







最近在看数据结构和算法相关的知识,数据结构可以影响算法的实现方式和效率。
以下内容参考:《算法神探:一部谷歌首席工程师写的cs小说》
搜索问题共同元素
- 目标:要搜索的数据
- 搜索空间:用于测探目标的所有可能性的组
- 搜索算法:进行搜索的具体指令和步骤
穷举算法
这种算法应该没有什么好说的了,优势是简单,在任何领域都容易实现;缺点是在结构化的数据中不够高效。
高效算法的关键在于有用的信息!
数组索引
这种对于查找某个位置的数值或者字符都是O(1)的效率。
有序数组的二分查找
二分搜索用于高效的在有序数组中查找目标值,工作原理是不断将搜索空间分为两半,并通过改变上下界有效地限制搜索空间。
- 以从小到大排列的数组为例,取出数组中间的那个值,与搜索值比较
- 若搜索值较大,则搜索值位于中间值到上界的区间中;反之,则位于下界和中间值的区间中
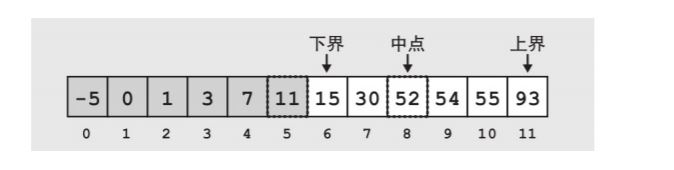
- 重复执行上述两个过程,直至找到搜索值,或者上界小于下界的时候(不存在该值)
此外,我们还要学会灵捷地改变算法,比如将有序数组改为有序环形数组等。

栈与队列
队列是一种先进先出的线性数据结构,如同我们平时的排队,讲究先来后到。我们在队列的头部取走元素,在尾部插入元素。


而栈则相反,是一种后进先出的数据结构。我们在栈的顶部插入元素,也在栈的顶部取走元素。


广度优先搜索
这是针对图搜索而言的(对于线性的结构与穷举算法没有区别),从图中的某个节点开始,如何找出我们想要的节点,或者说如果遍历整个图。
在搜索的过程中,我们还需要一个队列来帮助我们记录下一个应该搜索的节点。以下图为例(左边为图,右边为队列):

我们从A点开始搜索,首先将A放入队列中,然后从队列中取出元素(这次是A)搜索,如果是我们所要搜索的值,搜索结束;如果不是,将A的邻接点(B、D)放入队列(如下图)。

接着,继续从队列中取出元素,根据队列先进先出的原则,这次我们取出的是B节点。比较B节点与搜索值,如果是,结束搜索;如果不是,将B的邻接点C放入队列(需要注意A点虽然也是B的邻接点,但是A点已经被搜索过了,无需放入;同样,如果已经在队列中的邻接点也无需再次放入)。

重复上述的步骤,直至找到搜索的值,或者所有节点被遍历一次。遍历顺序为:ABDCEGFH
也可以将上述过程理解为按层级遍历

深度优先搜索
与广度优先搜索相对应的是深度优先搜索。深度优先搜索与广度优先搜索的区别在于,深度优先搜索使用的是栈来存放即将要搜索的结点,而并非队列。
同样是上面的搜索问题,这次遍历的顺序为:ABCFDEGH

其实,所谓的深度优先搜索,就是沿着一条路径去搜索,直至死路为止,再去换下一条路径。
迭代加深算法
这个算法是深度优先搜索的改版,它限制了每次搜索的深度。在第k轮搜索的时候,这个算法会执行一次深度限制为k的深度优先搜索。而且每次搜索需要从头开始。
还是以上面的图为例,在第一次搜索时,深度限制为1,只搜索A节点

第二次,深度限制为2,因此按照ABD的顺序搜索。

第三次,深度限制为3,按照ABCDEG的顺序搜索。
第四次,深度限制为4,按照ABCFDEGH的顺序搜索。

迭代加深算法虽然会加重我们的计算量,但是可以节省我们的内存,同时可以像广度优先搜索一样,避免在一些最坏的情况下被困在一条长的死路上。
并行算法
并行算法就是将一个问题分成数个小块,同时在这些小块上进行计算,最终将结果组合起来。相比于一个人进行更加快捷,但是并不是所有的问题都可以用并行算法的,有些问题即使增加并行数,也不能加快进度,比如审问一个嫌犯,100名警察并不能加快审问的速度。
同时并行计算也会增加工作量,我们需要额外地去分割问题和组合结果,可能会超出了并行计算带来的效益。
逆向索引
正常的索引会告诉我们,某个位置存放着什么内容。然而在查找一些重要的内容而不清楚这些内容的具体位置时,每次都要去遍历所有的数据,耗费时间。因此,建立逆向索引表,索引的内容为我们需要查找的内容,索引所指向的是这些内容存放的地址。
二叉搜索树
二叉搜索树是一种类似于二分搜索的数据结构。树中每个节点都存放一个数字, 每个结点最多有两个子节点(左节点和右节点),并且所有节点中的数要比它的左节点中的数大,比右节点中的数小。

当我们需要在二叉搜索树中寻找一个数时,我们只需要将它不断地与当前节点进行比较,如果比当前节点中的数小,就进入左节点;大,就进入右节点。直到找到我们的值,或者进入死路。
如果对于每个节点,其左子树中的节点数量都和其右子树中的节点数量一致,我们就可以说这个二叉搜索树是完全平衡的。在这种情况下,如果我们将树中的节点数量翻倍,整棵树的高度只会增加1。
我们可以用类似于二分法的方式,将一个有序数组转变为一棵二叉搜索树。

在使用二叉搜索树进行区间搜索时,我们可以对当前节点进行判断,如果当前节点在区间内,则需要搜索其左右两个结点;若在区间的左侧,则只需要搜索该节点的右节点,而不需要再对左节点进行搜索(这个过程称为剪枝);同样在区间的右侧,则只需要继续查找该节点的左节点。对于上面说的继续查找,只需要使用递归的思想,对子节点进行同样的操作即可,直至叶子节点。(比如查找区间[50,65]之间的数)

在对二叉搜索树进行插入时,需要从根节点开始。同时插入后不能保证树的平衡性。
trie树
trie树是基于树的数据结构,用户可以很方便地通过某个字符串的前缀来搜索到目标字符串。与二叉搜索树一样,trie树也是首先从根节点开始,然后一步步向下选取分支节点。在trie树中,每一个节点下的分支数(即有多少个子节点),取决于所有字符串中当前节点字母的下一个元素有多少种不同的可能。所以,trie树的每个节点可能不止两个子节点。

插入搜索方式与二叉搜索树相似。
最佳优先搜索
最佳优先搜索是基于某种估值分数或者评价函数来选择接下来探索哪个状态的算法。每一个新发现的状态也都将被赋予一个分数(或者说权值),这个分数就是算法对这个新发现状态的估值。例如,我们可以为每一个状态标记上一个值,可能是目标状态的概率(如果这个概率可以被估计的话)或者是重要程度。其实最佳优先搜索就是在每时每刻维护着一个带有估值分数的状态列表,每次从这个有序列表取出下一个估值分数最高的状态去探索。
当然,最佳优先搜索也可以按照代价最小的规则来选取下一个要探索的状态,这个代价可以是当前状态到目标状态的估算距离。在这种情况下,每一步都要选择列表中估值最小的一个状态进行探索。
比如下面的这个迷宫问题,圈里的数值代表了到终点的距离。

根据最佳优先搜索,我们每次都选择走权值最小的点,因此路径如下图所示:

优先队列
与最佳优先算法对应的数据结构是最佳队列。这个队列的插入与存储与正常的队列相同,最佳队列中的每一个元素多了一个权值,每次从队列中删除数据是,会去寻找其中权值最大的数进行删除。
启发式搜索
启发式搜索是依据经验来帮助算法快速达到目标。不同的启发式搜索算法质量不同。
启发式搜索算法的一个最显而易见的例子是在生活中导航。不管你要穿越蜿蜒的迷宫、寻找一个未知城市,还是要找到通往餐厅的路,你都会发现自己在使用启发式搜索作为指导。如果有两条道路,你要先走哪一条?一种通常可靠的常见搜索法是根据简单的距离测量来进行优先选择。我喜欢的方法是使用“和鸟类飞翔路径”一样的距离测量法:如果路上没有挡路的东西,目标有多远?在实践中,这种搜索法意味着我总是要选择看起来让我离目标更近的路径——至少这条路径的方向是正确的。在这条路上,我可能会走进几个死胡同,但就整体而言,我发现这是一种有效的搜索法。
最大堆
最大堆是基于二叉搜索树的数据结构,它的每个节点与其子节点之间需要时刻维持有序关系。具体来说,堆在存储元素时一定要遵循堆的特性,对于最大堆,树中的任意一个节点的值都要大于(或等于)其下面的所有节点。这种结构允许最大堆高效地支持几个非常重要的操作:(1)找到最大的元素,(2)删除最大的元素,(3)插入任意元素。这三个操作使得堆成为实现优先级队列的理想数据结构。

由于根节点(数组中的第一个元素)总是最大堆中的最大值,因此你可以始终在固定时间内获取该值,而不论数组中还有多少其他元素。这使得用户可以有效地查找优先级队列中的最高值元素。
如果你想添加一个元素或删除最大元素,这个过程会更复杂,需要首先打破堆的特性,然后再逐步恢复堆的特性。为了添加一个新元素,首先将新的元素添加到数组的最后面(即树底层中的第一个空白处)。如果新添加入节点的值大于其父节点的值,这将破坏堆特性,因此需要将此节点向上移动,直到它不再大于其父节点的值,并重新恢复堆的特性。也就是说,如果新加入节点的值大于其父节点的值,就不断地将该节点的值与其父节点的值进行交换。例如,如果要将60这个数添加到前面的堆中,则首先将它插入底部,然后将其向上移动,进行两次与上一级节点的交换操作。因为第一次在与15交换后,该节点的值仍然大于其新的父节点55,所以还需要再与55交换一次。

删除最大值元素也是类似的。将原来的最大值与数组的最后一个元素交换位置,使原来最后的那个元素成为新的根节点。

接下来删除现在最后的这个元素就可以了(此时原来的最大值已经成为数组的最后一个元素)。虽然现在已经正确地删除了原来的最大值的节点,但这个操作也破坏了堆的特性。

我们需要从新的根节点开始沿树向下调整该节点,以恢复堆的特性。在树的每一层,我们将该节点的值与其子节点进行比较。如果该值小于它的任何一个子节点的值,就需要将该值向下移动,并将两个子节点中值较大的那个子节点与其交换位置,以恢复堆的特性。直到该节点的子节点都比这个值小时,就结束操作。

插入新元素和删除最大元素的操作都需要我们从树顶部逐层调整直至合适的位置,不过最多只需从顶部到底部调整一遍。如果要往堆中增加一倍的节点,只需要在堆的底部增加一层节点即可,所以此时的插入和删除操作依然很快,即使是一个大的堆也会很快。换句话说,虽然堆的节点总数增加了一倍,但堆的层数只增加了一层,插入和删除操作仅比原来多交换一次。此外,由于上述插入和删除操作可以保持树的平衡,所以之后的操作也同样是高效的。
小结
高效算法的关键在于信息。















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









