







参考: https://blog.csdn.net/qq_37541097/article/details/118242600.
这个人讲得挺好的,很适合小白
ViT 的整体架构

——————————————————————————————————
1. Embedding层结构:

对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。

图像是三维的【H,W,C】论文是【224,224,3】
需要先通过一个Embedding层来对数据做个变换。
如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到( 224 / 16 )^2=196 Patches。接着通过线性映射成将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为16x16x3=768的向量(后面都直接称为token)。[16, 16, 3]→[768]
这时候num_token=196,token_dim=768
ViT-B/16整体架构的分解

在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] →[14, 14, 768],然后把H、W两个维度展平即可[14, 14, 768] → [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
2. Position Embedding
Position Embedding:在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768])→ [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。(作者对比了几种不同的Position Embedding,发现结果差不多,都比不使用效果要好)

3. Transformer Encoder 的详解

3.1 Layer Norm:
跟BN的效果差不多,不用BN是因为处理自然语言时每条数据的长度可能不同。
在Pytorch的LayerNorm类中有个normalized_shape参数,可以指定你要Norm的维度 (注意,函数说明中the last certain number of dimensions,指定的维度必须是从最后一维开始) 。比如我们的数据的shape是[4, 2, 3],那么normalized_shape可以是[3](最后一维上进行Norm处理),也可以是[2, 3](Norm最后两个维度),也可以是[4, 2, 3](对整个维度进行Norm),但不能是[2]或者[4, 2],否则会报以下错误(以normalized_shape=[2]为例):

3.2 Multi-Head Attention
多头注意允许模型共同关注来自不同位置的不同表示子空间的信息

3.3 Dropout/DropPath
在原论文的代码中是直接使用的Dropout层。
Dropout 层一般加在全连接层 防止过拟合,提升模型泛化能力。而很少见到卷积层后接Dropout(原因主要是 卷积参数少,不易过拟合)。
3.4 MLP Block
全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
————————————————————————————————————
4. MLP Head详解
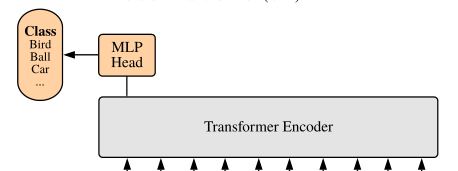

上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面有我自己画的ViT的模型可以看到详细结构。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
———————————————————————————————————————
5. ViT模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。

















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









