







卷积神经网络 :初识篇
首先
感谢大创项目组员分配工作逼迫自己在一上午了解了图像识别中的卷积神经网络。(没有紧迫感可能给一个月都懒得研究……)
大致过程
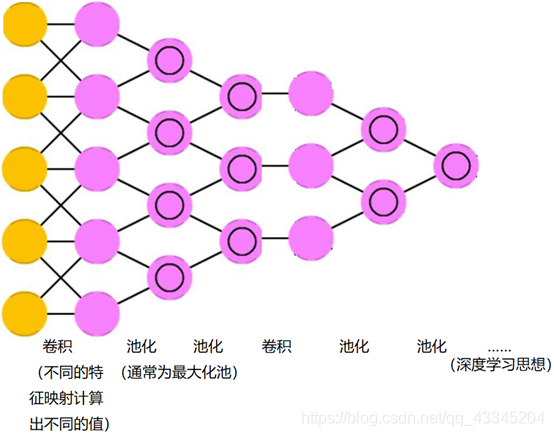
读入(Input)
将图片读取成为长乘宽个像素点,将他们放入二维数组(放入数组的数据可以为rgb值等等),放入二维数组的数据可以用来进行后续的分区块卷积。
卷积(Convolution)
卷积的目的
通过不同的特征映射(或叫卷积核)来凸显图片的不同特征。
一些常见的卷积核的例子
通过identity(即理解为对整体的特征) 来凸显本体特征。
来凸显本体特征。
通过Edge detection(即理解为对边缘的特征) 
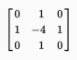

都可以将图片的边缘的特征凸显。
通过Sharpen(即理解为对凸出部分的特征) 来将图片的
来将图片的
还有Box blur(盒装模糊) 、Gaussian blur(高斯模糊)
、Gaussian blur(高斯模糊) 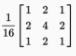
等不同的计算卷积的方法。
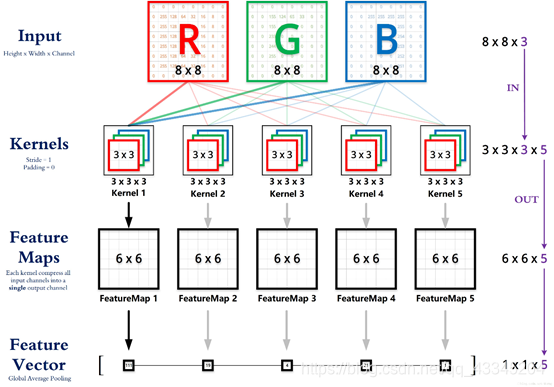
卷积核在拍图识花的实例中对rgb值进行分析的过程:
卷积和在拍图识花中的应用主要体现在颜色和形态的识别。因此,要加上每个像素的的rgb三原色的卷积和算法(即每个图片中的每一个像素点都有对应的rgb值,分别对每一种值进行卷积和,分别于原图的匹配,来计算每种颜色值即r值、g值、b值分别与各种花的颜色匹配的概率)。再结合(1)种对形态的匹配识别,可以更加准确、具体。
对r、g、b三颜色值的卷积计算可以用下图表示:
池化(Pooling)
池化的理解
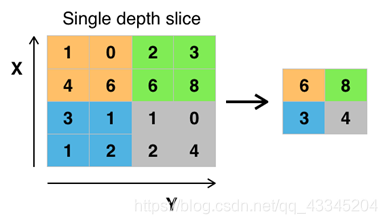
池化层可以理解为过滤过程,按照某一标准(一般为最大化池、或者最小化池)来进行筛选,去这几个像素值中的最大值(或者最小值或者平均值)来代替,例如下图:(最大池化)
(若利用最小池化,只需将改取每四个像素点的最小值)
池化的图解
卷积神经网络的优点:
通过不停的循环的计算卷积、来便于后边的池化分离的过程。再不断重复卷积、池化、卷积、池化……运用深度学习的思想,减小了数据量。
结合大创项目进行决策树分析
图片理解
(此处的决策树只是自己一点粗浅的认知)
(图片画的草率。)

决策属性的选择
(也就是拿什么做为选择依据)
①属性选择:不能随机选取,要选择不同花卉区分度大的属性来作为区分标准
②信息增益:利用比对每一个属性的熵测度,(熵测度可通过下边的公式计算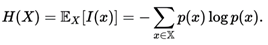
)
来计算其信息增益,从而根据不同特性(也即属性)来计算各种属性所占的比例=>(例如根据算出的信息增益的比较可能决策出颜色对花卉种类的决策的比重为x,花瓣为y、……,最后计算总值时按照不同属性的比例去算加权和。)
决策原理
通过对将目标花卉的不同属性进行分开处理(恰好卷积核可以得到对不同特征的描述),来从不同方面综合考虑目标花卉究竟与数据库中的哪种花卉匹配,得到最佳的拟合。
第一次补充 2019/6/14 卷积池化补充理解:
主要还是在卷机层的细节的理解。
1、原来没有填充边缘的概念,因为没有考虑过每一个卷积核对于每个色素点的遍历次数不同会带来的影响。
2、原来没有考虑过单次卷积的时间的控制,只是通过卷积池化循环重复次数最后跳出这个过程来控制时间。
边缘填充
1、为什么要填充:对于卷积核比较小的时候,3*3或更小的时候,卷积核遍历一遍对于最左上角的只被遍历一遍,而往下数两个,往右边数两个,即(2,2)的点[左上角为(0,0)]时,此时这个点的遍历次数为9次,差了八次,使最边上的未被完全遍历。这样可能会导致非常大的误差。
2、怎么填充:根据卷积核的边长,将矩阵四边延伸,每个边延伸(卷积核边长-1)的个数的格子,格子可以付赋给0值。
步长
1、步长的作用主要是控制卷积核跳跃的距离,通过跳跃减少单次遍历的时间。
2、步长取值的影响:步长越长,跳跃的越多,相应的精准度越低,但是遍历的时间越短。
MNIST数据集的使用
用于训练模型,通过卷积池化函数对














 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









