







 本文提出了一种名为SADNet的空间自适应去噪网络,利用残差空间自适应块和可变形卷积来适应图像纹理和边缘变化,同时结合Contextblock捕获多尺度信息。这种方法有效地去除图像噪声,尤其适用于合成噪声和真实噪声图像的去噪,能够在保持图像细节的同时,提高去噪效果。SADNet在多组实验中展现出优于其他SOTA算法的性能,并且运行速度快。
本文提出了一种名为SADNet的空间自适应去噪网络,利用残差空间自适应块和可变形卷积来适应图像纹理和边缘变化,同时结合Contextblock捕获多尺度信息。这种方法有效地去除图像噪声,尤其适用于合成噪声和真实噪声图像的去噪,能够在保持图像细节的同时,提高去噪效果。SADNet在多组实验中展现出优于其他SOTA算法的性能,并且运行速度快。
系列文章目录
论文名称:Spatial-Adaptive Network for Single ImageDenoising(用于单张图像去噪的空间自适应网络)
论文地址:https://arxiv.org/abs/2001.10291
代码地址:https://github.com/JimmyChame/SADNet
发表时间:2020
应用领域:合成噪声图像及真实噪声图像去噪
key word:残差空间自适应块、可变形卷积、Context block
文章目录
摘要
先前的工作表明CNN已可以在image denoising上取得良好的效果,但是很可能会导致图像过于光滑,以额外的计算开销为代价使用较深的网络结构可以缓解这类问题。在本文中,作者提出了一种新的空间自适应去噪网络(spatial-adaptive denoising network,SADNet)来有效地去除单张图像的盲噪声。为了适应空间纹理和边缘边缘的变化,设计了一个残差空间自适应块(residual spatial-adaptive block)。引入可变形卷积(Deformable convolution)对空间相关特征进行采样。引入具有上下文块的encoder-decoder来捕获多尺度信息(multiscale information)。通过从粗到细的噪声去除,得到高质量的noise-free image。该方法可以用于synthetic noisy image和real-word noisy image的去噪。
introduction
image denoising是计算机视觉以及图像处理领域中的关键任务。许多早期的基于模型的方法(model-based methods)先找到图像的先验信息(priors)然后再应用优化算法迭代求解模型,这样的方法十分耗时而且效果不佳。随着深度学习的兴起,CNN被广泛应用于Denoising而且取得了不错的效果。
早期工作中大多假设噪声是独立且均匀分布的,加性高斯白噪声常被用于建模生成噪声图像。而现在人们意识到实际上噪声是以更复杂的形式出现的,在空间上可变(spatially variant)且与信道相关(channel dependent)。虽然人们在real-world noisy image的去噪上取得了很大的进展,但仍有一些问题待解决。传统的CNN智能使用在局部固定点附近的特征(feature in local fixed-location neighborhoods),但是这些特征可能是与当前位置无关或是独立的(irrelevant or exclusive to the current location)。由于无法适应纹理和边缘(textures and edges),基于CNN的方法很容易导致图像过于平滑、细节丢失。此外传统CNN的感受野(receptive field)相对较小,通过加深网络结构来扩展感受野又会导致较高的资源消耗。
在本文中,使用SADNet来解决以上问题。作者设计了一个残差空间自适应块(residual spatial-adaptive block,RSAB)来适应空间纹理和边缘的变化。将RSAB和残差块(ResBlock)合并到encoder-decoder结构中,从粗到细地去除噪声。在最粗尺度(coarsest scale)使用context block来扩大receptive field,可以在小的计算开销下获得良好的性能。
贡献总结:
- 提出一种新型的空间自适应去噪网络SADNet,从复杂的图像中捕获特征,从噪声中恢复细节和纹理以有效地去除噪声。
- 提出了残差空间自适应块RSAB,引入可变形卷积(deformable convolution)来适应空间纹理和边缘。使用带有上下文块的encoder-decoder结构来捕获多尺度信息,从粗到细地去除噪声。
- SADNet可以在多个sybthetic noisy image datasets 和 real noisy image datasets 的去噪上取得良好的效果。
Related work
总的来说,image denoising包括model-based和learning-based 两类。model-based的方法使用建模的分布作为先验信息,尝试使用优化算法获得noisy-free的图像。常见先验信息包括local smoothing(局部光滑)、sparsity(稀疏性)、non-local self-similarity(非局部自相似)和external statistical prior(外部统计先验)。Non-local self-similarity是denoising task 的显著先验,相关的算法有NLM、BM3D、WNNM等,都已得到广泛应用。随着DNN的普及,learning-based的denoising方法发展迅速,这里只简单提一下作者对比的几种算法:FFDNet、N3N、DnCNN、FFDNet、CBDNet、RIDNet等。详细参考原文…
网络架构
整体网络架构
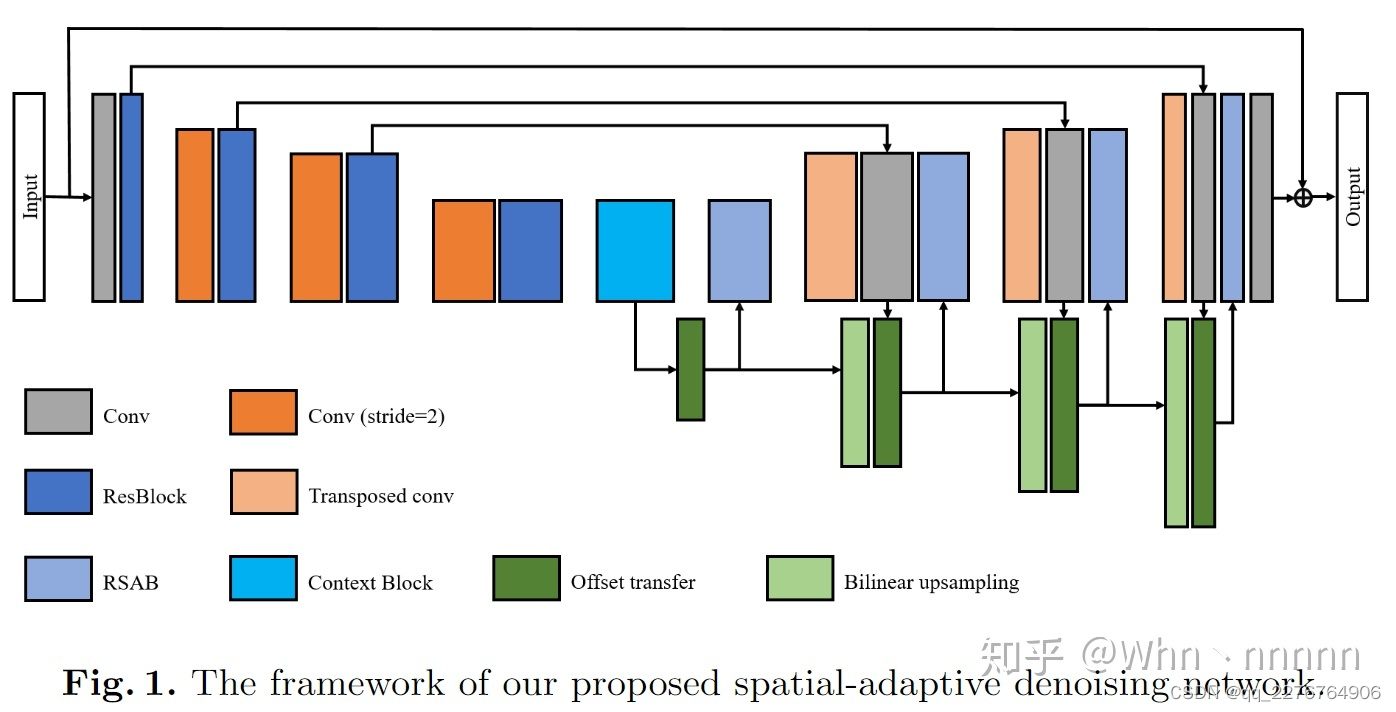
SADNet的网络结构如上图所示,令x为输入的噪声图像,
y
^
\hat{y}
y^为对应的去噪输出图像,那么模型即可表示为
y
^
=
S
A
D
N
e
t
(
x
)
\hat{y}=S A D N e t(x)
y^=SADNet(x)。
使用1层Conv层从噪声输入中提取初始特征(initial features),将这些特征输入到multiscale encoder-decoder结构中。在encoder部分使用ResBlocks提取不同尺度的特征,不同于原始的ResBlock,在使用时删除了BN层(Batch Normalization)而且使用leaky ReLU作为激活函数,为了避免损坏图像结构,限制了下采样的操作次数,并使用一个context block来进一步扩大感受野(receptive field)并捕获多尺度信息;在decoder部分,设计了residual spatial adaptive blocks(RSABs)来对相关特征进行采样和加权以消除噪声并重构纹理。此外还估计了偏移量(offset),这对于获得更精确的特征位置很有帮助。最后将重构的特征输入到最后一个Conv层来还原去噪后的图像。
除了网络结构以外,损失函数也至关重要,denoising task常用的损失包括L2 loss、L1 loss、perceptual loss、asymmetric loss(非对称损失)、联合损失等。L2 loss对于Gaussian noise有很好的置信度;L1 loss对异常值(outliers)有更好的容忍度。在本文中,使用L2 loss训练synthetic noisy image datasets;使用L1 loss来训练real-workd noisy image datasets。
Residual spatial-adaptive block
首先介绍deformable convolution(可变形卷积)在细致地介绍RASB。
令
x
(
p
)
x(p)
x(p)为输入特征图x中位置p处的特征,对于传统的卷积操作,对应的输出特征
y
(
p
)
y(p)
y(p)可以通过
y
(
p
)
=
∑
p
i
∈
N
(
p
)
w
i
⋅
x
(
p
i
)
y(p)=\sum_{p_{i}\in N(p)}w_{i}\cdot x(p_{i})
y(p)=∑pi∈N(p)wi⋅x(pi),其中N§代表位置p的neighborhood,它的大小和卷积核相同,
w
i
\stackrel{}{w}_{i}
wi为卷积核中位置p处的权重,
p
i
p_i
pi为
N
(
p
)
N(p)
N(p)中的位置。传统卷积严格地采用p周围固定位置的特征来计算输出特征,因此有一些不需要或是不相关的特征可能会干涉输出的计算。所以作者引用了deformable convolution来适应空间纹理的变化。
Deformable convolution可以改变卷积核的形状,1.他首先为每个位置学习一个偏移图(offset map),2.然后将所得偏移图应用于特征图,3.对相应特征进行重采样来进行加权。使用可调制的deformable convolution。
它提供了一个自由度来调整空间支撑区域(spatial support regions):
y
(
p
)
=
∑
p
i
∈
N
(
p
)
w
i
(
p
i
+
Δ
p
i
)
⋅
Δ
m
i
y(p)=\sum_{p_{i}\in N(p)}w_{i}(p_{i}+\Delta p_{i})\cdot\Delta m_{i}
y(p)=∑pi∈N(p)wi(pi+Δpi)⋅Δmi,其中
Δ
p
i
\Delta p_i
Δpi为位置
p
i
p_i
pi的可学习偏移(learnable offset),
Δ
m
i
\Delta m_i
Δmi为可学习的调制标量(learnable mod-ulation scalar)范围在[0,1]。它反映了采样特征
x
(
p
i
)
x(p_{i})
x(pi)与当前位置的特征之间的相关程度,因此调制后的deformable convolution可以调整输入特征幅度(feature amplitudes)来进一步调整spatial support regions。
Δ
p
\Delta p
Δp和
Δ
m
\Delta m
Δm都来自于先前的特征。
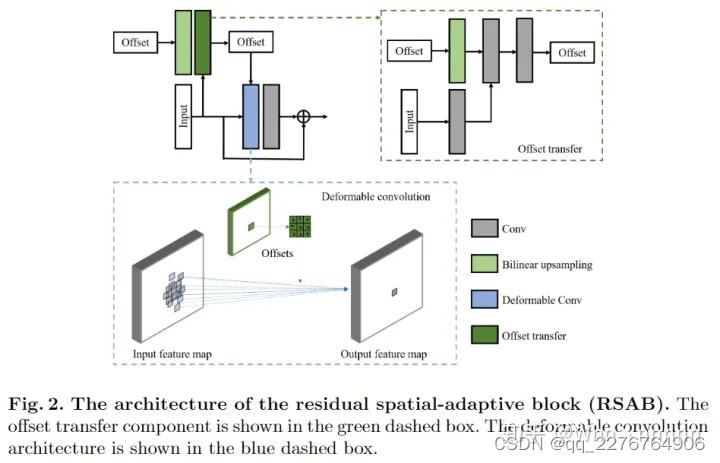
在每个RSAB中,首先将提取的特征(extracted features)和上一尺度的重构特征(reconstructed features)融合(fuse)后作为输入。RSAB由一个调制可变形卷积(modulated deformable convolution)跟着一个带有短跳跃连接(short skip connection)的传统卷积组成。与ResBlock类似,使用局部残差学习(local residual learning)来增强信息流并提高网络的表达能力,不同的是,将第一个Conv替换为modulated deformable convolution并且使用leaky ReLU作为激活函数,所以RSAB可以记为
F
R
S
A
B
(
x
)
=
F
c
n
(
F
a
c
t
(
F
d
c
n
(
x
)
)
)
+
x
F_{RSAB}(x)=F_{cn}(F_{act}(F_{dcn}(x)))+x
FRSAB(x)=Fcn(Fact(Fdcn(x)))+x。其中
F
d
c
n
F_{dcn}
Fdcn和
F
c
n
F_{cn}
Fcn分别为调制可变形卷积和传统卷积,
F
a
c
t
F_{act}
Fact为激活函数(此处为leaky ReLU),RSAB的结构图如上图所示。
此外,为了更好地估计偏置,将last-scale的offsets
Δ
p
s
−
1
\Delta p^{s-1}
Δps−1转移到current scale s,同时使用
{
Δ
p
s
−
1
,
Δ
m
s
−
1
}
\{\Delta p^{s-1},\Delta m^{s-1}\}
{Δps−1,Δms−1}和输入特征
x
s
x^s
xs来估计
{
Δ
p
s
,
Δ
m
s
}
\{\Delta p^{s},\Delta m^{s}\}
{Δps,Δms}。偏移转移可以表示为:
{
Δ
p
s
,
Δ
m
s
}
=
F
o
f
f
s
e
t
(
x
,
F
u
p
(
{
Δ
p
s
−
1
,
Δ
m
s
−
1
}
)
)
\{\Delta p^s,\Delta m^s\}=F_{offset}(x,F_{up}(\{\Delta p^{s-1},\Delta m^{s-1}\}))
{Δps,Δms}=Foffset(x,Fup({Δps−1,Δms−1})),其中
F
o
f
f
s
e
t
F_{offset}
Foffset和
F
u
p
F_{up}
Fup分别代表offset transfer和upsampling。如上图所示,offset transfer涉及多个卷积,从输入中提取特征并将其与先前的偏移融合,以估计current scale 的offset,实验中采用双线性插值(bilinear interpolation)来进行上采样。
Context block
Multiscale information对于denoising task十分重要,所以网络经常会采取下采样(downsampling),但是当图像分辨率较低时,这样会导致图像结构被破坏,信息丢失。为了扩大感受野(receptive field)并且在不进一步降低分辨率的情况下捕捉multiscale information,作者在encoder和decoder之间的最小尺寸(minimum scale)引入了一个上下文块(context block),它使用几种具有不同扩张率(dilation rate)的空洞卷积(dilated convolutions),而不是下采样。可以在扩展感受野的同时不增加参数数量或破坏结构,将在从不同感受野提取的不同特征融合后用来估计输出(如下图所示)。
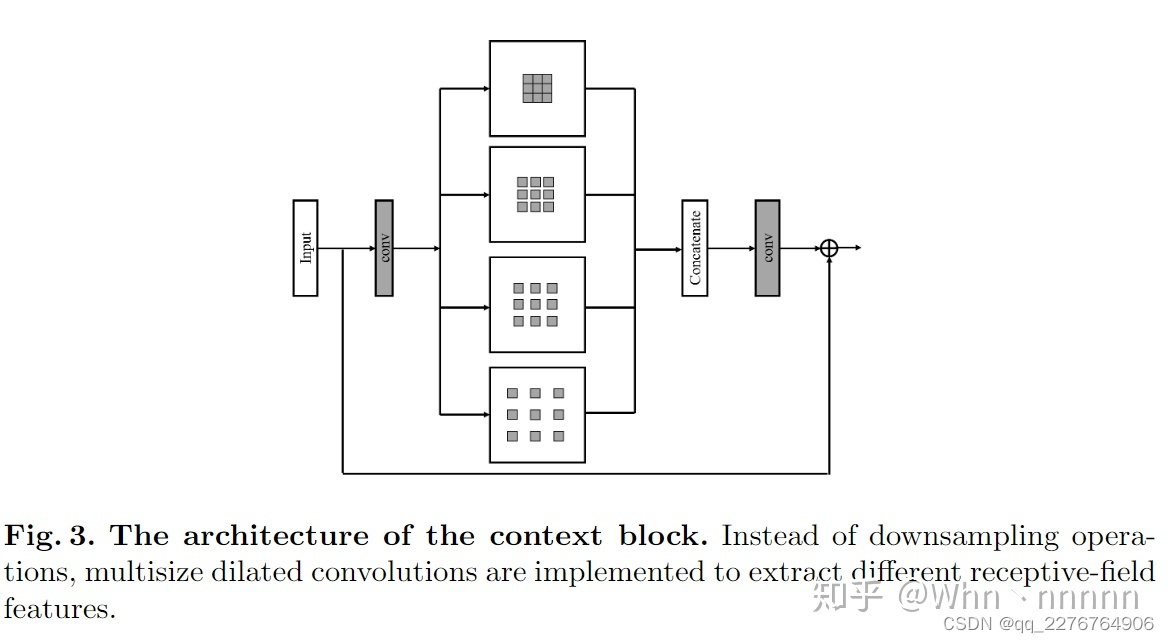
在本文中,已处理BN层,仅使用了设置为1、2、3、4的dilation rates,为了进一步简化操作缩短时间,首先使用1*1Conv来压缩特征通道。compression ratio设置为4,在融合(fusion)部分使用1 * 1卷积,类似地,在输入和输出特征之间使用local skip connection来防止信息阻塞。
implementation
在模型中,使用4个尺度(scale)的encoder-decoder,通道数分别设置为32、64、128、256,第一个和最后一个Conv层的核大小设置为11,最后的输出根据输入设置为1或3通道。此外,up/down-convolutional layers使用22 filters,其他conv层的核大小为3*3.
experiments
这部分还是主要已测试结果对比为主,其他部分比如训练的细节不详细说明,可以京一部参考论文和开源代码进行学习。
模型使用synthetic noisy images 和real-world noisy images 共同训练,使用包括800张图的DIV2K dataset 添加不同强度的噪声来生成synthetic noise datasets;对于real noisy images,使用SIDD、RENOIRhePoly,并通过旋转等方法进行数据增强。使用ADAM optimizer(
β
1
=
0.9
β
2
=
0.999
ϵ
=
1
0
−
8
\beta_1=0.9\,\beta_2=0.999\,\epsilon=10^{-8}
β1=0.9β2=0.999ϵ=10−8)进行训练,学习率等训练细节在此不赘述。
Abaltion study
通过消融实验验证模型的关键部分的确发挥作用,这里直接放结果:

Analyses of the spatial adaptability
这部分主要是为了分析模型学习到了空间适应性,从粗到细对图像进行去噪,多尺度结构使网络能够获取不同感受野的信息进行图像重建。…详见论文
comparisons
使用BSD68、Kodak24、DND、SIDD、Nam datasets与多个SOTA(state-of-the-art)算法进行去噪效果对比,这里主要放一些对比图和简单的分析:
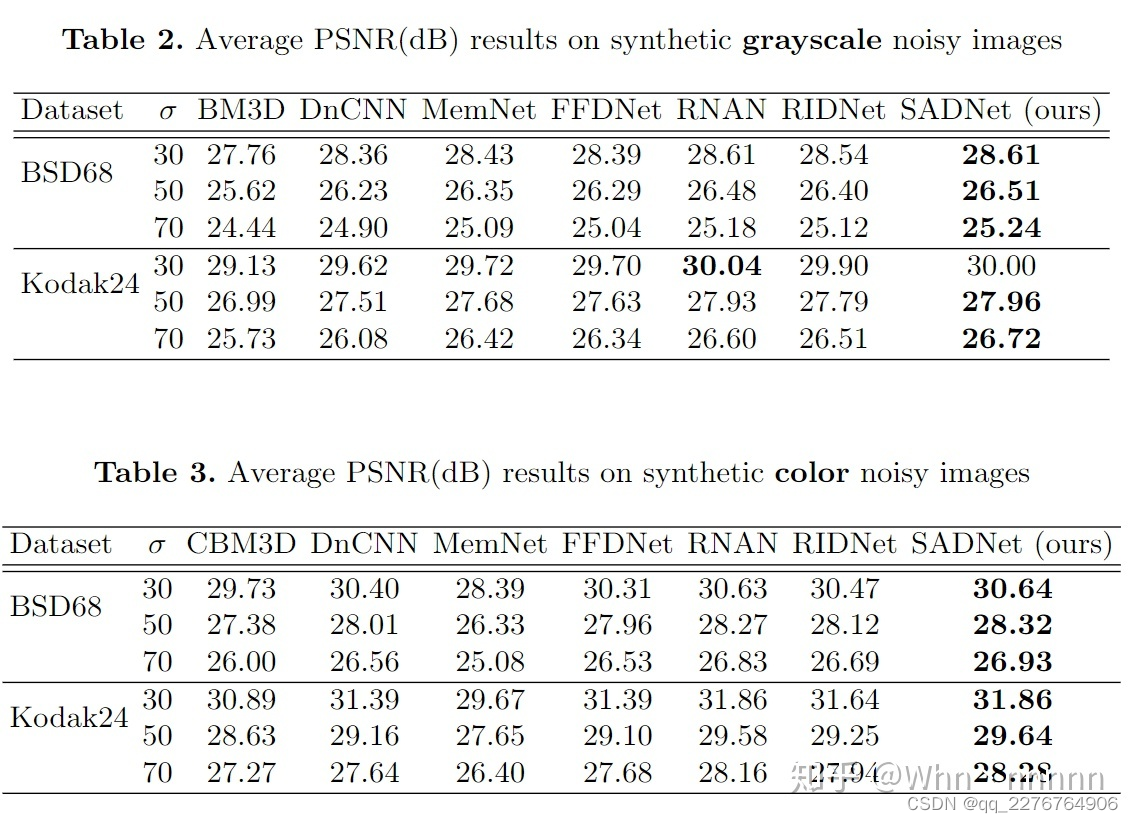


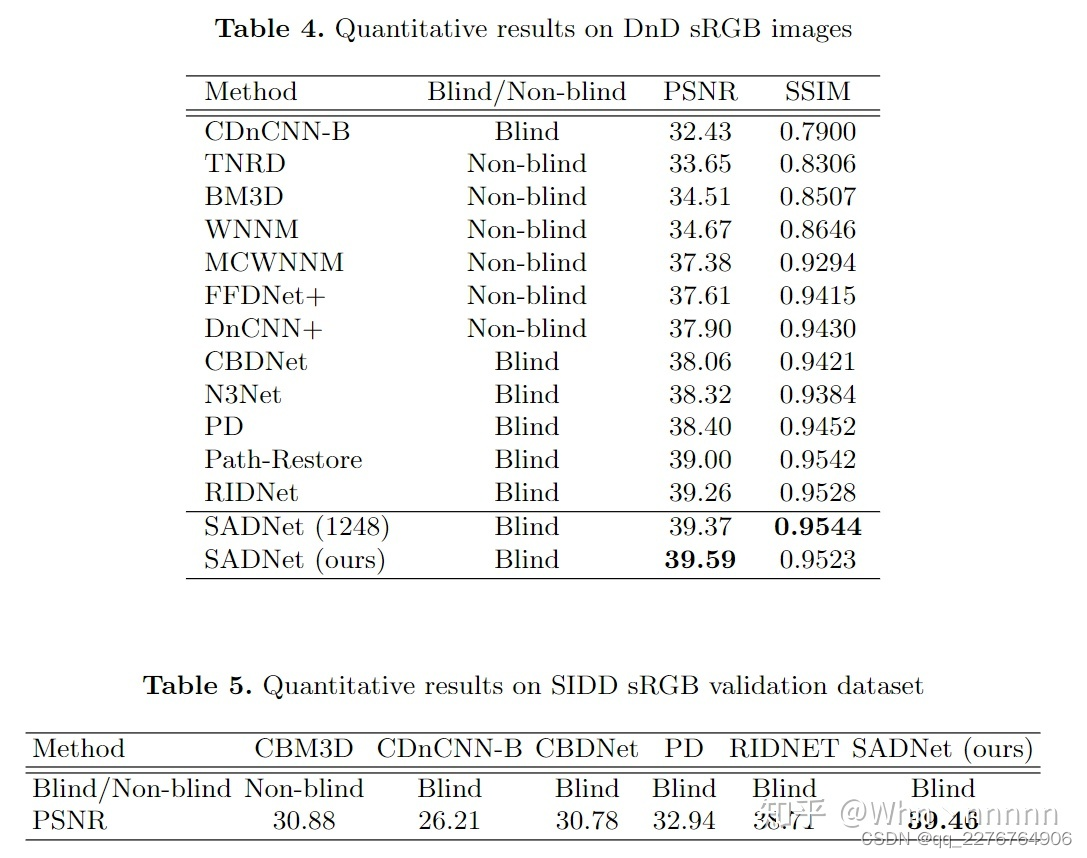

文章中还有几个其他的对比样例以及在使用Nam测试集在JPEG压缩的real-world noisy images上进行的去噪效果对比,这里就不一一附图了,详细可以参考论文,从上面的多张对比图中可以看出SADNet的确在各个方面由于CBDNet、RIDNet等SOTA去噪算法,是值得尝试和学习的。此外文章在Experiments的最后部分对比了SADNet和其他算法的参数和运行速度,虽然SADNet的参数很多,但是因为floating point operations(FLOPs)更少,所以运行速度要优于其他算法。
Conclusion
在本文中,作者提出了一种新的空间自适应去噪网络(spatial-adaptive denoising network),可以有效地去除图片中的噪声。SADNet由多尺度残差空间自适应块(multiscale residual spatial-adaptive block,RSAB)构成,还引入了上下文块(context block)捕获多尺度的信息并实现偏移量的传递。SADNet可以在复杂的场景中去除噪声并保存更多的细节,在synthetic images和real-world noisy images均表现出色达到SOTA级,而且有着不错的运行速度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









