







检测 是发现问题
诊断 是找到原因
误差的分类
- 系统误差:系统误差是由于仪器本身不精确,或实验方法粗略,或实验原理不完善而产生的。
- 随机误差:随机误差是由各种偶然因素对实验者、测量仪器、被测物理量的影响而产生的。
- 粗大误差:粗大误差是明显超出测定条件下预期的误差,即是明显歪曲检测结果的误差,应想办法予以发现和剔除。
环比和同比
- 同比
同比是指与去年同期相比的数据变化率。它通常用于衡量某一时期与去年同期相比的增长或下降情况。通过同比分析,我们可以快速了解当前市场状况与去年同期相比的变化趋势。
计算方法:同比变化率 = (本期数值 - 去年同期数值) / 去年同期数值 × 100% - 环比
环比是指与上一统计周期相比的数据变化率。它通常用于反映近期数据的变化趋势。通过环比分析,我们可以更好地了解数据随时间推移的发展趋势。
计算方法:环比变化率 = (本期数值 - 上期数值) / 上期数值 × 100%
小概率事件: 在统计学中把概率小于0.05或0.01的事件称为小概率事件。
显著性水平: 在统计假设检验中,公认的小概率事件的概率值被称为统计假设检验的显著性水平。
置信度: 置信区间包含总体参数的确信程度,即1-α。
例如:95%的置信度表明有95%的确信度相信置信区间包含总体参数(假设进行100次抽样,有95次计算出的置信区间包含总体参数)。
临界值: 与检验统计量的具体值进行比较的值。是在概率密度分布图上的分位数。这个分位数在实际计算中比较麻烦,它需要对数据分布的密度函数积分来获得。
假设检验原理
在假设检验过程中,通常会将观察到的统计量与一个临界值进行比较,若观察到的统计量大于或小于临界值,则认为该统计量有显著性差异或无显著性差异。
目录
1. 背景
指标与业务息息相关,其价值在于发现问题和发现亮点,以便及时地解决问题和推广亮点。随着电商业务的进一步发展,业务迭代快、逻辑复杂,指标的数量越来越多,而且指标之间的差异非常大,变化非常快,如何能够快速识别系统各项异常指标,发现问题的根因,对业务来说至关重要。 如果通过手动的方式去设置报警阈值容易出现疏漏,且非常耗时,成本较高。我们希望构建一套自动化方法,能够达成以下目标:
- 自动化: 无需依赖用户输入。传统的方式是需要定义异常规则、归因维度等等,在自动化系统中不再需要用户手动输入。
- 通用性:能够适应多种多样的指标分布,不同的指标匹配不同的方法。
- 时效性:实现天级、小时级的指标异常检测和归因。
准确性和主动性:实现数据找人的目标。
接下来将分别介绍指标异常检测、指标异常诊断。
2. 指标异常检测
1.异常的分类
数据指标的异常,指标的过高过低、大起大落都不正常,都需要进行预警和诊断。指标的异常分为以下三种:
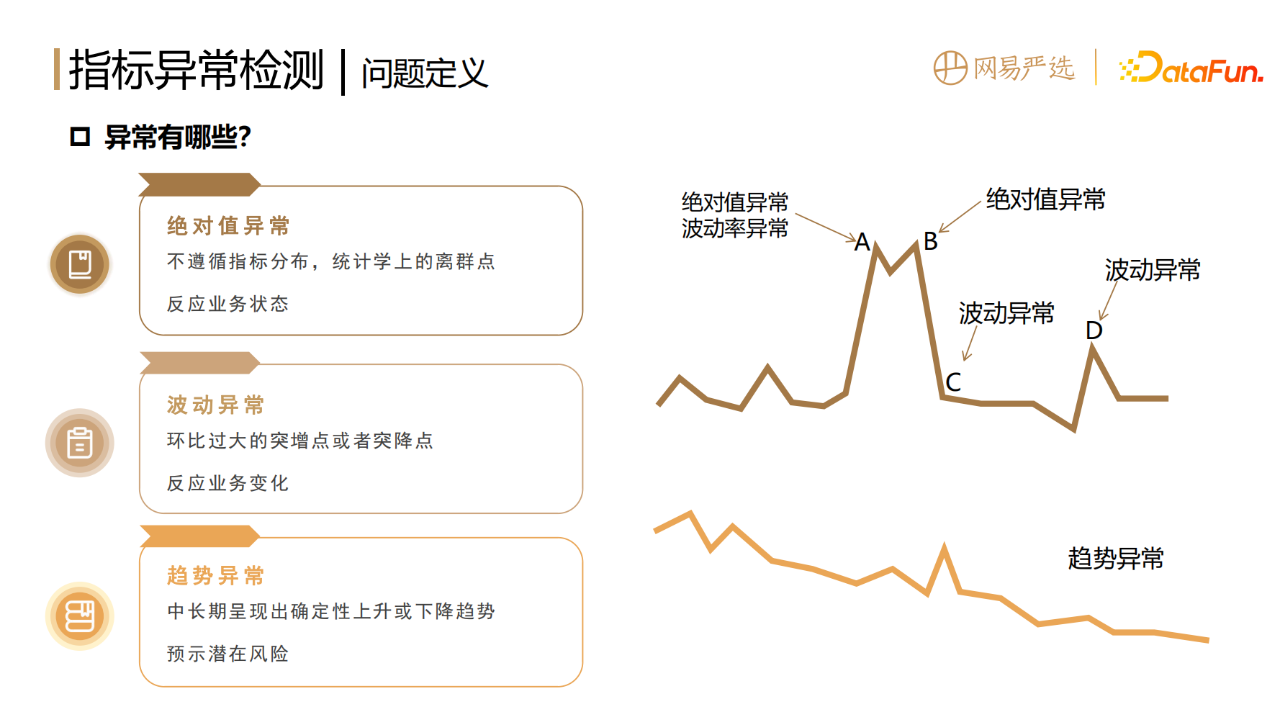
1. 绝对值异常(单点异常)
指的是不遵循指标固有的分布,在统计学上的离群点,它反映的是业务当下的状态。
2. 波动异常
环比过大的突增点或者突降点,反映的是业务当下突然的变化。
3. 趋势异常
前两种异常是偏单点的,是短暂剧烈的,而有些异常则相对隐蔽,是在中长期呈现出确定性上升或者下降的趋势,往往预示着某些潜在的风险,所以我们也要进行趋势的异常检测,进行业务预警和提前干预。
指标异常检测算法
1.绝对值异常检测
- 3Sigma准则
适用分布:正态分布
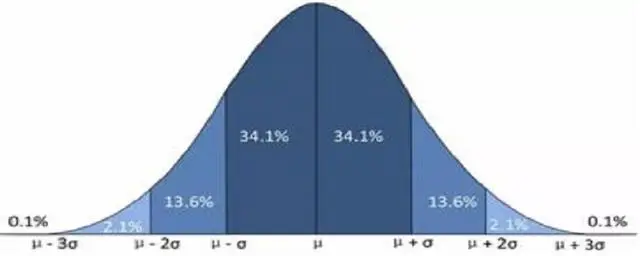
3σ(西格玛)准则又称为拉依达准则,它是先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。
3σ准则可以用于剔除粗大误差。
缺点:检出率过低(小于1%),只能检出非常极端异常的问题。
- IQR(Interquartile Range)方法
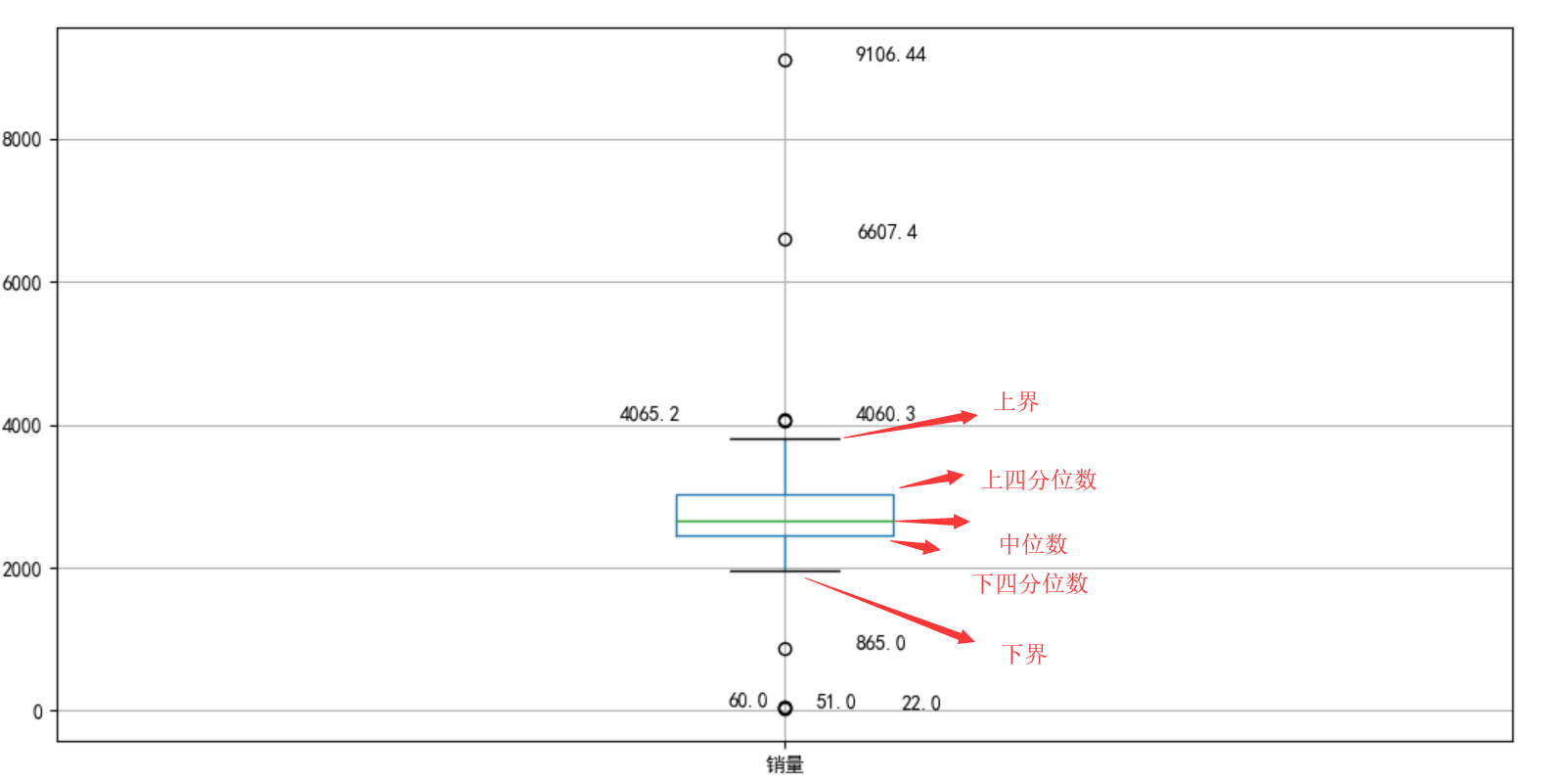
适用分布:非正态分布
根据数据的四分位数范围来判断数据是否为异常值。 IQR通过将数据集分成四个相等的四分位数来测量变异性。首先,将整个数据按升序排序,然后将其分成四个相等的四分位数,分别称为 Q1、Q2、Q3 和Q4
计算第一和第三四分位数(Q1、Q3),异常值是位于四分位数范围之外的数据点xi,k一般取1.5或3:
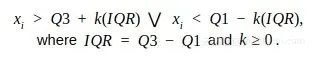
示例:
# quantile函数
def quantile(data, quantile):
sorted_data = sorted(data)
position = (len(data) - 1) * quantile
result = sorted_data[int(position)]
return result
# 计算异常值
def outlier(series):
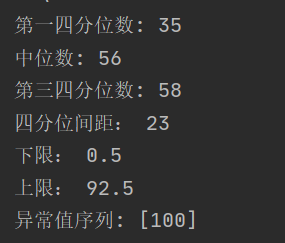
# 计算第一四分位数
Q1 = quantile(data, 0.25)
print("第一四分位数:", Q1)
# 计算中位数
Q2 = quantile(data, 0.5)
print("中位数:", Q2)
# 计算第三四分位数
Q3 = quantile(data, 0.75)
print("第三四分位数:", Q3)
#四分位间距IQR
IQR=Q3-Q1
print("四分位间距:",IQR)
#下限
low=Q1-1.5*IQR
print("下限:",low)
#上限
upper=Q3+1.5*IQR
print("上限:",upper)
result =[]
for num in series:
if num < low:
result.append(num)
if num > upper :
result.append(num)
return result
if __name__ == "__main__":
data = [30,31,32,32,32,35,35,35,35,35,37,49,56,56,56,57,57,57,58,59,60,60,60,80,92,100]
print("异常值序列:",outlier(data))
结果:
- GESD检验算法
适用分布:正态分布
首先绝对值检测主要是基于GESD检验算法,它的原理是通过计算统计量来寻找异常点。过程如下:-
假设数据集中有最多r个异常值。 第一步先找到离均值最大的样本i,然后计算 统计量Ri ,即xi减去均值后的绝对值,除以标准差。

-
接下来计算对应的样本点i的临界值λi,其中的参数n 是总共的样本量,i是已剔除的第几个样本,tp,n-i-1是具有 n-i-1自由度的t 分布的p 百分点,而p与设定的置信度α(一般α取值为0.05)及当前样本量有关。

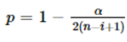
-
第三步是通过剔除离均值最大的样本i,然后重复上面步骤,一共r次。
-
第四步寻找统计量 Ri 大于λi的样本,即为异常点。
-
H0:|u|<=u0
H1:|u|>u0
GESD用的是双边检验,详情参考Grubbs TEST
这种方法的优点:
一是无需指定异常值的个数,只需要设定异常的上限,在上限范围内,算法会自动捕捉异常点;
二是克服了3Sigma检出率过低(小于1%),只能检出非常极端异常的问题。
在GESD算法中可以通过控制检出率的上限去做适应,但是这个方法的前提是要求输入的指标是正态分布。我们目前观测的电商业务指标绝大多数是属于正态分布的,当然也有个别业务指标(<5%)属于非正态分布,需要采用其他方法来兜底,如quantile。
2.波动异常检测
适用分布:正态分布or非正态分布
主要是基于波动率分布,计算分布的拐点。
这里不能直接对波动率分布套用上面的办法,主要是因为指标波动率绝大多数不是正态分布所以不适用。找拐点的原理是基于二阶导数和距离来寻找曲线上的最大弯曲点。
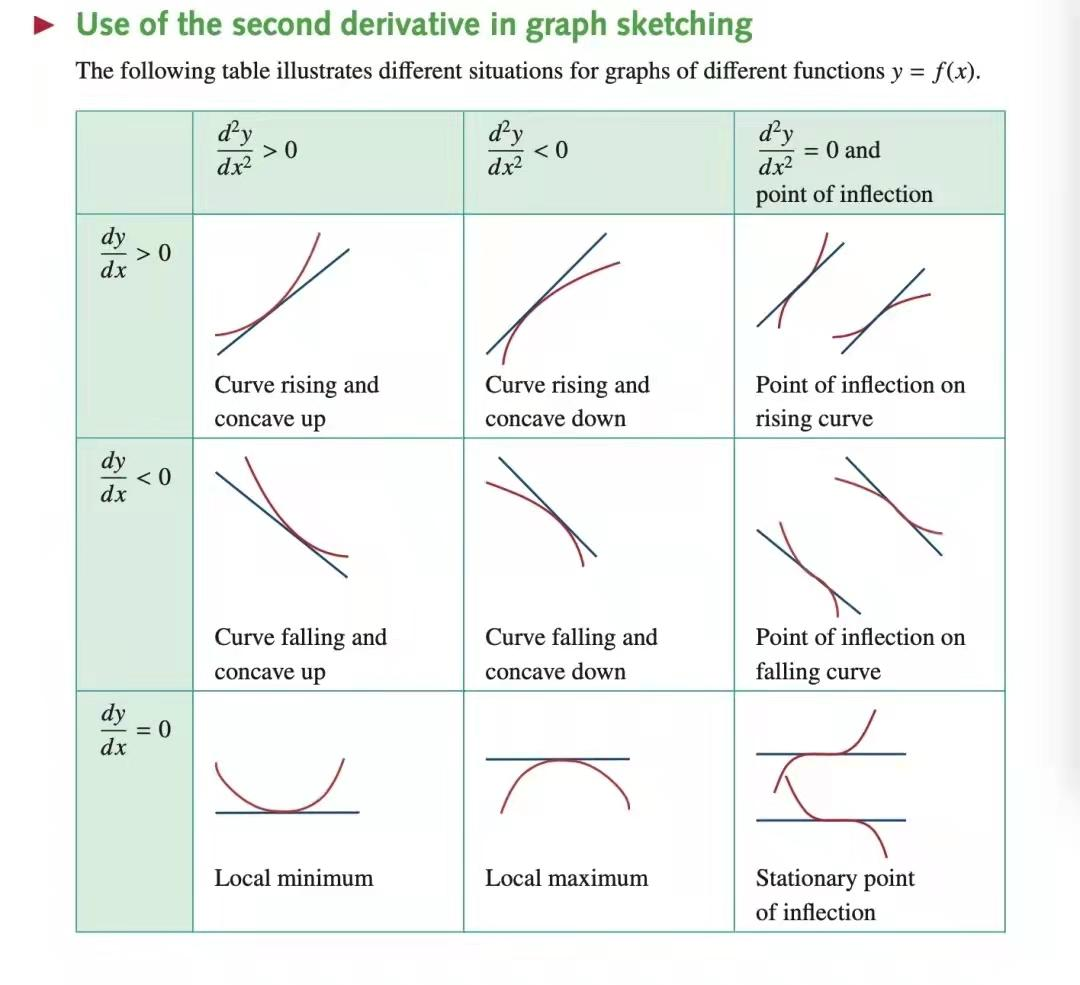
增长的波动率大于 0,下降的波动率小于 0,针对在 y 轴两侧大于 0 和小于 0 的部分,分别要找两个波动率的拐点,波动率超出拐点的范围,就认为是波动异常。但个别情况下拐点会不存在,或者拐点来得太早,导致检出率太高,所以也需要其他的方法来兜底,如quantile。一种检验方法不是万能的,需要组合来使用。
(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5305
5305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









