同,所以将bubbliiiing中的代码中关于数据集的部分小小修改了一下。训练过程如下。
预测
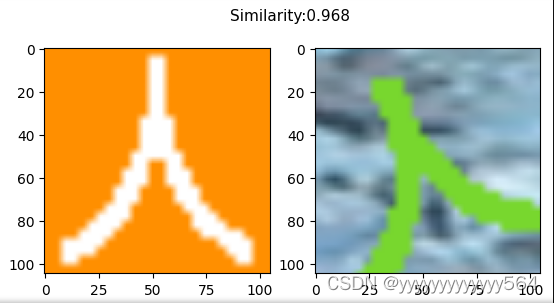
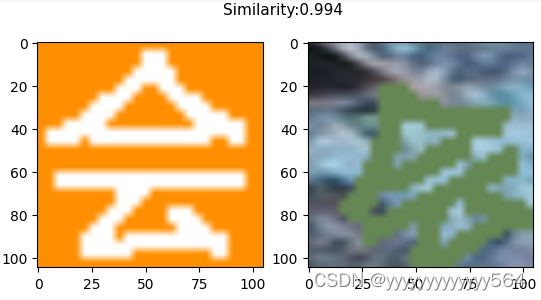
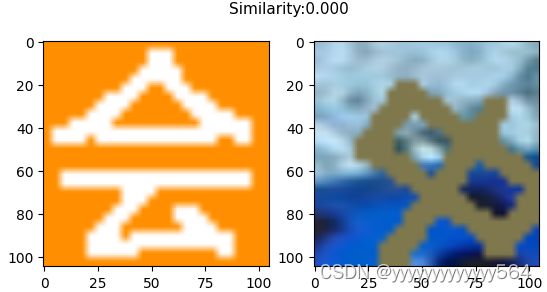
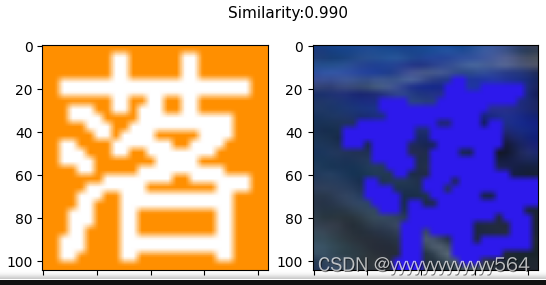
返回坐标

YOLOv8训练参数说明
最后再补一个训练参数说明吧
| 参数 | 默认值 | 说明 |
|---|---|---|
| model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | None | 数据集配置文件的路径(例如 coco128.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
| epochs | 100 | 训练周期数。每个周期代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
| time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
| patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的周期数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
| batch | 16 | 训练的批量大小,表示在更新模型内部参数之前要处理多少张图像。自动批处理 (batch=-1)会根据 GPU 内存可用性动态调整批处理大小。 |
| imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
| save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
| cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
| device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
| workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
| project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
| exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
| pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
| optimizer | ‘auto’ | 为培训选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
| verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
| seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
| deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
| single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
| rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
| cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
| close_mosaic | 10 | 在训练完成前禁用最后 N 个历元的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
| resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
| amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
| fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
| profile | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
| freeze | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
| lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
| lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
| momentum | 0.937 | 用于 SGD 的动量因子,或用于 Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
| weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚,以防止过度拟合。 |
| warmup_epochs | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
| warmup_momentum | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
| warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
| box | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
| cls | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
| dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
| pose | 12.0 | 姿态损失在姿态估计模型中的权重,影响准确预测姿态关键点的重点。 |
| kobj | 2.0 | 姿态估计模型中关键点对象性损失的权重,在检测可信度和姿态精度之间取得平衡。 |
| label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签和标签均匀分布的混合标签,可以提高泛化效果。 |
| nbs | 64 | 用于损耗正常化的标称批量大小。 |
| overlap_mask | True | 决定在训练过程中分割掩码是否应该重叠,适用于实例分割任务。 |
| mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
| dropout | 0.0 | 分类任务中正则化的放弃率,通过在训练过程中随机省略单元来防止过拟合。 |
| val | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
| plots | False | 生成并保存训练和验证指标图以及预测示例图,以便直观地了解模型性能和学习进度。 |














 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









