







目录
1.为什么会有这篇文章?
起因是指导老师在程序设计周给了一个很有意思的题目:简单深度神经网络的手工实现。要求我们学习给定的一篇博客文章来了解神经网络的基本工作原理,并使用C++语言实现示例中的所有功能。作为大一的软工学生,我们在没有任何机器学习领域知识的储备下,我们该如何理解和实现一个简单的深度神经网络呢?由于我认为原博客不足以让我们看懂并理解深度神经网络,于是将几天来对这个题目的所学所得记录下来,加以自己的理解,完成了这篇文章。文章的目的是提供一个清晰、生动而易懂的教程,帮助同学们理解神经网络的基本原理,并通过具体的代码示例来展示实现的过程。这里给出原博客链接:
(4条消息) java实现的深度神经网络_wtq1993的博客-CSDN博客 https://blog.csdn.net/wtq1993/article/details/50705677 本文部分内容引用该文章,感谢博主@wtq1933!
https://blog.csdn.net/wtq1993/article/details/50705677 本文部分内容引用该文章,感谢博主@wtq1933!
2.什么是深度神经网络?
2.1神经元与大脑
想要理解深度神经网络,那么我们需要先理解深度神经网络这个名字是怎么来的。故名思义,我们可以猜想到深度神经网络是一种特定结构的神经网络,通过神经元进行信息传递和处理。于是可以自然引出大脑的例子,我们看下面这张图:
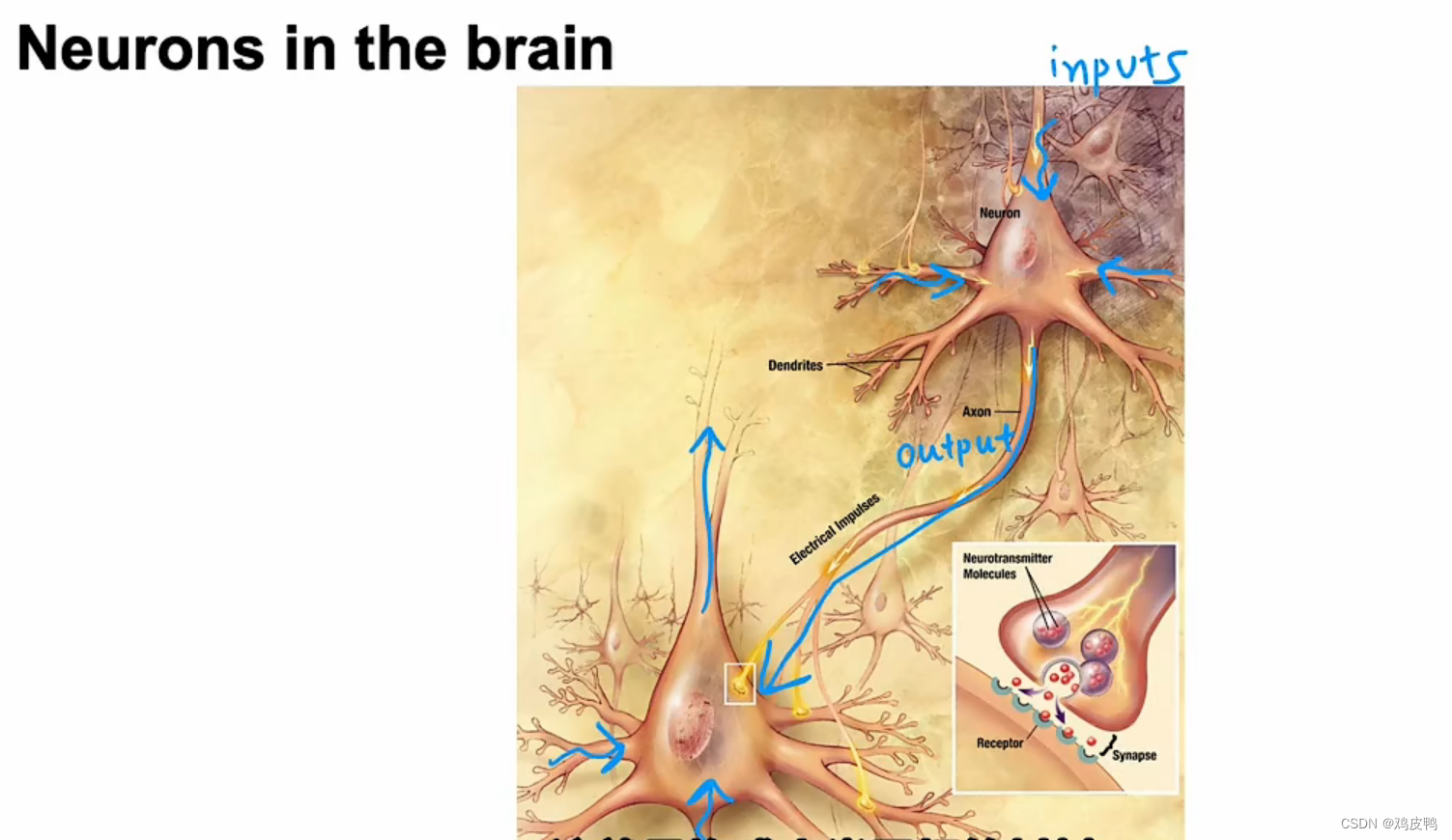
这是一张图表,说明了大脑中的神经元是怎么样工作的。人类所有的思想都来自于我们大脑中的神经元,它们发送电脉冲,有时会连接到其他的神经元。如图上方的神经元,它有许多来自其它神经元的输入,执行一些计算后,通过电脉冲发送给其他神经元,成为图下方神经元的输入。图下方的神经元接受上方神经元以及其他一些神经元的输入后,经过聚合计算再发送给其他的神经元,这就是构成人类思想的基本材料——神经元。
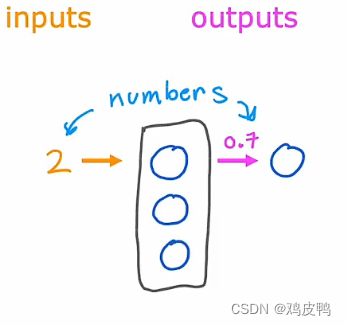
我们把这个过程抽象成一个简单的数学模型。如图所示,我们把蓝色小圆作为一个单独的神经元,2为输入这一层三个神经元的值,经过计算之后,0.7作为输出的一个值并传递给下一个神经元,这就是一个简单的神经网络的数学模型。
2.2神经网络是如何工作的
为了说明神经网络是如何工作的,让我们从一个例子开始:

这是一个将深度神经网络应用于计算机视觉应用程序的例子。如果你想要构建一个人脸识别应用程序,你可能需要训练一个神经网络,将上面的图片作为输入并准确的输出图中人类的身份。上图是一张1000像素*1000像素的闻鸡起舞图,它在计算机中可以看作是以一个1000*1000的像素强度值矩阵表示的,每一点可以看做像素的亮度,如下图所示:
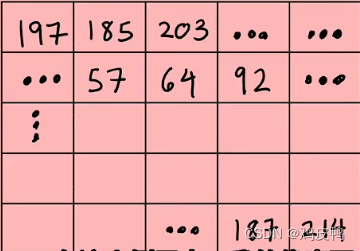
我们可以把这个矩阵展开成一个向量或者列表,作为程序的输入向量,最后会输出蔡徐坤这个人名,如图:
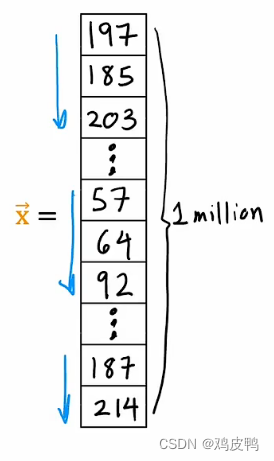
图1
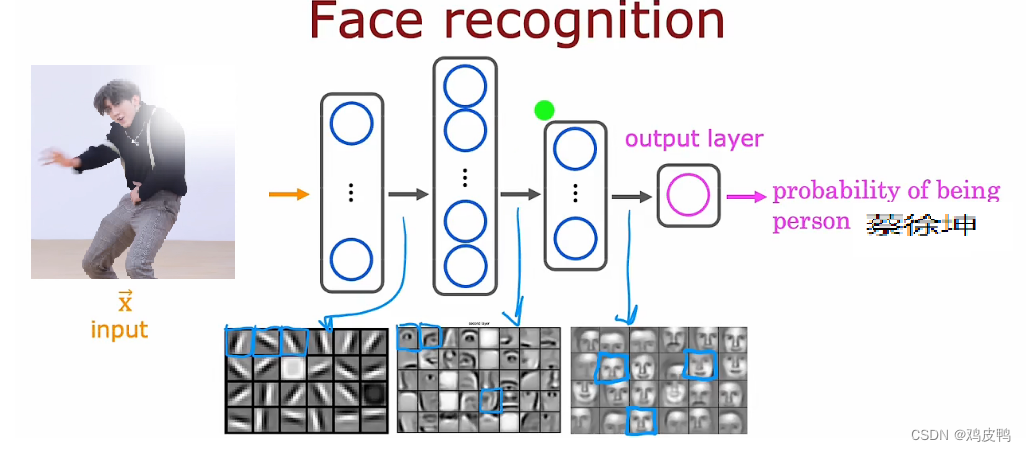
图2
那么深度神经网络的每一层都承担了什么样的工作呢?在这个例子中,我们可以看到:在最早一层神经网络中,输入层聚合了一些非常短的线条,隐藏层2则开始聚合脸部的一部分,如鼻子,下巴等,隐藏层3则聚合了人物的脸部,最后的输出层则用来匹配身份。这就是人脸识别中说明深度神经网络如何工作的简单例子。
好了,有了前面两个例子的铺垫,让我们回到最初的问题:什么是深度神经网络?这里我们给出对它的书面解释:
深度神经网络(Deep Neural Network,DNN)是一种人工神经网络模型,它由多个神经网络层组成,其中每个层都包含多个神经元(或称为节点)。这些层通过连接权重相互连接,并通过非线性激活函数将输入信号传递给下一层。
深度神经网络之所以称为"深度",是因为它通常由很多层组成,典型的深度网络可能包含几十层甚至上百层。每一层都对输入数据进行一系列的非线性变换和特征提取,以便逐渐学习到更加抽象和高级的表示。
深度神经网络的训练过程通常使用反向传播算法(Backpropagation)和梯度下降优化算法,通过调整网络中的连接权重,使网络能够逐渐调整自身以最小化损失函数。这样,在经过大量的训练样本和迭代优化之后,深度神经网络可以从输入数据中学习到复杂的特征和模式,并用于各种任务,如图像识别、语音识别、自然语言处理和推荐系统等。
里面有些名词你可能并不理解,不过没有关系,相信通过上面的介绍,你已经大概了解了神经网络的组成以及基本的工作方式,下文我们会逐步对这段定义中涉及的知识进行介绍。Let's dive in!
3.神经网络的计算过程
3.1隐藏层的计算过程以及向前传播
阅读了上面的内容之后,相信大家已经对神经网络有了初步的理解。在大多数现代神经网络的基本构建块是一层神经元,让我们先看看一层神经元是怎么工作的:
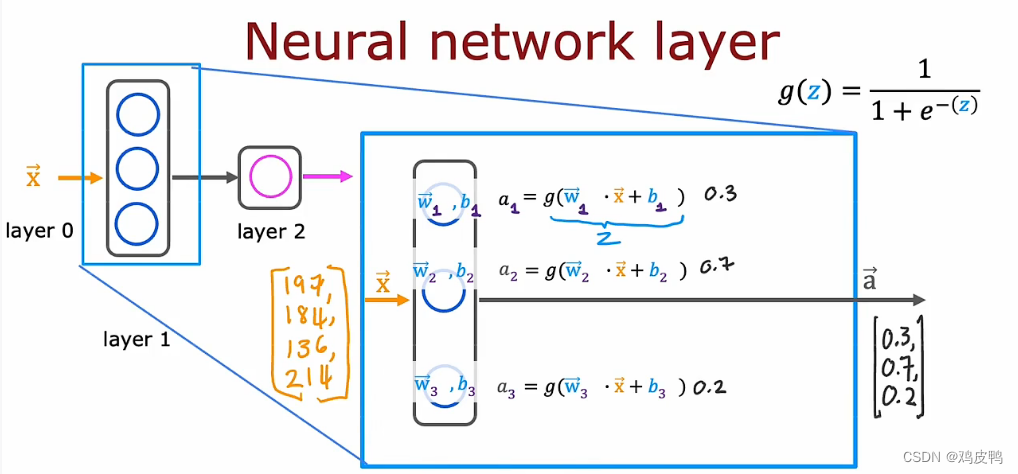
这是一个简单示例,有四个输入特征被设置到三个神经元的这一层,然后将其输出发送到带有一个神经元的输出层,我们放大了隐藏层来看看内部是怎么计算的:
x是一个一维向量,用来表示输入的四个数197,184,136,214。向量是一种数据结构,用于表示具有相同类型的一组值,在计算机中,向量通常表示为数组或列表。向量可以在一维、二维或更高维度空间中存在。一维向量可以看作是一个有序的数值序列,而多维向量则可以看作是一个矩阵的列或行。
w是每一个神经元的权重值weight,b为神经元的偏置值bias。这里对偏置值与权重进行简单介绍:偏置值(bias)是一个常数项,它被添加到线性变换的结果中,用于调整模型的输出。偏置值通常与权重(weights)一起使用,以改变模型的灵活性和表达能力。权重易于理解,这里不过多赘述。偏置值可以看作是神经元激活的阈值,在神经网络中,每个神经元都有一个偏置值。它决定了神经元在何时激活并产生输出。通过调整偏置值,我们可以控制神经元的活跃程度。数学上,偏置值可以理解为线性变换中的截距。例如,对于简单的线性回归模型 y = mx + b,其中 b 就是偏置值,它表示直线与 y 轴的截距。在神经网络的计算过程中,每个神经元接收输入信号,进行加权求和,并应用激活函数。偏置值被添加到加权求和的结果中,并通过激活函数进行非线性变换,从而产生神经元的输出。偏置值的作用是使模型具有更强的表达能力,因为它可以调整模型在输入空间中的位置和形状。通过学习训练数据中的权重和偏置值,神经网络可以适应不同的输入模式,从而提高模型的准确性和性能。
a标量是每一个神经元的输出值,a向量是储存所有标量的一个vector,也是往下一层的一个输出。这里演示了深度神经网络常用的激活函数sigmoid函数(图中函数g(z))计算a的例子。如果你不想当数学家的话,你就不需要知道这怎么来的,用好这个函数就行了。
以下是一个深度神经网络图示,其中的计算原理和上面介绍的单层神经网络一样:
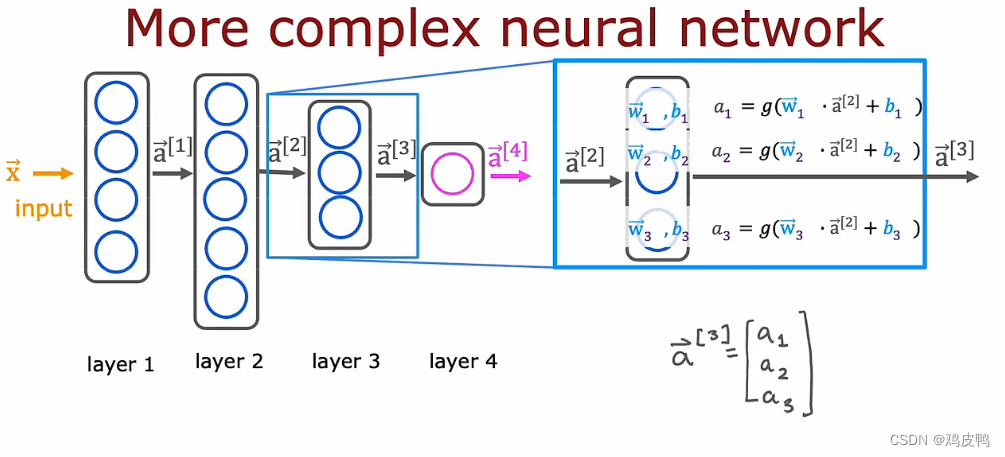
3.2一般的深度神经网络以及计算过程
一般的神经网络结构如下图所示,最左边的是输入层,最右边的是输出层,中间是多个隐含层,隐含层和输出层的每个神经节点,都是由上一层节点乘以其权重累加得到,标上“+1”的圆圈为截距项b,对输入层外每个节点:Y=w0*x0+w1*x1+…+wn*xn+b,由此我们可以知道神经网络相当于一个多层逻辑回归的结构。如图所示:
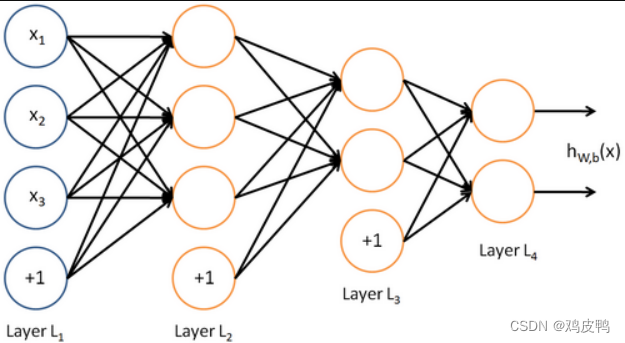
计算过程:输入层开始,从左往右计算,逐层往前直到输出层产生结果。如果结果值和目标值有差距,再从右往左算,逐层向后计算每个节点的误差,并且调整每个节点的所有权重,反向到达输入层后,又重新向前计算,重复迭代以上步骤,直到所有权重参数收敛到一个合理值。由于计算机程序求解方程参数和数学求法不一样,一般是先随机选取参数,然后不断调整参数减少误差直到逼近正确值,所以大部分的机器学习都是在不断迭代训练,我们从程序上详细看看该过程实现就清楚了。
这里补充 权重调整量的公式(不需要知道怎么来的,用就是了!):
权重调整量 Δw(k+1) = mobp*Δw(k)+rate*Err*value
这里的mobp是动量系数,rate是学习步长。err和value下面程序里你会知道什么意思。这里简单介绍一下mobp和rate,这两个你就理解成让整个网络更准确更高效,在训练前手动设置的参数就行了,对于下面的代码理解没有什么影响,下面的介绍不想看可以跳过:
在神经网络中,学习步长(Learning Rate)是指在梯度下降算法中更新模型参数时所使用的比例因子,为超参数。梯度下降是一种常用的优化算法,用于最小化神经网络的损失函数。学习步长决定了每次更新模型参数时的步幅大小。较大的学习步长意味着参数在每次更新时会更快地向损失函数的最小值方向移动,从而加快收敛速度。然而,如果学习步长过大,可能会导致在最小值周围震荡或错过最小值。相反,较小的学习步长会使参数更新的步幅更小,可能需要更多的迭代次数才能达到最小值,但通常能够更稳定地收敛。然而,如果学习步长过小,模型可能需要更长的时间才能收敛,或者可能陷入局部最小值而无法找到全局最小值。因此,在训练神经网络时,选择合适的学习步长非常重要。通常,学习步长是在训练过程中手动调整的超参数(就是人工输入,一般用别人训练好的),可以根据损失函数的变化情况和训练集的特点进行调整。
在神经网络中,动量系数(Momentum Coefficient)是一种用于优化算法的超参数,通常与梯度下降算法一起使用,以加快模型的收敛速度并增强模型参数更新的稳定性。梯度下降算法的基本思想是根据损失函数对模型参数的梯度方向进行更新,从而逐步最小化损失函数。然而,梯度下降算法可能会在损失函数的优化过程中遇到一些问题,如陷入局部最小值、收敛速度过慢或震荡等。为了克服这些问题,动量(Momentum)被引入优化算法中。动量基于物理学中的动量概念,通过积累先前梯度的指数移动平均值,使得参数更新更具有动量,有助于在平坦区域加速收敛,在峡谷区域减少震荡。动量系数控制了动量的影响程度,取值范围通常为[0, 1]之间。较大的动量系数表示更多的先前梯度被保留,从而在更新时更具有动量,加快收敛速度。然而,如果动量系数过大,可能导致参数更新过度,错过最小值。
4.C++的程序实现
我们找个简单例子来看看神经网络神奇的效果。为了方便观察数据分布,我们选用一个二维坐标的数据,下面共有4个数据,方块代表数据的类型为1,三角代表数据的类型为0,可以看到属于方块类型的数据有(1,2)和(2,1),属于三角类型的数据有(1,1),(2,2),现在问题是需要在平面上将4个数据分成1和0两类,并以此来预测新的数据的类型。
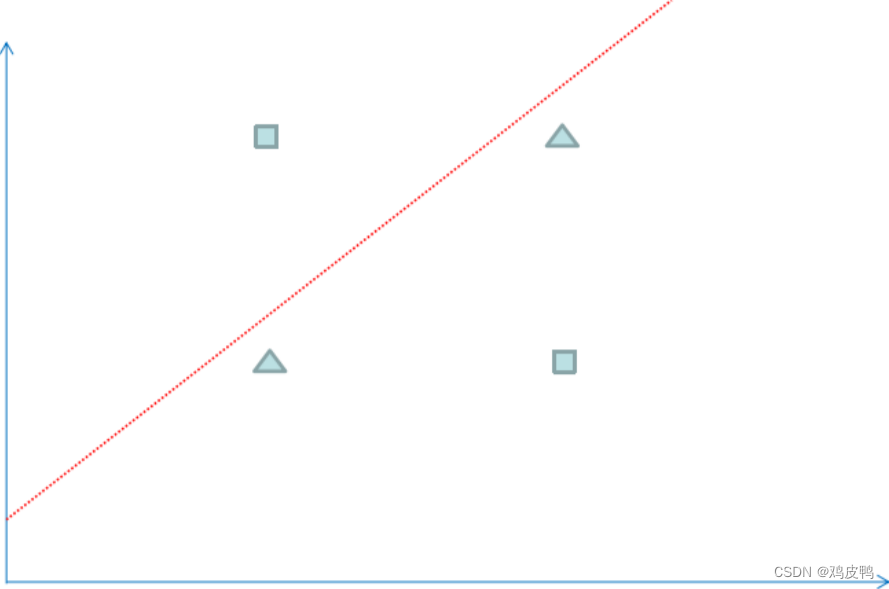
我们可以运用逻辑回归算法来解决上面的分类问题,但是逻辑回归得到一个线性的直线做为分界线,可以看到上面的红线无论怎么摆放,总是有一个样本被错误地划分到不同类型中,所以对于上面的数据,仅仅一条直线不能很正确地划分他们的分类,如果我们运用神经网络算法,可以得到下图的分类效果,相当于多条直线求并集来划分空间,这样准确性更高。
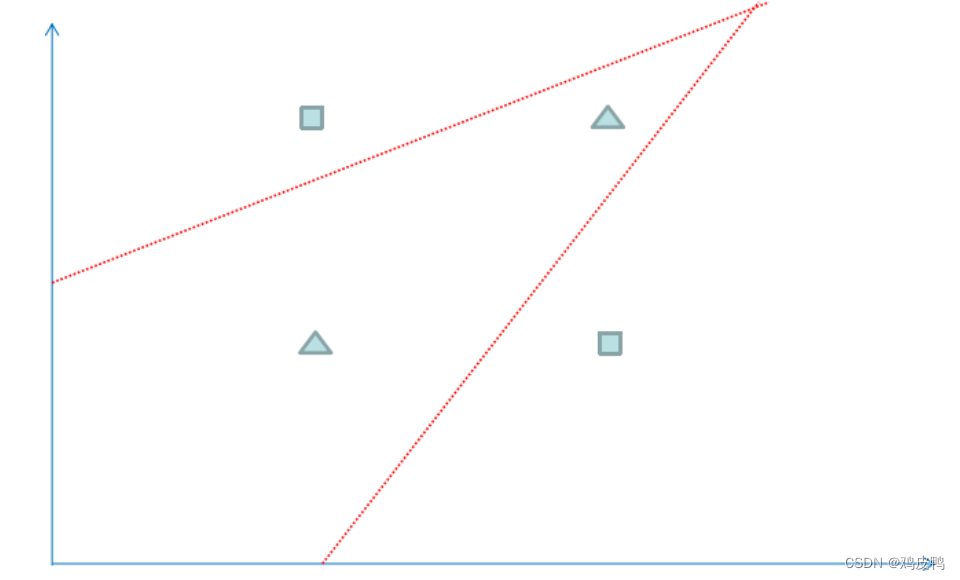
有了上面的知识,我们来一起尝试搭建一下这个网络吧!
以下是深度神经网络的一个C++程序实现,请先阅读代码理解初始化,向前传播,反向调整权重,迭代训练四个部分的具体实现,下一篇博客将会更新搭建代码的整体思路并作出详细解释:
代码原创,转载请注明原文地址及作者~
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <random>
#include <cmath>
#include <vector>
using namespace std;
class BpDeep
{
public:
vector<vector<double>> layerUnits_value;//神经网络各层节点值
vector<vector<double>> layerUnits_err;//神经网络各节点误差
vector<vector<vector<double>>>layerUnits_weight;//神经网络各节点权重
vector<vector<vector<double>>>layerUnits_delta;//神经网络各节点权重调整量
double mobp;//动量系数
double rate;//学习系数
//初始化一个深度神经网络
BpDeep(const vector<int>& numberOfUnits, double rate, double mobp) : rate(rate), mobp(mobp)
{
//numberOfUnits.size()为层数,通过resize来调整容器大小以保证能容纳层数为numberOfUnits的深度神经网络
layerUnits_value.resize(numberOfUnits.size());
layerUnits_err.resize(numberOfUnits.size());
layerUnits_weight.resize(numberOfUnits.size());
layerUnits_delta.resize(numberOfUnits.size());
//创建隐含层
int layerNum = numberOfUnits.size();//总层数
random_device rd;
mt19937 mt(rd());
uniform_real_distribution<double> dis(0.0, 1.0);//0.0-1.0之间随机分布的权重
for (int l = 0; l < layerNum; l++)
{
layerUnits_value[l].resize(numberOfUnits[l]);
layerUnits_err[l].resize(numberOfUnits[l]);
//输出层没有weight 与 delta
if (l + 1 < layerNum)
{
//前一个+1是由于引入了偏置项bias
layerUnits_weight[l].resize(numberOfUnits[l] + 1, vector<double>(numberOfUnits[l + 1]));
layerUnits_delta[l].resize(numberOfUnits[l]+ 1, vector<double>(numberOfUnits[l + 1]));
for (int j = 0; j < numberOfUnits[l] + 1; j++)
{
for (int i = 0; i < numberOfUnits[l + 1]; i++)
layerUnits_weight[l][j][i] = dis(mt);//随机初始化每个神经元权重
}
}
}
}
//向前传播过程,计算一个向量(储存权重的一维数组)
//in为输入的数据集,这里用一组double类型数表示
vector<double> calculateOut(const vector<double>& in)
{
//用两个嵌套循环遍历神经网络的每一层,外部控制层数l,内部控制单个神经元j
//最后一层没有权重与权重调整值,所以l从1开始
for (int l =1 ; l < layerUnits_value.size(); l++)
{
for (int j = 0; j < layerUnits_value[l].size(); j++)
{
//初始化当前神经元的加权和z
double z = layerUnits_weight[l - 1][layerUnits_value[l - 1].size()][j];
for (int i = 0; i < layerUnits_value[l - 1].size(); i++)
{
//将输入向量in的值传给第一个隐藏层(l==1表示第一个隐藏层,作为该隐藏层的输入)
//在后续的代码中,这些输入值会与权重进行加权求和,用于计算每个神经元的输入信号总和
layerUnits_value[l - 1][i] = (l == 1 ? in[i] : layerUnits_value[l - 1][i]);
z += layerUnits_weight[l - 1][i][j] * layerUnits_value[l - 1][i];
}
layerUnits_value[l][j] = 1.0 / (1.0 + exp(-z));
}
}
//输出向量
return layerUnits_value[layerUnits_value.size() - 1];
}
//逐层反向计算误差并且修改权重
//tar为目标向量
void updateWeight(const vector<double>& tar)
{
//最后一层(输出层)的层数下标
int l = layerUnits_value.size() - 1;
//在输出层计算每个神经元的误差
//layerUnits_value[l][j]*(1-layerUnits_value[l][j])为sigmoid函数的导数
for (int j = 0; j < layerUnits_err[l].size(); j++)
{
layerUnits_err[l][j] = layerUnits_value[l][j] * (1 - layerUnits_value[l][j]) * (tar[j] - layerUnits_value[l][j]);
}
while (l-- > 0)
{
for (int j = 0; j < layerUnits_err[l].size(); j++)
{
//err为误差值的累加
double err = 0;
//对于每个神经元,计算当前层与下一层的权重调整量
for (int i = 0; i < layerUnits_err[l + 1].size(); i++)
{
err = err + (l > 0 ? layerUnits_err[l+1][i] * layerUnits_weight[l][j][i] : 0);//误差的累加
layerUnits_delta[l][j][i] = mobp * layerUnits_delta[l][j][i] + rate * layerUnits_err[l+1][i]*layerUnits_value[l][j];//更新权重调整量
layerUnits_weight[l][j][i] += layerUnits_delta[l][j][i];//更新权重
if (j == layerUnits_err[l].size() - 1)
{
layerUnits_delta[l][j+1][i] = mobp * layerUnits_delta[l][j+1][i] + rate * layerUnits_err[l+1][i];//更新bias项的权重调整量
layerUnits_weight[l][j+1][i] += layerUnits_delta[l][j+1][i];//更新bias
}
}
layerUnits_err[l][j] = err * layerUnits_value[l][j] * (1 - layerUnits_value[l][j]);
}
}
}
void train(const vector<double>& in, const vector<double>& tar)
{
vector<double>out = calculateOut(in);
updateWeight(tar);
}
};
int main()
{
//初始化神经网络的基本配置
//第一个参数是一个存储int类型的vector容器,第二个为学习步长,第三个为动量系数
BpDeep bp = BpDeep(vector<int>{2, 10, 2}, 0.15, 0.8);
//设置样本数据,对应4个二位坐标数据
vector<vector<double>> in = { {1,2},{2,2},{1,1},{2,1} };
//设置目标数据,对应4个坐标数据的分类
vector<vector<double>> tar = { {1,0},{0,1},{0,1},{1,0} };
//迭代训练50000次
for (int n = 0; n < 50000 ;n++)
{
for (int i = 0; i < in.size(); i++)
{
bp.train(in[i], tar[i]);
}
}
//根据训练结果来检验样本数据
for (int j = 0; j < in.size(); j++) {
vector<double> result = bp.calculateOut(in[j]);
cout << "[";
copy(in[j].begin(), in[j].end(), ostream_iterator<double>(cout, " "));
cout << "]:[";
copy(result.begin(), result.end(), ostream_iterator<double>(cout, " "));
cout << "]\n" << endl;
}
// 根据训练结果来预测一条新数据的分类
vector<double> x = { 3, 1 };
vector<double> result = bp.calculateOut(x);
cout << "[";
copy(x.begin(), x.end(), ostream_iterator<double>(cout, " "));
cout << "]:[";
copy(result.begin(), result.end(), ostream_iterator<double>(cout, " "));
cout << "]\n" << std::endl;
return 0;
}
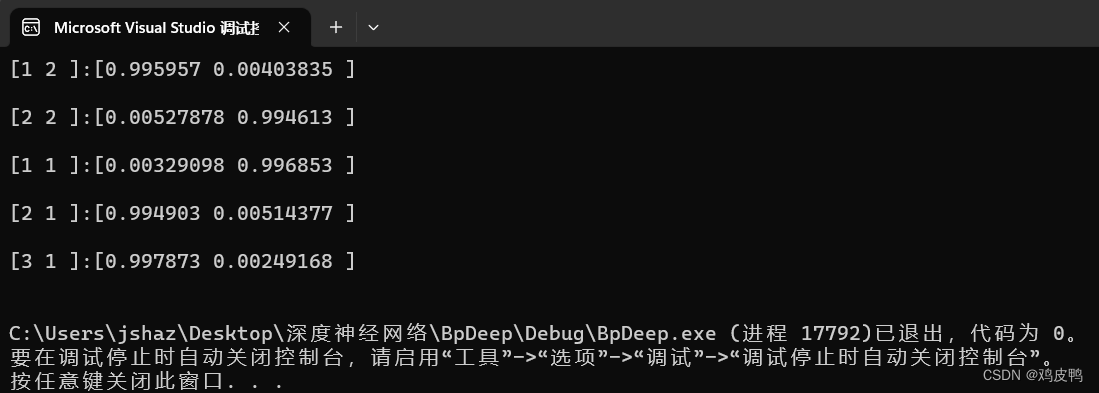
运行成功截图:
本文部分内容引用自开头转载的博客,版权声明:本文为CSDN博主「wtq1993」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接https://blog.csdn.net/wtq1993/article/details/50705677
本文部分内容引用自吴恩达老师BreakIntoAI with Machine Learning Specialization系列课程。
课程地址:机器学习 | Coursera
本文部分图片选自节目《偶像练习生》,特别感谢蔡徐坤先生以及《偶像练习生》节目组
不懂的部分可以在评论区进行留言~

















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









