







网址:
一、概述
1、BasicSR介绍
basicSR是一个开源项目,旨在提供一个方便易用的图像、视频的超分、复原、增强的工具箱。
一般说来,深度学习项目都可以分为以下几个部分:
- data:定义了训练数据,来喂给模型的训练
- arch(architecture):定义了网络结构和forward的步骤
- model:定义了在训练中必要的组件(比如loss)和一次完整的训练过程(包括前向传播,反向传播,梯度优化等),还有其他功能,比如validation等
- training pipeline:定义了训练的流程,即把数据dataloader、模型、validation、保存check-point等等串联起来
我们开发一个新的方法时,往往在改进data、arch、model这几块内容。而很多流程、基础的功能其实是公用的。
basicSR把很多相似的功能都独立出来,只需要关心data、arch、model的开发即可。
2、文档说明
本文档完整地介绍了BasicSR的设计和框架,为入门者提供一份上手指南。具体的函数和代码参见basicSR API文档
二、使用方式与场景
1、本地clone代码
在这个方式下,我们吧整个basicSR的代码都copy、clone下来,也就可以方便地查看basicSR的完整代码,修改并使用。当尝试复现、开发方法时,比较推荐此方式,因为可以更好地看到代码全貌,方便调试。
弱点:
-
整个仓库中有很多不需要使用的代码。basicSR提供了很多方法的实现。在自己的实验中,大部分的代码并不需要。但是他们基本是独立存在的,并不影响。
-
当发行自己新开发的方法(假如较NBCNN)的代码时,必须要发行包含整个basicSR的代码,而不能专注于NBCNN的核心代码。此时,比较推荐把basicSR当做一个Python package
2、basicSR作为Python package
basicSR有一个单独的Python package - basicsr,发布在pypi上。可以通过pip安装,提供了训练框架、流程、BasicSR中已有的函数和功能。可以基于basicsr方便地搭建自己的项目。只要专注于新方法的功能即可,同时自身项目的结构更简洁。
而basicSR这个python package,则可以进一步将已有函数和功能封装起来,只要关心新方法开发即可。
basicsr作为一个python package的安装方法
见第(三)章 -安装
如何基于basicsr Python package开发
模版:BasicSR-examples
开发方法:开发方法
缺点:
他会调用BasicSR里面的函数,如果里面的函数不能满足需求。或者有bug的情况,往往难以修改。(需要进入安装pip package的地方进行修改)。
解决方法:
在本地clone仓库的情况下开发,然后等到发布新方法时,再基于BasicSR-examples 新建一个仓库,使用basicsr的pip package
三、安装
本章节介绍了:
安装BasicSR所需要的环境依赖;
BasicSR的两种方式:本地clone源代码安装和pip安装basicsr包;
对于需要在项目中使用pytorch c++编译算子的情况,提供了相应的安装方式;
将安装过程中的常见问题进行了汇总;
1、环境依赖
由于BasicSR是基于python语言和pytorch深度学习框架进行开发的,因此在安装basicSR之前,需要在电脑或者服务器上安装python环境以及各种相关的python库(即环境配置和依赖安装两步);如果想要在GPU上运行,就需要在电脑上配置相应的CUDA环境,以下分别对CUDA和相应的python库进行简要说明。
NVIDIA GPU + CUDA:
- GPU(Graphics Processing Unit)由于其高效的并行能力,目前被广泛用于深度学习的计算中;
- CUDA(Compute Unified DeviceArchitecture)是NVIDIA推出的可以让GPU解决复杂计算问题的运算平台。如果需要训练BasicSR中的模型,需要使用GPU并配置好相应的CUDA环境。
python和python库(对于python库,作者提供了相应的安装脚本):
- python >= 3.7(推荐使用Anaconda或miniconda进行包管理和环境管理)
- pytorch >= 1.7 目前深度学习领域广泛使用的深度学习框架
附Anaconda介绍:
Anaconda是一个用于数据科学和机器学习的开源Python和R编程语言的发行版。它的目标是简化软件包管理和部署的过程。Anaconda带有一个名为Conda的软件包管理器,它使得在数据科学项目中安装、更新和管理库和依赖项变得非常容易。
Anaconda的主要特点包括:
软件包管理: Conda允许用户轻松安装、更新和卸载软件包和依赖项。它可以处理来自多个源的软件包,包括Anaconda仓库、Conda-forge等。
环境管理: Anaconda支持创建隔离的环境,这对于管理不同项目的依赖项非常重要。这有助于避免在不同项目中发生软件包冲突。
数据科学库: Anaconda包含一套全面的预安装库,这些库通常用于数据科学、机器学习和科学计算,如NumPy、pandas、scikit-learn、TensorFlow和PyTorch等。
跨平台: Anaconda适用于Windows、macOS和Linux,使其成为在不同操作系统上工作的数据科学家的多功能选择。
集成开发环境(IDE): Anaconda附带Anaconda Navigator,这是一个图形用户界面,提供对各种工具和环境的访问。Jupyter Notebooks是一个包含在其中的交互式计算环境。
要开始使用Anaconda,您可以从官方Anaconda网站下载并安装它。一旦安装完成,您可以使用Conda命令行界面或Anaconda Navigator图形用户界面来管理数据科学项目的环境和软件包。
当配置好python环境和CUDA环境之后(第一步,环境配置可参考),可以直接运行以下的脚本一次性安装BasicSR中调用的中python库(第二步)。其中,环境配置(第一步)是安装之前就必须搭建的,依赖安装(第二步),视具体安装方式和项目需求而定。
pip install -r requirements.txt //安装依赖脚本
注:requirements.txt
最后,basicSR是基于Linux开发的,但同时也支持windows环境,参见第4小节常见问题Q1
2、BasicSR安装
在安装好上述的环境依赖后,此时就可以进行BasicSR的安装了。*本小节的安装默认不适用pytorch c++编译算子,若需要参考本章第3节c++算子部分。
2.1本地clone代码
通过本地clone安装BasicSR,需要在终端上依次进行以下3个步骤。
1)克隆项目:
git clone https://github.com/XPixel/Group/BasicSR.git
2:安装依赖包:
cd BasicSR
pip install -r requirements.txt
3:在BasicSR的根目录下安装BasicSR:
python setup .py develop
如果希望安装的时候制定CUDA路径,可使用如下指令:
CUDA_HOME=/usr/local/cuda \
CUDNN_INCLUDE_DIR=/usr/local/cuda \
CUDNN_LIB_DIR=/usr/local/cuda \
python setup.py develop
2.2pip 安装
对于使用pip安装BasicSR,在终端运行以下指令即可:
pip install basicsr
如果希望安装的时候制定CUDA路径,可使用如下指令:
CUDA_HOME=/usr/local/cuda \
CUDNN_INCLUDE_DIR=/usr/local/cuda \
CUDNN_LIB_DIR=/usr/local/cuda \
pip install basicsr
2.3验证BasicSR是否安装成功
当选择了上述两种方式中的一种方式安装BasicSR后,我们可以通过执行以下命令判断是否成功安装
进入创建的环境中,输入以下命令,
python //进入python编译环境
import basicsr //导入 basicsr
如果此时没有报错,则说明basicSR安装成功,此时便可以基于BasicSR进行开发了
3 pytorch c ++ 算子
考虑到某些项目中会需要使用pytorch c++编译算子,作者在此小节正对这种情况也提供了相应的BasicSR安装方式。如果不需要使用相关C++算子,则此小节跳过。
对于项目中需要使用一下pytorch c++编译算子时,比如:
- 可变形卷积DCN(如果安装的torchvision版本>=0.9.0,会自动使用torchvision中提供的DCN,故不需要安装此编译算子),比如:EDCV中的DCN
- StyleGAN中的特定的算子,比如:upfirdn2d,fused_act
由于第2节中所提到的安装方式不支持pytorch c++编译算子,未来能够使用pytorch c++编译算子,此时需要一些特定的修改(有以下两种方式可供选择):
- 安装的时候对pytorch c++ 编译算子进行编译:
此时需要将原先的安装指令进行修改,其中BASICSR_EXT=True 中的EXT是单纯extension的缩写。
a. 对于通过本地clone代码安装BasicSR的方式,此时修改指令:
python setup.py develop --> BASICSR_EXT=True python setup.py develop
b.对于通过pip安装BasicSR的方式,此时修改指令:
pip install basicsr --> BASICSR_EXT=True install basicsr
进行了上述的修改后,如果我们需要运行styleGAN的测试代码(需要用到pytorch c++编译算子)(代码位于inference/inference_stylegan2.py),此时直接输入指令即可:
python inference/inference_stylegan2.py
- 每次在跑程序的时候即时加载(JIT)pytorch c++编译算子:如果我们选择了这种方式,此时不需要修改 BasicSR 的安装指令。依然拿 StyleGAN 的测试代码举例,在这种情况下,如果想要运行 StyleGAN 的测试代码,此时需要输入的指令是:
BASICSR_JIT=True python inference/inference_stylegan2.py
关于上述提到的两种使用 PyTorch C++ 编译算子方式之间的优劣和场景对比如表2.1所示:
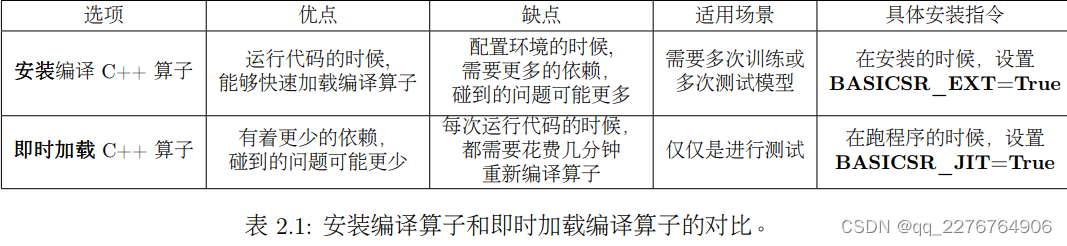
注意
- 对于需要在安装的时候就编译 PyTorch C++ 算子,需要确保:gcc 和 g++ 版本 >= 5。
- BasicSR_JIT 有最高的优先级。即使在安装的时候已经成功编译了 C++ 编译算子,若在运行代码指令中设置了 BasicSR_JIT=True,此时代码仍旧会即时加载 C++ 编译算子。
- 在安装的时候,不能设置 BasicSR_JIT=True。
4常见安装问题
Q1:windows下是否可以使用
经过验证,Windows 下可以通过上述的两种安装方式安装 BasicSR。如果需要使用 CUDA,需要指定 CUDA 路径。 另外需要注意的是如果需要在 Windows 环境中使用环境变量,需要使用以下方式:
set BASICSR_EXT=True
由于 BasicSR 项目是在 Linux (Ubuntu) 环境下进行开发的,因此推荐在 Linux 环境下基于BasicSR 进行项目的开发。
Q2:BASICSR_EXT 和 BASICSR_JIT在什么环境下才能执行
如果在加入 BASICSR_EXT 和 BASICSR_JIT 环境变量之后运行报错,此时需要检查 gcc 版本。BasicSR 在已被验证在 gcc5 ∼ gcc7 版本下可以成功编译 C++ 编译算子。
Q3:安装路径混淆的问题
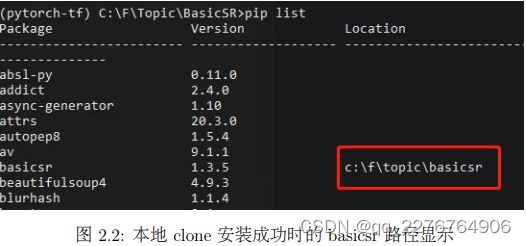
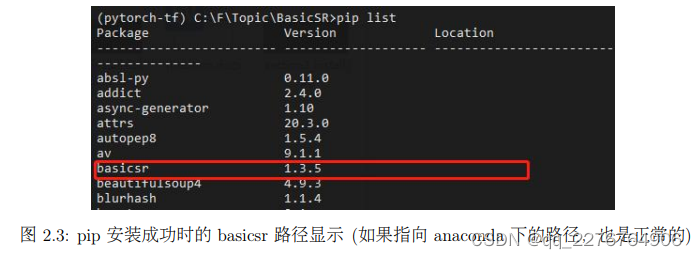
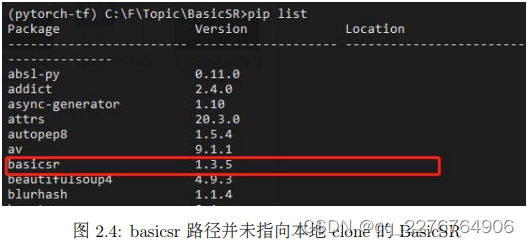
很多问题都是由于安装路径混淆,其主要原因是本地 clone 代码和 pip 安装包两个方式被同时执行。
具体而言,如果先通过 pip 安装了 BasicSR,随后又使用本地 clone 的方式进行安装,此时项目中调用的 BasicSR 路径还是 pip 安装的 BasicSR;反过来,如果先使用本地 clone 的方式进行安装,随后又使用 pip 安装,此时项目中调用的 BasicSR 路径还是本地 clone 下的BasicSR (分别如图2.4和图2.5所示)。
a) 通过本地 clone 安装成功的时候,此时使用 pip list 命令查看 basicsr 路径:
b) 通过 pip 安装成功的时候,此时使用 pip list 命令查看 basicsr 路径:
c) 如果先通过 pip 安装,随后通过本地 clone 安装,此时使用 pip list 命令查看 basicsr路径:
d) 如果先通过本地 clone 安装,随后通过 pip 安装,通过 pip list 命令查看此时 basicsr路径:
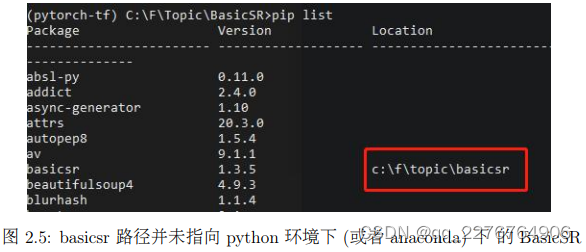
对于上述的两种错误情况 (图2.4和图2.5),此时正常的解决方式为:先将安装的 BasicSR 进行卸载,随后再根据项目的需要重新选择一种方式安装 BasicSR。
pip uninstall basicsr
Q4:如何更新最新版本的BasicSR
a) 对于通过本地 clone 进行安装的方式,需要将本地的 BasicSR 项目代码与远端的BasicSR 项目代码进行同步。
b) 对于通过 pip 安装的方式,
pip install basicsr --upgrade
Q5:如何解决运行代码时出现的version问题?
有时候在运行代码的时候,会出现类似于如下的问题:
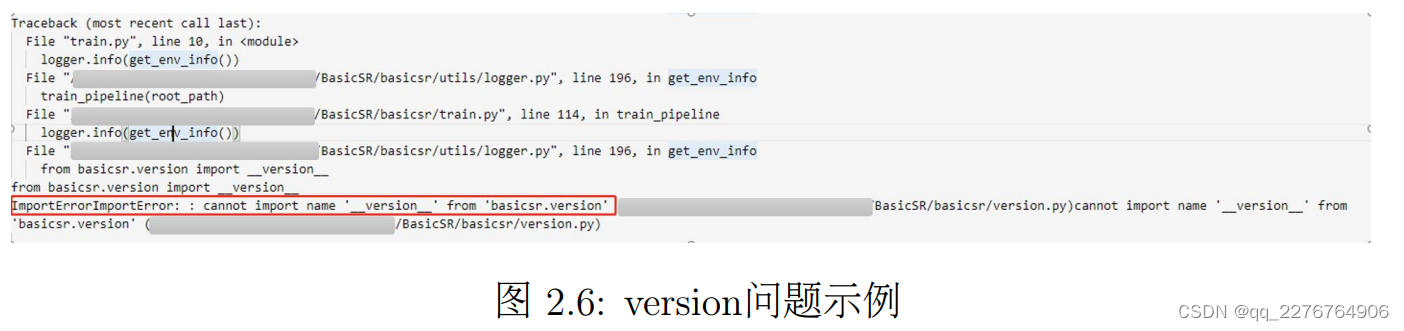
此时,可以尝试:
a) 重新运行安装 BasicSR 的指令。
b) 将涉及到 version 的代码进行注释。
如果小伙伴们在安装过程中还遇到其它的问题,可以在我们的 BasicSR 微信群、 QQ 群 (可从 BasicSR 项目主页中获取)、github 的 issue 上面进行反馈,我们会持续将一些常见的问题更新到这个小节当中。
四、入门
本部分为BasicSR方法的入门部分,主要色剂的有目录解读,训练、测试和快速推理的流程。这个部分的主要目的是希望读者能够快速入门BasicSR整体框架。
1、目录解读
此节介绍了BasicSR仓库的基本结构,根据仓库的目录层级,这一部分为仓库的整体概览。主要包括了算法的核心文件和代码基础配置文件。具体的的目录结构如下:
其中,
红色 表示和跑实验直接相关的文件,即我们平时打交道最多的文件;
蓝色 表示其他与 BasicSR 强相关的代码文件;
黑色 表示配置文件。
BasicSR根目录


basicsr
在 BasicSR 仓库中, basicsr 文件夹存放的是核心代码。主要为深度学习模型常用的代码文件,比如网络结构,损失函数和数据加载等,具体目录如下:
其中,
红色 表示我们在开发中主要修改的文件。
蓝色 表示其他与 BasicSR 强相关的代码文件;
黑色 表示配置文件。

scripts
由于在算法设计和开发中,需要用到一些脚本,比如数据的预处理、指标计算等,相关的文件位于scripts,目录如下:

2、训练流程
在对目录结构有了初步的了解之后就可以进行训练了。我们希望 BasicSR 即方便使用,又清晰易懂,降低使用者的门槛。但随着 BasicSR 代码库逐渐抽象和复杂起来,很多刚接触的同学不知道程序入口在哪里,数据、模型和网络是在哪里定义的,流程又是在哪里控制的,那么我们就通过一个例子简要地说一下。
本节的目的是希望能够初步地让读者了解到训练的基本流程和代码逻辑流,具体的细节我们会采用引用的方式来供读者查阅。 我们强烈建议你跟着下面的流程和实际代码,走一遍训练的流程。这样可以对 BasicSR 整体的框架有一个全面理解。训练流程是从 basicsr/train.py 开始的。
2.1 代码的入口和训练的准备工作
我们以训练超分辨率模型 MSRResNet 为例,首先需要在终端输入命令来开始训练:
python basicsr/train.py -opt options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml
其中 options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml 为 yml 配置文件,主要设置实验相关的配置参数。参数具体说明见第(五)章,3.2.1节,训练配置文件例子。
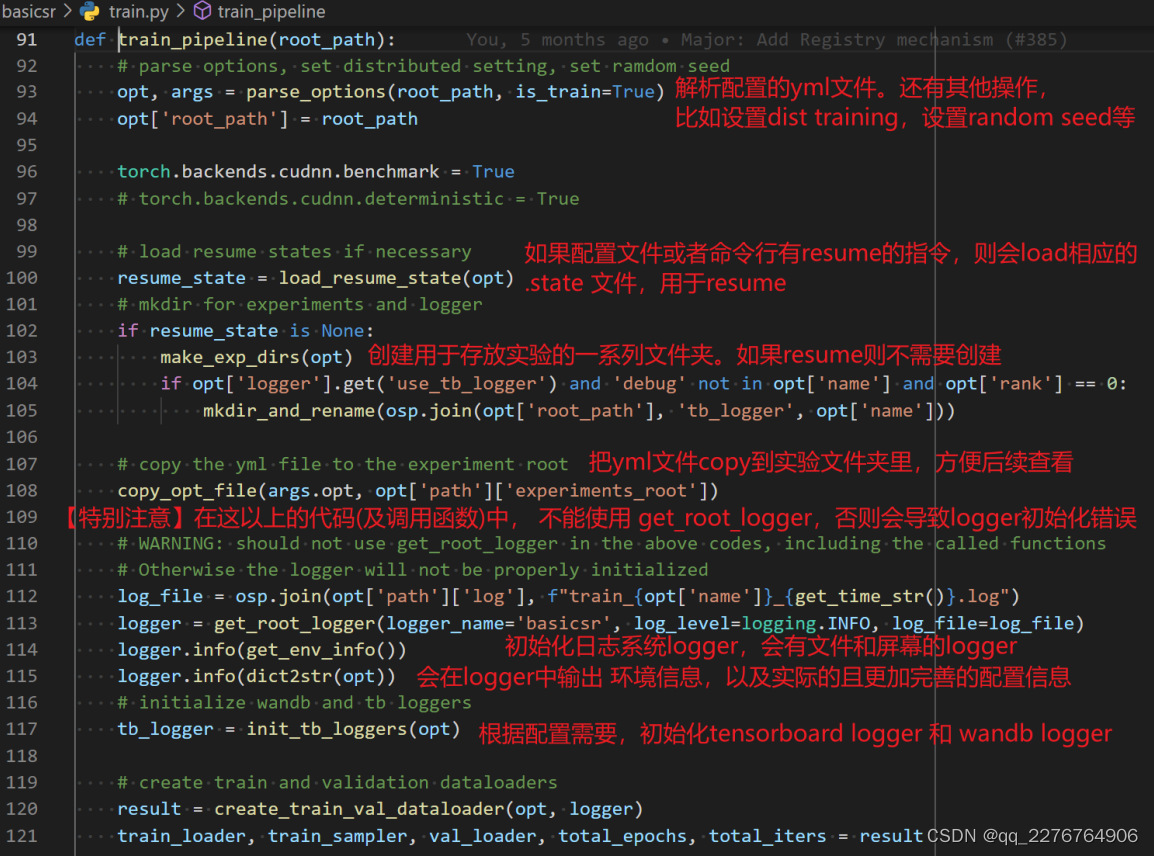
它从 basicsr/train.py 的 train_pipeline 函数作为入口:

root_path 作为参数传进去:
这里为什么要把root_path 作为参数传进去呢?是因为,当我们把 basicsr 作为 package 使用的时候,需要根据当前的目录路径来创建文件,否则程序会错误地使用 basicsr package 所在位置的目录了。
train_pipeline 函数会做一些基础的事,比如:
- 解析配置文件 option file,即 yml 文件
- 设置 distributed training 的相关选项,设置 random seed 等
- 如果有 resume,需要 load 相应的状态
- 创建相关文件夹,拷贝配置的 yml 文件
- 合理初始化日志系统 logger
我们对着代码一一讲解,函数train_pipeline的基础准备工作:
(具体的子函数,对着代码点进去查看,此处只重点说几点)
1、我们在命令行中的参数输入,在哪里完成解析即argparse在哪里?
答:在parse_options这个函数中。
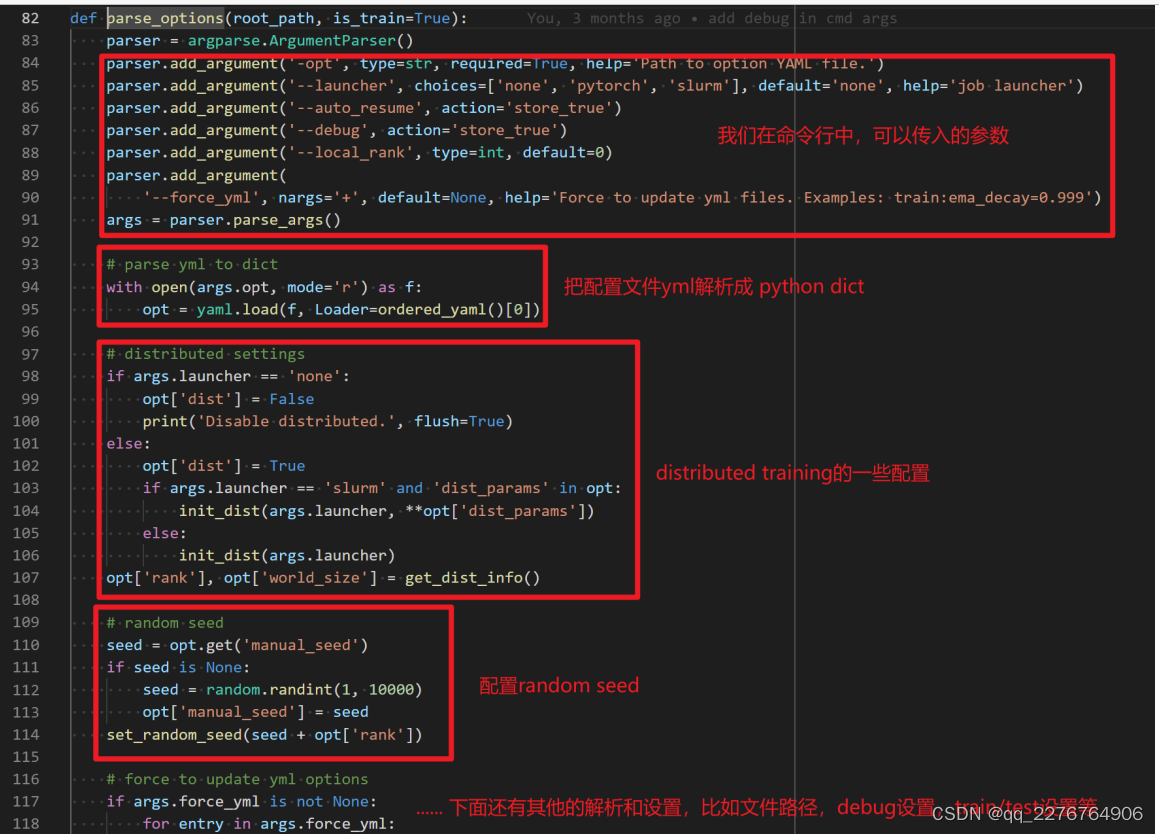
以下对命令行的参数大致讲解一下:
a) -opt,配置文件的路径,一般采用这个命令配置训练或者测试的 yml 文件。
b) – laucher,用于指定 distibuted training 的,比如 pytorch 或者 slurm。默认是 none,即单卡非 distributed training。
c) – auto_resume,是否自动 resume,即自动查找最近的 checkpoint ,然后 resume。
d) – debug,能够快速帮助 debug。
e) – local_rank,这个不用管,是 distributed training 中程序自动会传入。
f) – force_yml,方便在命令行中修改 yml 中的配置文件。
2、为每个实验创建的文件夹
每个实验都会在experiments目录中创建一个以配置文件中的name为名字的文件夹,里面的文件如下图所示。【log的内容参见第(五)章中第9节,日志系统 logger】。在实验文件夹中有把配置文件也copy一份,还会额外添加copy的时间和运行使用的具体命令,方便事后检查和复现。

2.2 Dataset 和Model的创建
当训练准备工作结束后,我们接下来就要看dataset和model的创建过程了。他主要包括:
- 训练和 validation 的 data loader 创建,下面会展开
- model 的创建,下面会展开
- logger 的初始化,这块详见【详见第五章第9节:日志系统(logger)】的相关内容
- 还有 dataset prefetch 的内容,这块【详见第五章第4.4节:Dataset prefetch】的相关内容
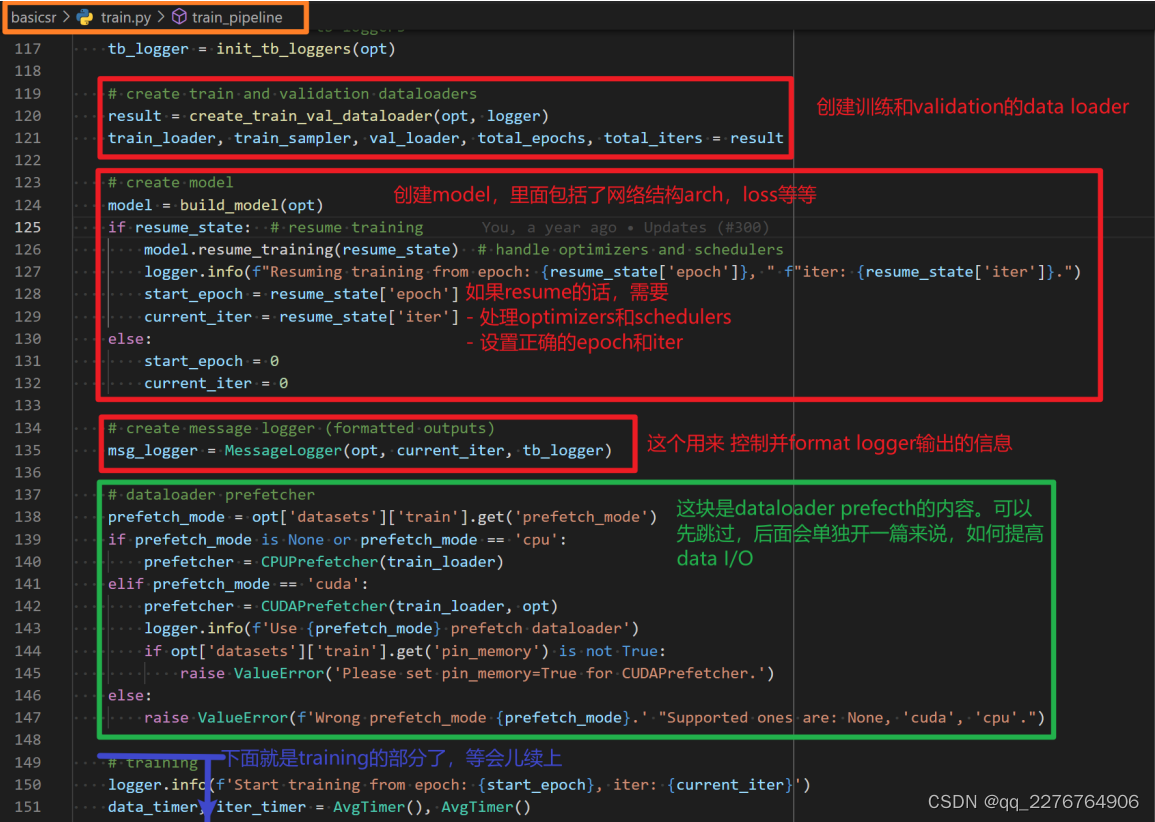
这里我们着重讲解两块, dataloader 的创建和 model 的创建。
dataloader的创建
首先我们看调用的 create_train_val_dataloader 函数 ,里面主要就是两个函数, build_dataset 和build_dataloader 。无论是 train 还是 val 的dataloader 都是这两个函数构建的。 创建 dataloder 要靠build_dataloader,其中又要用到dataset 。而 dataset 是由 build_dataset 创建的。 dataloder 其实大家都是共用的。当我们说要新写一个dataloader ,其实写的是 dataset 。 build_dataloader 和 build_dataset 都是定义在 basicsr/data/init.py 文件里。
build_dataset 和 build_dataloader:
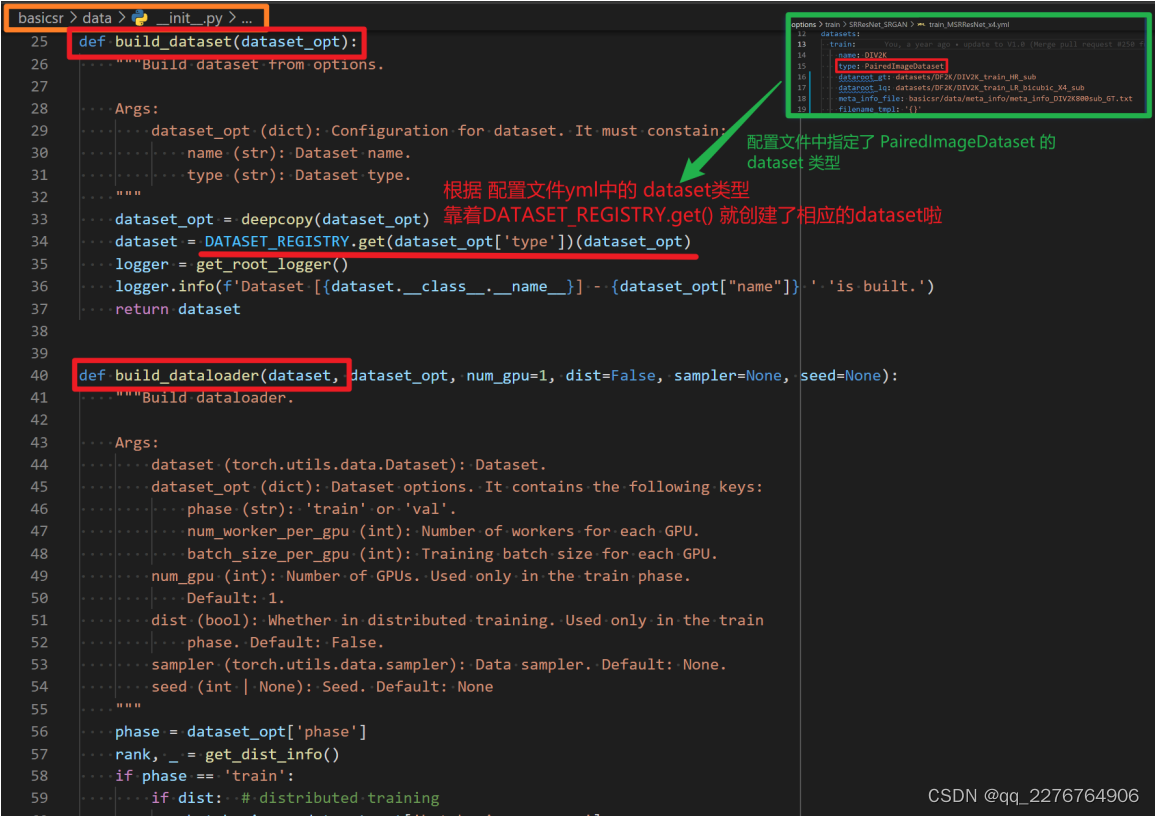
初始化train和valid的dataloader:
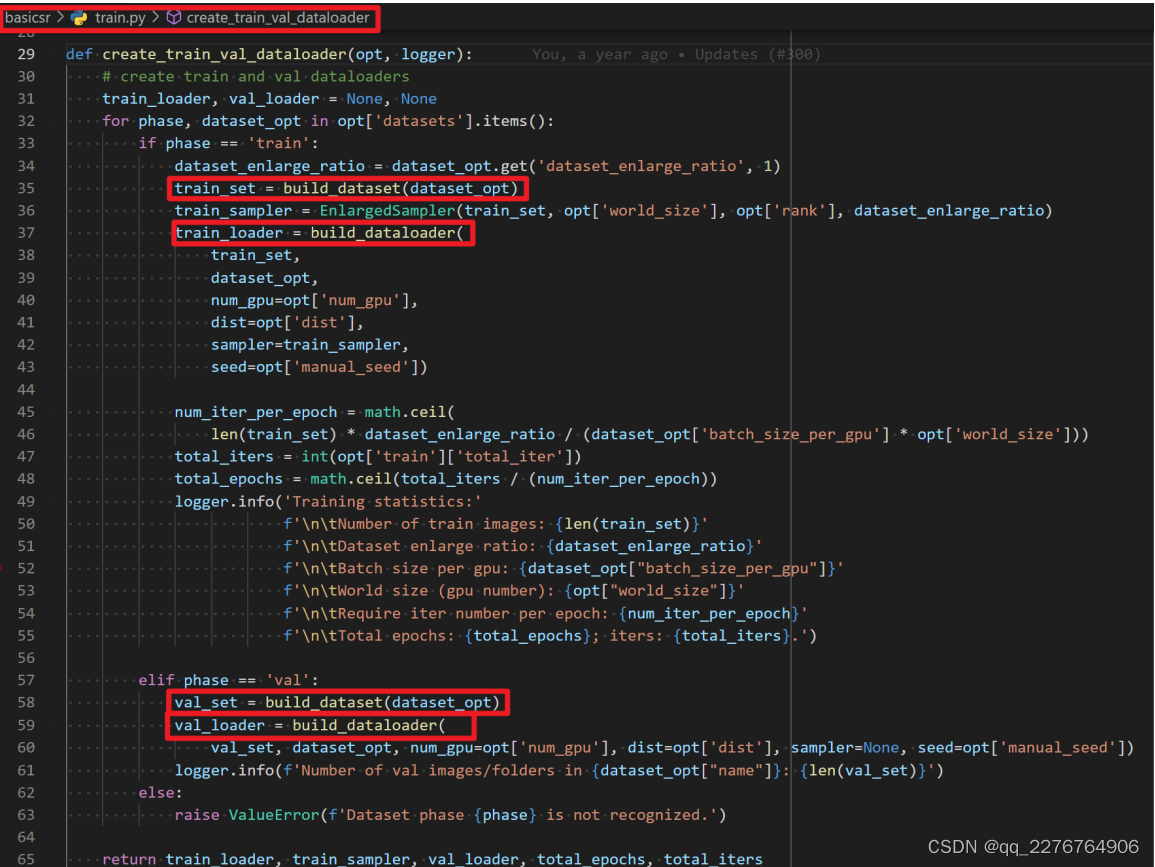
这里面,build_dataset 是核心。它会根据配置文件 yml 中的 dataset 类型,比 如 在 我 们 这 个 例 子 中 就 是PairedImageDataset , 创 建 相 应 的 实 例 。 核 心 的 代 码是:DATASET_REGISTRY.get()。这里是如何做到根据“类名”动态创建实例的,请参见【第五章第2节:动态实例化与register注册机制】。(实例就是由类 class 创建的,具体运行的对象)。这里我们只要理解,通过这一句调用,就可以创建相应的实例了。 build_dataloader 是比较容易理解的。它
根据传入的 dataset 和其他在 yml 中的参数,构建 dataloader。
model的创建
model的创建是通过build_model这个函数,定义在basicsr/models/init.py文件里。
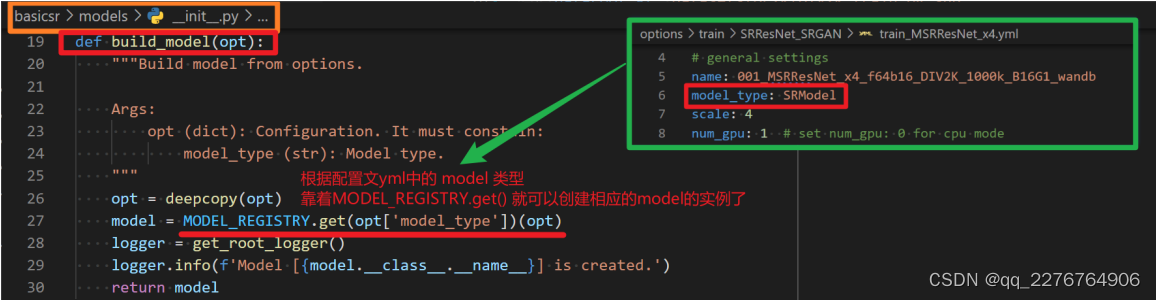
build_model 会根据配置文件 yml 中的 model 类型,比如在我们这个例子中就是 SRModel,创建相应的实例。接下来我们再具体地看看 SRModel 这个实例的创建过程吧,以便更好地理解一个模型中做了什么操作。 让我们进入 SRModel 这个类。
SR model类的定义:
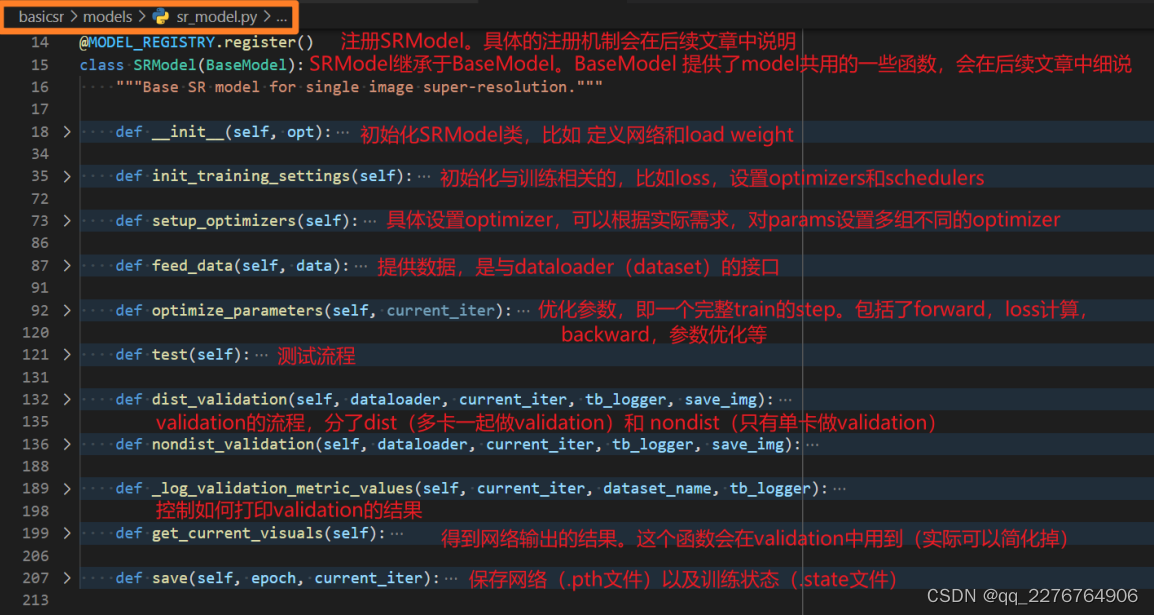
在这里我们主要关注以下几个方面,关于model具体的介绍,参见【第五章第5节:模型(model)】
a) network 的创建
b) loss 的创建
c) optimize_parameters ,即一个 iteration 的 train step
d) metric 的使用
下面我们分别简略说明,希望大家可以抓住大致的脉络。
a) network 的 创 建 一 般 是 在 model 的 init() 函 数 里 面
通 过 调 用build_network() 实现的。 init() 函数般还会加载预训练模型,并初始化训练相关的设置。如下图所示。
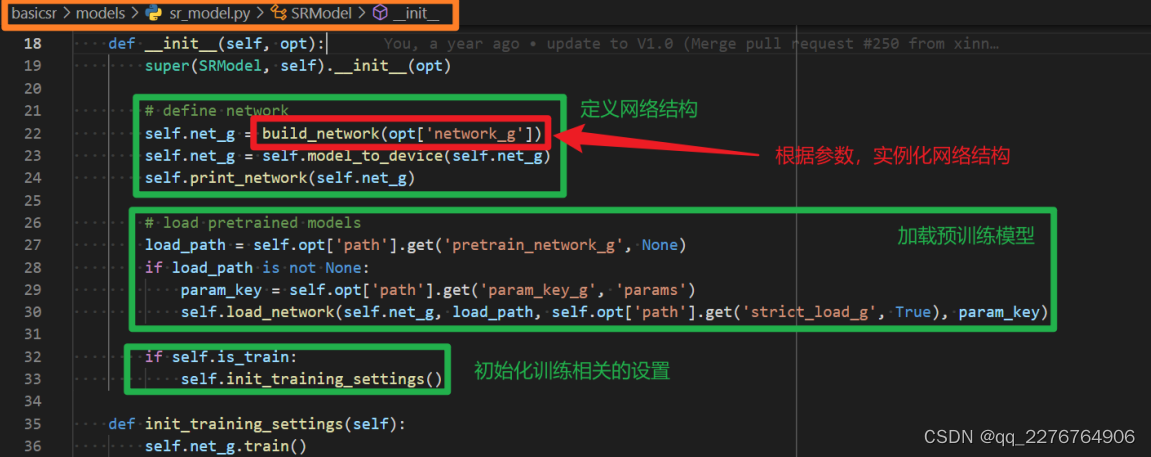
build_network会根据配置文件yml中国的network类型,比如在我们这个例子中就是MSRResNet,从ARCH_REGISTRY创建相应的实例。如下图所示,根据yml配置文件中的网络结构类型,创建相应的实例。

b) loss 的创建一般是在 model 的 init_training_settings() 函数里面。
其他先不关注,我们主要关注 build_loss 这个函数。loss 就是通过调用 build_loss() 实现的。如果有多个loss ,则会多次调用 build_loss() ,创建多个 loss 实例。如下图所示。
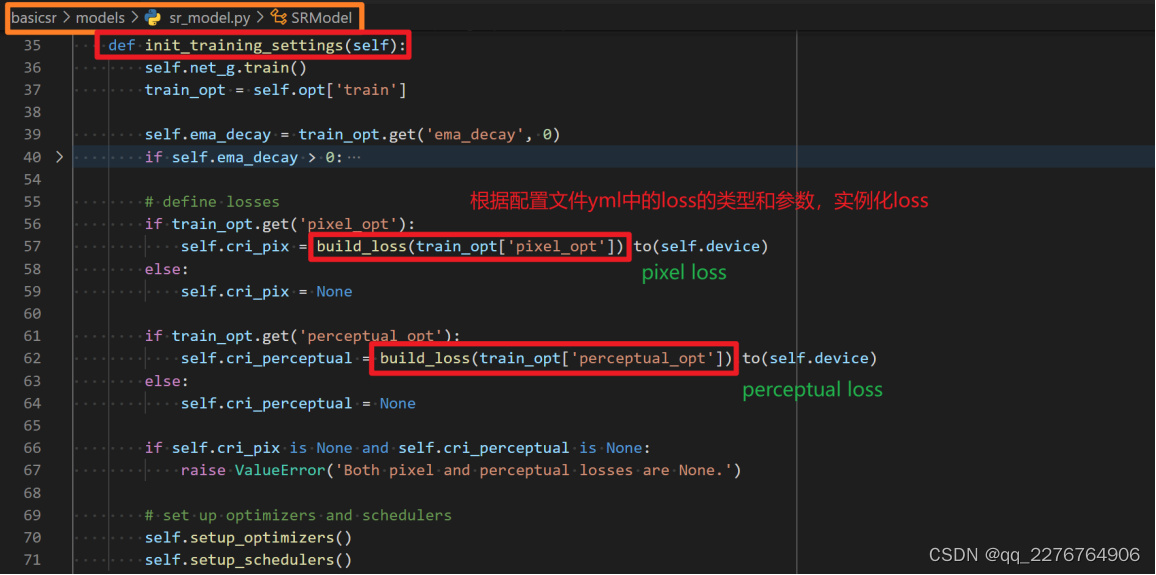
build_loss会根据配置文件yml中的loss类型,比如在我们这个例子中就是L1Loss,从LOSS_REGISTRY中创建相应的实例。如下图所示:
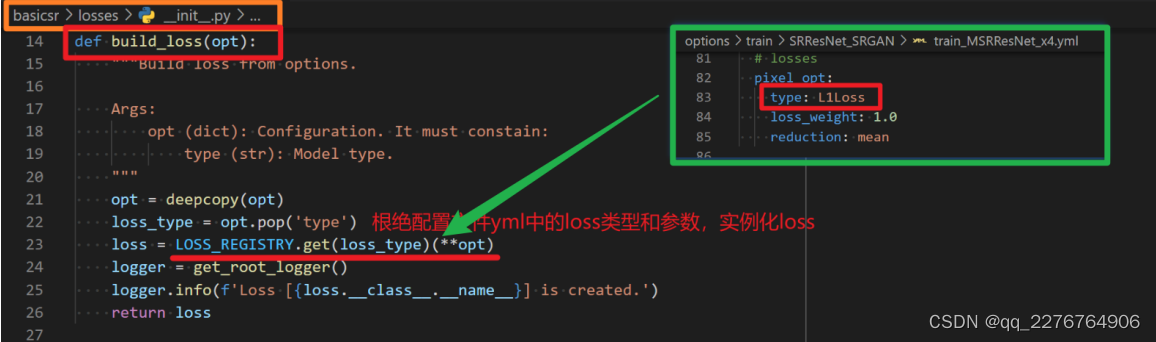
c) optimize_parameter 函数,即一个 iteration 下的 train step 。
这个函数里面主要包含了 network forward ,loss 计算,backward 和优化器的更新。如下图所示,描述了一个iteration的参数优化过程。
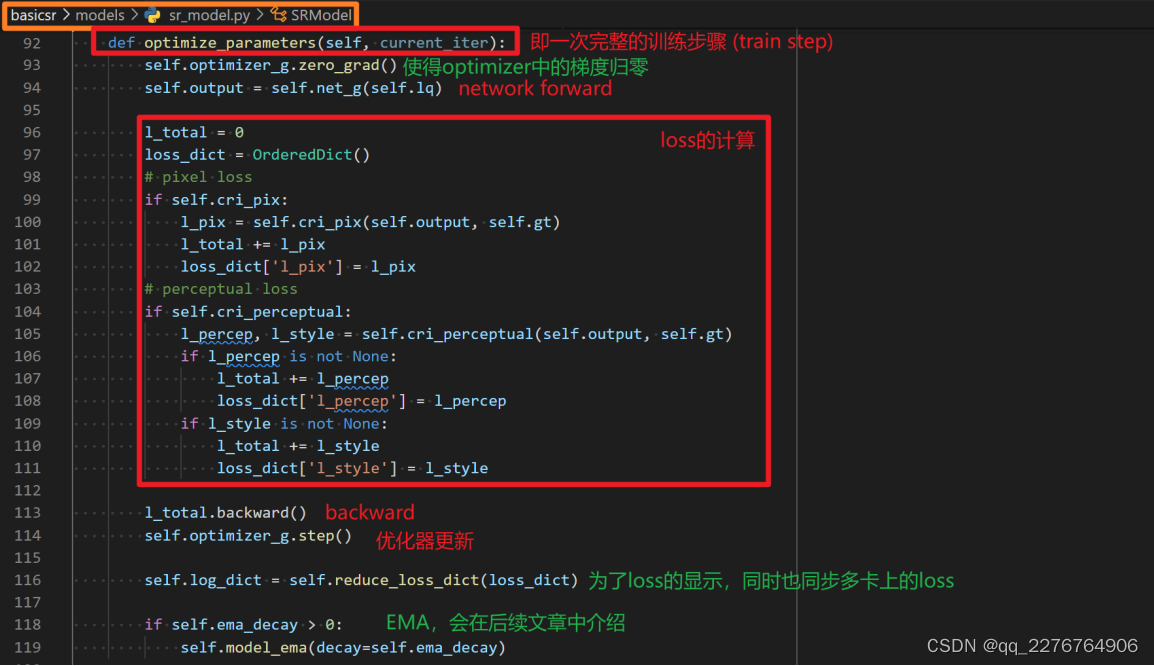
d) metric 的使用主要是在 validation 里面
我们来看在训练 MSRResNet 中调用的nondist_validation 函数。其中核心是在 calculate_metric 这个函数,它会根据配置文
件 yml 中的 metrics 配置,调用相应的函数。如下图所示。calculate_metric 具体定义在 basicsr/metrics/init() 文件中,它也是使用了 REGISTRY 机制:METRIC_REGISTRY。它会根据配置文件 yml 中的 metric 类型,比如
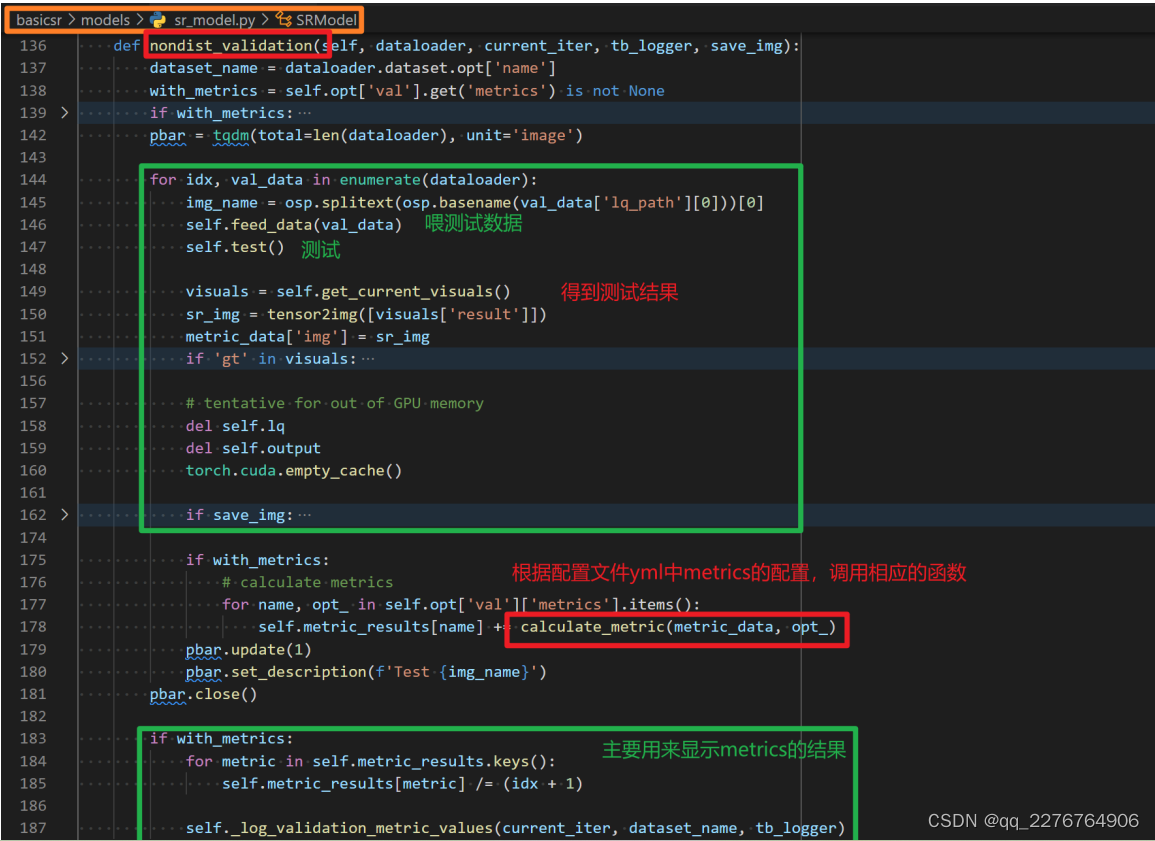
在这个例子中就有两个 metrics:PSNR 和 SSIM ,调用相应的函数。注意和前面DATASET, ARCH, MODEL, LOSS 的 REGISTRY 不同,这里返回的是函数调用,而其他返回的是类的实例。如下图所示。
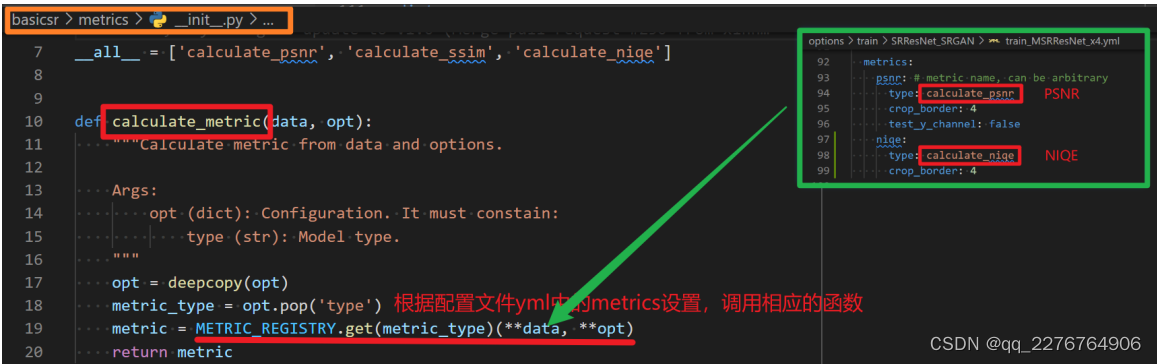
到此,我们已经看到了 dataset (data loader) 的创建,以及 model 的创建。model 的创建包含了 network architecture 和 loss 的创建,一次完整的训练流程以及 validation 中用到的 metric 的计算。
2.3训练过程
当以上这些部件都被创建后,就进入训练过程了。它就是一个循环的过程,不断地喂数据,然后不断执行训练步骤。完整训练过程如下图所示:
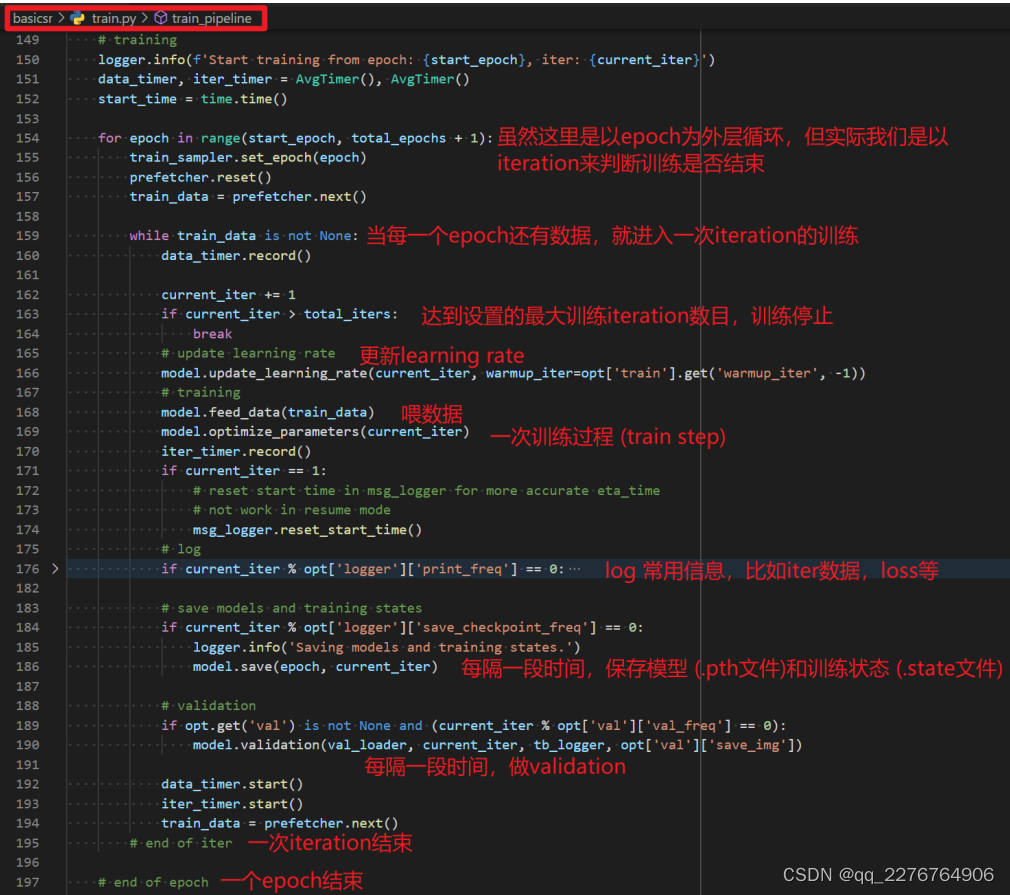
上面的for循环结束,整个训练过程也就结束了。
2.4测试流程
这里的测试流程指的是,使用 basicsr/test.py 和 配置文件 yml 来测试模型,以得到测试结果,同时输出指标结果的过程。
测试流程是从 basicsr/test.py 开始的。
在测试阶段,很多流程 (比如 dataset 和 data loader 的创建、model 的创建、网络结构的创建)都和训练流程是共用的。因此我们在这里主要解释测试流程中特有的部分。
测试阶段,我们需要在终端输入命令来开始训练。
python basicsr/test.py -opt options/test/SRResNet_SRGAN/test_MSRResNet_x4.yml
其中 options/test/SRResNet_SRGAN/test_MSRResNet_x4.yml 为 yml 配置文件,主要设置实验相关的配置参数。【参数具体说明参见第五章第3.2.2节:测试配置文件例子】
下面是 basicsr/test.py 主要的测试流程 test_pipeline 函数,相比于 basicsr/train.py 着实简了很多。
def test_pipeline(root_path):
# 解析 yml 文件,加载配置参数
opt, _ = parse_options(root_path, is_train=False)
...
# 新建 logger 并初始化,打印基础信息
make_exp_dirs(opt)
log_file = osp.join(opt['path']['log'],f"test_{opt['name']}_{get_time_str()}.log")
logger = get_root_logger(logger_name='basicsr', log_level=logging.INFO,log_file=log_file)
logger.info(get_env_info())
logger.info(dict2str(opt))
# 创建测试集和 dataloader。和训练过程一样,调用 build_dataset 和build_dataloader
test_loaders = []
for _, dataset_opt in sorted(opt['datasets'].items()):
test_set = build_dataset(dataset_opt)
test_loader = build_dataloader(
test_set, dataset_opt, num_gpu=opt['num_gpu'], dist=opt['dist'],sampler=None, seed=opt['manual_seed'])
logger.info(f"Number of test images in {dataset_opt['name']}:{len(test_set)}")
test_loaders.append(test_loader)
# 创建模型,和训练过程一样,调用 build_model
model = build_model(opt)
# 测试多个测试集,调用的是 model 里面的 validation 函数
for test_loader in test_loaders:
test_set_name = test_loader.dataset.opt['name']
logger.info(f'Testing {test_set_name}...')
model.validation(test_loader, current_iter=opt['name'],tb_logger=None, save_img=opt['val']['save_img'])
可以看到,整个测试过程和训练过程大部分都是重合的,非常简洁。
2.5推理流程
这里的推理流程指的是,使用 inference 目录下的代码,快速方便地测试结果。 和测试流程 的目的是不同的:
- 测试流程针对学术数据集,希望能够同时测试多个测试集,同时能够输出相应的指标
- 推理流程针对实际使用场景,提供demo。它往往只需要一个输出结果,而不需要有 GT(Ground-Truth) 数据,也不需要有指标输出。
简而言之,推理流程方便用户快速得到一个 demo 的结果。因此我们希望 inference 的文件,能够尽可能少的依赖 BasicSR 框架,即可以自己读数据,创建模型。我们只需要使用 BasicSR 中的网络结构即可 (而网络结构在 BasicSR 中又是相对独立的)。这样,使用者便可以根据 inference文件,快速将所需要的模型“摘”出来,放到自己的应用场景里面去。
在快速推理阶段,我们只需要在终端输入命令:
python inference/inference_esrgan.py --input input_path --output out_path
basicsr/inference/inference_esrgan.py 提供了一个非常简洁且具有代表性的例子,相信你可以
轻而易举地看懂。
五、代码主体结构
在本章节中,我们将对BasicSR代码框架进行一个整体介绍,主要包括以下内容:整体框架、注册器机制、配置问题、数据、模型、网络结构、损失函数、算子、日志系统等。通过阅读本章,将对BasicSR有进一步的认识,理解其模块之间的相互关系以及模块内部的核心工作原理。但不对具体函数和代码做具体介绍。如果需要具体函数和代码介绍,请查阅BasicSR的在线API文档API在线文档
1、整体框架
对于深度学习的算法框架,其核心的组成部分包括:数据、模型、损失函数、训练。BasicSR框架也是大致根据以上部分撰写的。下图概括了BasicSR的整体组成框架:
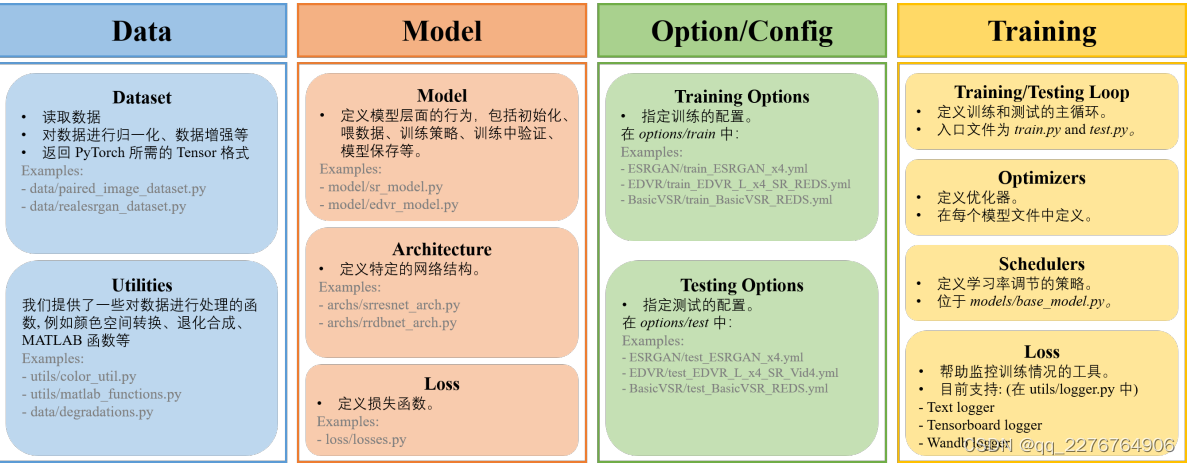
数据 (Data):
这个部分主要定义了 Dataset 和 Data Loader 文件, 放在了 basicsr/data 目录下。Dataset 用于读取和预处理数据,包括图读取、归一化 (normalization)、数据增强 (augmentation) 以及封装为 PyTorch Tensor 等。同时,我们也提供了一些辅助函数,帮助使用者自定义自己的数据预处理功能,例如图像色彩空间转换、常用 MATLAB 函数的Python 版本、常用的图像退化模型 (degradation model) 等。
模型 (Model):
在 basicsr/models 目录下,我们提供了常用的模型文件。这些模型文件主要用于定义网络结构与初始化、输入输出数据、一次 forward 的训练过程、保存加载模型等。在 basicsr/archs 目录下,我们提供了常用的网络结构模型文件,包括 SRResNet、ESRGAN、RCAN、SwinIR、EDVR、BasicVSR 等。在 basicsr/losses 文件夹中,我们提供了常用的损失函数,例如 L1/L2 loss、perceptual loss、GAN loss 等。
配置 (Option):
配置文件放到 option 目录下。我们提供了常用模型的训练和测试配置文件。我们使用 YAML 来作为配置文件的语言。修改这些 yml 文件可以简易地调整训练过程中的各种超参数。
训练 (Training):
这一部分主要涉及训练的策略和记录训练日志。basicsr/train.py 和 basicsr/test.py 是启动模型训练和测试的入口文件,其中定义了训练和测试的 main loop。常见优化器 (optimizer) 的定义可以在 models/base_model.py 文件中的 get_optimizer 函数中找到。学习率的调度策略在 models/base_model.py 文件中的 setup_schedulers 函数中定
义。为了方便追踪记录训练的过程,我们提供了相应的 logger 工具,支持直接 print 到屏幕、Tensorboard、Wandb等多种方式,具体代码可以在 basicsr/utils/logger.py 中找到。
详细的代码接口文档可以在 http://basicsr.readthedocs.io 查询
2、动态实例化与register注册机制
2.1 register注册机制
首先,来看我们的目的:当我们新写了类 (Class) 或函数时,我们希望可直接在配置文件中指定,然后程序会根据配置文件的类名或函数名,自动查找并实例化。 以开发新的网络结构为例,我们会做以下几件事:
- 写具体的网络结构,它往往是一个Class,并且往往是一个单独的文件
- 在配置文件中会指定我们使用哪一个网络结构,往往是通过 Class name 指定
- 在训练过程的某一个地方,程序会根据配置文件指定的 Class name,自动实例化相关的类
这里说的 REGISTER 注册机制就是来更简洁地实现上面的第三个步骤的。因为其能够根据配置文件动态地实例化所需要的类或函数,因此这个过程被称为动态实例化 (Dynamic Instantiation)。
BasicSR 的 Register 注册机制参考了 Facebook Research 的 fvcore 仓库的函数,定义了 Registry类。详细代码可查看 basicsr/utils/registry.py。它主要有两个函数:register() 和 get()。
class Registry():
""" The registry that provides name -> object mapping, to support third-party users' custom modules. """
def __init__(self, name):
self._name = name
self._obj_map = {}
def _do_register(self, name, obj, suffix=None):
...
self._obj_map[name] = obj
def register(self, obj=None, suffix=None):
# register() 函数主要用来注册一个实现的类或函数
if obj is None:
# used as a decorator
def deco(func_or_class):
name = func_or_class.__name__
self._do_register(name, func_or_class, suffix)
return func_or_class
return deco
# used as a function call
name = obj.__name__
self._do_register(name, obj, suffix)
def get(self, name, suffix='basicsr'):
# get() 函数主要用来根据配置文件中的类名或函数名来查找对应的实例
ret = self._obj_map.get(name)
if ret is None:
ret = self._obj_map.get(name + '_' + suffix)
...
return ret
2.1.1 如何注册新的类?
在BasicSR中,定义了五个REGISTER,相关定义在basicsr/utils/registry.py中:
DATASET_REGISTRY = Registry('dataset')
ARCH_REGISTRY = Registry('arch')
MODEL_REGISTRY = Registry('model')
LOSS_REGISTRY = Registry('loss')
METRIC_REGISTRY = Registry('metric')
需要注册的时候,我们
- import 相关的注册器,比如 ARCH_REGISTRY
- 使用 Python 装饰器,即在类/函数前面加上 @ARCH_REGISTRY.register()
以网络结构 RRDBNet 为例:
from basicsr.utils.registry import ARCH_REGISTRY # import 相关的注册器
from .arch_util import default_init_weights, make_layer, pixel_unshuffle
@ARCH_REGISTRY.register() # 使用 Python 装饰器
class RRDBNet(nn.Module):
def __init__(self):
super(RRDBNet, self).__init__()
...
这样RRDBNet这个类就被注册上了
2.1.2 如何使用已注册的类
当我需要使用的时候,只需要在配置文件中配置相关代码会自动实例化所需要的类。
还是以使用RRDBNet网络结构为例。我们在配置文件中指定了网络结构的类型为RRDBNet。
# network structures
network_g:
type: RRDBNet
num_in_ch: 3
num_out_ch: 3
num_feat: 64
num_block: 23
模型文件basicr/models/sr_models.py中的函数build_network(opt[‘network_g’])便会根据配置文件build网络结构
class SRModel(BaseModel):
"""Base SR model for single image super-resolution."""
def __init__(self, opt):
super(SRModel, self).__init__(opt)
# define network
self.net_g = build_network(opt['network_g']) # 调用建构网络结构的函数
self.net_g = self.model_to_device(self.net_g)
self.print_network(self.net_g)
而 build_network 函数就会从 ARCH_REGISTRY 中找到已经被注册的 RRDBNet 进行实例化。 build_network 函数所在位置 basicsr/archs/init.py
def build_network(opt):
opt = deepcopy(opt)
network_type = opt.pop('type')
net = ARCH_REGISTRY.get(network_type)(**opt) # 实例化的核心函数。从ARCH_REGISTRY 找到已被注册的类进行实例化
logger = get_root_logger()
logger.info(f'Network [{net.__class__.__name__}] is created.')
return net
2.2自动扫描并import注册的类、函数
上面讲了 REGISTER 注册机制,但还有一个问题:这个类/函数还需要被 Python 程序感知到。目前的类/函数只是在一个文件中写了,但是 Python 程序并没有 import 进来。
这个问题的解决方法:一般是在 init.py 文件中写 import 语句,比如在 mmediting 中定义了网络结构后,还需要在 sr_backbones/init.py 中添加这样的语句:
from .basicvsr_net import BasicVSRNet
from .edsr import EDSR
from .edvr_net import EDVRNet
from .rrdb_net import RRDBNet
from .sr_resnet import MSRResNet
它需要在 init.py 中把写好的网络结构显示地 import 进来。 但这样很麻烦:每写一个新的网络结构,我们就要去修改 init.py,很多时候容易忘记。 最早开发 mmediting 的时候就感觉这个很繁琐。 本着偷懒的原则,在 BasicSR 中就找了一个省事的办法。
但我们新建一个文件,就以 _arch.py 结尾。通过扫描特定文件的方式来进行自动 import。比如,对于网络结构,我们在 basicsr/archs/init.py 中定义了:
# automatically scan and import arch modules for registry
# scan all the files under the 'archs' folder and collect files ending with '_arch.py'
arch_folder = osp.dirname(osp.abspath(__file__))
arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
# import all the arch modules
_arch_modules = [importlib.import_module(f'basicsr.archs.{file_name}') for file_name in arch_filenames]
我们可以看到,程序会自动扫描以 _arch.py 的文件,然后 import 相关文件。这样就把所有注册的网络结构类都 import 进去啦。
类似的,DATASET,ARCH,MODEL,LOSS 都在相关的 init.py 文件中定义了扫描并自动 import 的操作。
总结一下,当我们在新开发网络结构时 (其他模块也类似),只要做两件事,修改两个文件就好了。BasicSR 背后的动态实例化和 REGISTRY 机制会帮你完成剩下的事。
- 写 一 个 单 独 的 网 络 结 构 文 件 (以 _arch.py 结 尾)。 在 写 好 的 Class 前 加 上@ARCH_REGISTRY.register() 装饰器
- 在配置文件中指定使用哪一个网络结构,即上面的 Class name
2.2.1 文件后缀名的约定
| Model | Register | File Suffix | Example |
|---|---|---|---|
| data | DATASET_REGISTRY | _dataset.py | basicsr/data/paired_image_dataset.py |
| arch | ARCH_REGISTRY | _arch.py | basicsr/archs/srresnet_arch.py |
| model | MODEL_REGISTRY | _model.py | basicsr/models/sr_model.py |
| loss | LOSS_REGISTRY | _loss | basicsr/losses/gan_loss.py |
注意:
- 上面的文件后缀只用在需要的文件中,其他文件命名尽量避免使用以上的后缀
- 注册的类名或函数名不能重复,否则会报错
meitric稍有特殊
我们定义了 METRIC_REGISTRY,它在用法上和其他类一样,但是它是根据函数名来调用相对应的函数。
因为 metric 我们相对改动少,所以我们没有采用自动扫描文件再 import 的方式,而是保留
了在basicsr/metrics/init.py 中 import 的方式
2.2.2 避免类名、函数名出现重名问题
Register 机制会自动检测出重名的类/函数,然后抛出错误:An object named xxx was already registered in yyy registry!。 这是特意设计的,以减少 bug 。因为如果重名的类,在实例化的时候,就不能确定程序到底实例化的是哪一个类。
但是有有一种情况下,Register 的重名检查机制反而会掣肘开发。
当 我 们 在 BasicSR 里 面 定 义 了 一 个 类 , 比 如 basicsr/data/realesrgan_dataset.py 中 的RealESRGANDataset 类。 而在 Real-ESRGAN GitHub repo 中,我们是把 basicsr 当作一个 package 来使用,然后又定义了一遍 RealESRGANDataset 类。这个时候,原来 BasicSR 代码中的类和后面开发的 Real-ESRGAN 代码中的类就有重名了。
这个情况下,我们约定在 BasicSR 对应的类中的注册器中,传入 basicsr 的参数,以指示这个类是 BasicSR 中定义的,以示区分。 其中这里的 basicsr 是关键词,注意使用其他词是不会被识别的。
@DATASET_REGISTRY.register(suffix='basicsr') # 我们在类名中传入后缀 suffix,以指示这是在 BasicSR repo 中定义的
class RealESRGANDataset(data.Dataset):
""" Dataset used for Real-ESRGAN model:
"""
...
这个具体在 basicsr/utils/registry.py 的代码如下:
def get(self, name, suffix='basicsr'):
ret = self._obj_map.get(name)
if ret is None:
ret = self._obj_map.get(name + '_' + suffix)
print(f'Name {name} is not found, use name: {name}_{suffix}!')
if ret is None:
raise KeyError(f"No object named '{name}' found in '{self._name}' registry!")
return ret
它实现的逻辑如下:
- 如果 get 函数指定了 suffix,则会优先找带有 suffix 的类/函数
- 一般我们的 get 函数都不会指定 suffix。这样的情况,程序优先找自己实现的 (比如 Real-ESRGAN 代码库中的) 类/函数
- 如果在自己实现的类/函数中没有找到,则会找 BasicSR 官方库中的实现的相同名字的类
3、配置(option)
在这个章节,我们先简单介绍一下实验命名的约定,然后通过例子介绍训练和测试的配置文件。
3.1 实验命名与debug模式
3.1.1 实验命名
我们推荐对实验名字进行有意义的命名,方便后续的实验以及进行多组实验对比。
我们以 001_MSRResNet_x4_f64b16_DIV2K_1000k_B16G1_wandb 为例:
• 001: 我们一般给实验进行数字打头的标号, 方便进行实验管理
• MSRResNet: 模型名称, 这里指代 Modified SRResNet
• x4_f64b16: 重要配置参数, 这里表示放大4倍; 中间feature通道数是64, 使用了16个Residual
Block
• DIV2K: 训练数据集是 DIV2K
• 1000k: 训练了1000K iterations
• B16G1: Batch size 为16, 使用一卡 GPU 训练
• wandb: 使用了 wandb, 训练过程上传到了 wandb 云服务器
3.1.2 Debug模式
正式训练之前,你可以用 debug 模式检查是否正常运行。在 debug 模式下:
• 程序会在每次 iteration 下都打印日志,并且经过8次 iterations 后,便会进入 validation 阶段。这样可以快速方便地查看代码是否可以正常运行,而不用实际训练。毕竟实际训练可能很慢,等半天后,发现程序崩溃了,而原因是 validation 中有 bug
• 在 debug 模式中,并不会使用 tensorboard logger 和 wandb logger,以保证日志文件的简洁性
如何进入 debug 模式?
方式 1. 在命令行最后加入 ‘–debug’。比如:
python basicsr/train.py -opt options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml --debug
方式 2. 在配置文件 yml 文件的 name 中添加 ‘debug’ 字符。只要在实验名字中有 ‘debug’ 字样, 则会进入 debug 模式。
3.2配置文件简要说明
在 BasicSR 中我们使用 YAML 来作为配置文件的语言。
训练的配置文件在 options/train 中,测试的配置文件在 options/test 中。 通过 option 配置文件,我们可以设置实验名、选择模型、指定 GPU、指定数据路径、选择网络结构、配置训练策略等。
配置文件的解析在 basicsr/utils/options.py 的 parse_options 中实现。这个过程将 YAML 文件解析成 Python 的 dict 类型,并根据需要做出调整 (比如 debug 模式下的特殊配置等)。读者可以在【第四章(入门)2.1节:代码的入口和训练的准备工作中】和对应代码中找到解释和具体实现。
3.2.1训练配置文件例子
下面,作者以 train_MSRResNet_x4.yml 为例,简单说明训练配置文件的每个部分。作者先把配置文件贴出来,在后面附上解释。然后在说明框内会列举相关的要点。为方便说明,整个配置文件会被分散成不同的板块来讲解。
通用配置:
• 在配置文件的最开始,会有简单的说明,以及默认的运行命令。运行命令的auso_resume 表示自动从断点接着训练
• 常见模型 (Model) 的定义在 models 目录中。
• num_gpu:0 表示 使用CPU,auto 表示自动从可用 GPU 块数推断
# Modified SRResNet w/o BN from:
# Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
# ----------- Commands for running
# ----------- Single GPU with auto_resume
# PYTHONPATH="./:${PYTHONPATH}" CUDA_VISIBLE_DEVICES=0 python basicsr/train.py -opt options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml --auto_resume
# general settings - 这块为通用设置
name: 001_MSRResNet_x4_f64b16_DIV2K_1000k_B16G1_wandb # 实验名称, 若实验名字中有debug字样, 则会进入debug模式
model_type: SRModel # 使用的 model 类型
scale: 4 # 输出比输入的倍数, 在SR中是放大倍数; 若有些任务没有这个配置, 则写1
num_gpu: 1 # 指定使用的 GPU 卡数
manual_seed: 0 # 指定随机种子
数据读取相关配置:
• 常见数据 (dataset) 的定义在 basicsr/data 目录中。
• data loader 定义在 basicsr/data/init.py 文件中
• meta_info_file:细节请参看第八章:数据准备
• io_backend:读取数据的方式,细节请参看第八章:数据准备
• dataset_enlarge_ratio:它代表了手工扩大 dataset 的倍率。例如,如果训练数据集有15张图,设置 dataset_enlarge_ratio为100,那么程序会重复读取这些图片100次,这样一个 epoch 下来,便会读取1500张图 (事实上是重复读的)。这个方法经常用来加速 data loader, 因为在有的机器上,一个 epoch 结束,会重启进程,导致拖慢训练
• prefetch_mode:,默认为 None,即 ∼。cpu 表示使用 CPU prefetcher。cuda 表示使用 CUDA prefetcher。它会多占用一些GPU显存. 注意: 这个模式下, 一定要设置 pin_memory=True。详【情参见本章第4.4节:Dataset prefetch说明】
# dataset and data loader settings
datasets: # 这块是 dataset 的配置
train: # 训练 dataset 的配置
name: DIV2K # 自定义的数据集名称
type: PairedImageDataset # 读取数据的 Dataset 类
# 以下属性是灵活的, 可在相应类的说明文档中获得。新加的数据集可根据需要添加
dataroot_gt: datasets/DF2K/DIV2K_train_HR_sub # GT (Ground-Truth) 图像的文件夹路径
dataroot_lq: datasets/DF2K/DIV2K_train_LR_bicubic_X4_sub # LQ(Low-Quality) 输入图像的文件夹路径
meta_info_file: basicsr/data/meta_info/meta_info_DIV2K800sub_GT.txt # 预先生成的 meta_info 文件
# (for lmdb)
# dataroot_gt: datasets/DIV2K/DIV2K_train_HR_sub.lmdb
# dataroot_lq: datasets/DIV2K/DIV2K_train_LR_bicubic_X4_sub.lmdb
filename_tmpl: '{}' # 文件名字模板, 一般LQ文件会有类似 '_x4' 这样的文件后缀, 这个就是来处理GT和LQ文件后缀不匹配的问题的
io_backend: # IO 读取的 backend
type: disk # disk 表示直接从硬盘读取
# (for lmdb)
# type: lmdb
gt_size: 128 # 训练阶段裁剪 (crop) 的GT图像的尺寸大小,即训练的 label 大小
use_hflip: true # 是否开启水平方向图像增强 (随机水平翻转图像)
use_rot: true # 是否开启旋转图像增强 (随机旋转图像)
# data loader - 下面这块是 data loader 的设置
num_worker_per_gpu: 6 # 每一个 GPU 的 data loader 读取进程数目
batch_size_per_gpu: 16 # 每块 GPU 上的 batch size
dataset_enlarge_ratio: 100 # 放大 dataset 的长度倍数 (默认为1)。可以扩大一个 epoch 所需 iterations
prefetch_mode: ~ # 预先读取数据的方式
validation 配置:
• 这里使用了两个 validation sets,它们通过关键字 val,val_2 来区分。如果有更多的 validation sets,可以通过 val_3, val_4 … 来区分。
val: # validation 数据集的设置
name: Set5 # 数据集名称
type: PairedImageDataset # 数据集的类型
# 以下属性是灵活的, 类似训练数据集
dataroot_gt: datasets/Set5/GTmod12
dataroot_lq: datasets/Set5/LRbicx4
io_backend:
type: disk
val_2: # 另外一个 validation 数据集
name: Set14
type: PairedImageDataset
dataroot_gt: datasets/Set14/GTmod12
dataroot_lq: datasets/Set14/LRbicx4
io_backend:
type: disk
网络结构相关配置:
• 常见网络结构 (arch) 的定义在 archs 目录下。 【详细说明参见本章第6节,网络结构】
• 如果模型需要使用多个网络,我们一般以 network_ 打头来命名。比如 我们需要一个discriminator,命名为 network_d
# network structures - 网络结构的设置
network_g: # 网络 g 的设置
type: MSRResNet # 网络结构 (Architecture) 的类型
# 以下属性是灵活且特定的, 可在相应类的说明文档中获得
num_in_ch: 3 # 模型输入的图像通道数
num_out_ch: 3 # 模型输出的图像通道数
num_feat: 64 # 模型内部的 feature map 通道数
num_block: 16 # 模型内部基础模块的堆叠数
upscale: 4 # 上采样倍数
模型路径相关配置:
- resume_state设置后, 会覆盖 pretrain_network_g 的设定
- 对于resume,【更多信息可以参考本章第5.4.1节:如何Resume】
# path
path: # 以下为路径和与训练模型、重启训练的设置
pretrain_network_g: ~ # 预训练模型的路径, 需要以 pth 结尾的模型
param_key_g: params # 读取的预训练的参数 key。若需要使用 EMA 模型,需要改成params_ema
strict_load_g: true # 是否严格地根据参数名称一一对应 load 模型参数。如果选择false,那么模型对于找不到的参数,会随机初始化;如果选择 true,假如存在不对应的参数,会报错提示
resume_state: ~ # 重启训练的 state 路径, 在experiments/exp_name/training_states 目录下
训练策略相关配置:
训练策略相关的配置主要分为优化器,学习率调度器,总共训练 iterations,损失函数等。
- 关于 EMA,【请参考本章第.5.6节:EMA介绍】
- optim_g,后缀 _g 表示和 network_g 中的 _g 一一对应起来
- lr: !!float 2e-4 中的 !!float 是 YAML 语言语法,表示以 float 解释后面的数字,不然就会以文字来进行解释
- 常 见 优 化 器 (optimizer) 的 定 义 可 以 在 models/base_model.py 文 件 中 的get_optimizer 函数中找到
- 学习率的调度策略在 models/base_model.py 文件中的 setup_schedulers 函数中定义
- 常用的损失函数可以在 losses 目录中定义
# training settings
train: # 这块是训练策略相关的配置
ema_decay: 0.999 # EMA 更新权重
optim_g: # 这块是优化器的配置
type: Adam # 选择优化器类型,例如 Adam
# 以下属性是灵活的, 根据不同优化器有不同的设置
lr: !!float 2e-4 # 初始学习率
weight_decay: 0 # 权重衰退参数
betas: [0.9, 0.99] # Adam 优化器的 beta1 和 beta2
scheduler: # 这块是学习率调度器的配置
type: CosineAnnealingRestartLR # 选择学习率更新策略
# 以下属性是灵活的, 根据学习率 Scheduler 的不同有不同的设置
periods: [250000, 250000, 250000, 250000] # Cosine Annealing 的更新周期
restart_weights: [1, 1, 1, 1] # Cosine Annealing 每次 Restart 的权重
eta_min: !!float 1e-7 # 学习率衰退到的最小值
total_iter: 1000000 # 总共进行的训练迭代次数
warmup_iter: -1 # warm up 的迭代次数, 如是-1, 表示没有 warm up
# losses - 这块是损失函数的设置
pixel_opt: # loss 名字,这里表示 pixel-wise loss 的 options
type: L1Loss # 选择 loss 函数,例如 L1Loss
# 以下属性是灵活的, 根据不同损失函数有不同的设置
loss_weight: 1.0 # 指定 loss 的权重
reduction: mean # loss reduction 方式
validation 相关配置:
- 关于 metrics 的介绍,【请参考第六章5:指标】
- 指标在 basicsr/metrics 目录中定义
- BasicSR 支持在 validation 时使用多个指标,只需要在配置文件中添加配置,比如上面的 psnr 和 niqe
# validation settings
val: # 这块是 validation 的配置
val_freq: !!float 5e3 # validation 频率, 每隔 5000 iterations 做一次validation
save_img: false # 否需要在 validation 的时候保存图片
metrics: # 这块是 validation 中使用的指标的配置
psnr: # metric 名字, 这个名字可以是任意的
type: calculate_psnr # 选择指标类型
# 以下属性是灵活的, 根据不同 metric 有不同的设置
crop_border: 4 # 计算指标时 crop 图像边界像素范围 (不纳入计算范围)
test_y_channel: false # 是否转成在 Y(CbCr) 空间上计算
better: higher # 该指标是越高越好,还是越低越好。选择 higher 或者lower,默认为 higher
niqe: # 这是在 validation 中使用的另外一个指标
type: calculate_niqe
crop_border: 4
better: lower # the lower, the better
训练日志相关配置:
- 关于 wandb,目前 wandb 只是同步 tensorboard 的内容, 因此要使用 wandb, 必须也同时使用 tensorboard。更多关于 wandb,【参见本章第9.3节:日志系统】
# logging settings
logger: # 这块是 logging 的配置
print_freq: 100 # 多少次迭代打印一次训练信息
save_checkpoint_freq: !!float 5e3 # 多少次迭代保存一次模型权重和训练状态
use_tb_logger: true # 是否使用 tensorboard logger
wandb: # 是否使用 wandb logger
project: ~ # wandb 的 project名字。 默认是 None, 即不使用 wandb
resume_id: ~ # 如果是 resume, 可以输入上次的 wandb id, 则 log 可以接起来
# dist training settings
dist_params: # distributed training 的设置, 目前只在 Slurm 训练下才需要
backend: nccl
port: 2950
至此,我们对于训练的配置文件有了一个初步的理解了。
3.2.2测试配置文件例子
作者以 test_MSRResNet_x4.yml 为例,简单说明测试配置文件的每个部分。作者先把配置文件贴出来,在后面附上解释。然后在说明框内会列举相关的要点。为方便说明,整个配置文件会被分散成不同的板块来讲解。 由于测试配置文件和训练配置文件很类似,我们将简略地进行讲解。
# ----------- Commands for running
# ----------- Single GPU
# PYTHONPATH="./:${PYTHONPATH}" CUDA_VISIBLE_DEVICES=0 python basicsr/test.py -opt options/test/SRResNet_SRGAN/test_MSRResNet_x4.yml
# general settings
name: 001_MSRResNet_x4_f64b16_DIV2K_1000k_B16G1_wandb # 实验名称
model_type: SRModel # 使用的 model 类型
scale: 4 # 输出比输入的倍数, 在SR中是放大倍数; 若有些任务没有这个配置, 则写1
num_gpu: 1 # 测试卡数
manual_seed: 0 # 指定随机种子
# test dataset settings
datasets:
test_1: # 测试数据集的设置, 后缀1表示第一个测试集
name: Set5 # 数据集的名称
type: PairedImageDataset # 读取数据的 Dataset 类
# GT 和输入 LQ 的根目录
dataroot_gt: datasets/Set5/GTmod12
dataroot_lq: datasets/Set5/LRbicx4
io_backend: # IO 读取的 backend
type: disk # disk 表示直接从硬盘读取
test_2: # 测试数据集的设置, 后缀2表示第二个测试集
name: Set14
type: PairedImageDataset
dataroot_gt: datasets/Set14/GTmod12
dataroot_lq: datasets/Set14/LRbicx4
io_backend:
type: disk
# network structures - 网络结构的设置
network_g: # 网络 g 的设置
type: MSRResNet # 网络结构 (Architecture) 的类型
# 以下是 MSRResNet 的参数设置
num_in_ch: 3
num_out_ch: 3
num_feat: 64
num_block: 16
upscale: 4
# path
path:
pretrain_network_g: experiments/001_..._wandb/models/net_g_1000000.pth # 预训练模型的路径, 需要以 pth 结尾的模型
param_key_g: params # 读取的预训练的参数 key。若需要使用 EMA 模型,需要改成params_ema
strict_load_g: true # 加载预训练模型时, 是否需要网络参数的名称严格对应
# validation settings - 以下为Validation (也是测试)的设置
val:
save_img: true # 是否需要在测试的时候保存图片
suffix: ~ # 对保存的图片添加后缀,如果是 None, 则使用 exp name
metrics: # 测试时候使用的 metric
psnr: # metric 名字, 这个名字可以是任意的
type: calculate_psnr # 选择指标类型
# 以下属性是灵活的, 根据不同 metric 有不同的设置
crop_border: 4 # 计算指标时 crop 图像边界像素范围 (不纳入计算范围)
test_y_channel: false # 是否转成在 Y(CbCr) 空间上计算
better: higher # the higher, the better. Default: higher
ssim: # 另外一个指标
type: calculate_ssim
crop_border: 4
test_y_channel: false
better: higher
注意:
- 如果模型训练的时候开启了 EMA,则在测试的时候需要指定 param_key_g 为params_ema。否则会出现测试和训练过程中 validation 不匹配的问题。
至此,我们对于测试的配置文件有了一个初步的理解了。
3.3命令行修改配置
BasicSR 使用 yml 文件进行配置。我们也推荐这样的方式,因为这样可以记录并跟踪每一个实验的配置。 但我们也希望在仅仅修改了一个小配置的情况下 (比如修改 random seed),不需要麻烦地新建并修改 yml 配置文件。它可以使用原先的 yml 配置文件,而在命令行中对配置做出修改。
BasicSR 提供了一个简便的命令行参数 ‘–force_yml’,在命令行中它的用法如下:
- ‘–force_yml’ 后面接如下的字符串,每一个字符串修改一个配置,如果有多个配置需要修改,以空格隔开多个字符串
- 字符串采用格式:‘train:ema_decay=0.999’。等号 (=) 前后分别表示 key 和 value。如果有层级结构,使用冒号 (😃 来区分
- 修改之后记得检查打印的日志是否符合预期
示例:
有如下的配置 yml 文件,我们希望修改:1) random seed 为 1; 2) ema_decay 为0.5; 3) 名字中体现配置。
# general settings
name: 001_MSRResNet_x4_f64b16_DIV2K_1000k_B16G1_wandb
model_type: SRModel
scale: 4
manual_seed: 0
...
train:
ema_decay: 0.999
那么,我们的命令行就变成了:
python basicsr/train.py -opt options/train/SRResNet_SRGAN/train_MSRResNet_x4.yml --force_yml manual_seed=1 train:ema_decay=0.5 name=001_MSRResNet_x4_f64b16_DIV2K_1000k_B16G1_rand1_ema_decay0.5
4、数据(Data Loader 和 Dataset)
这一小节我们主要介绍 basicsr/data 目录下相关的功能和函数。
在模型训练的过程中,我们需要不断地喂给网络模型数据。这个过程是通过 data loader 实现的。而每个 data loader 中又会把硬盘上的数据处理成训练所需的格式,这个过程是由不同的数据集决定的,PyTorch 里面叫做 dataset。我们一般说的 data loader,其实更多的是指 dataset 处理数据的细节。
- dataloader:开启多个线程读取并处理数据,定义在 basicsr/data/init.py 中
- dataset:这是 dataloader 调用的,它把数据 (比如 PNG 图像) 转成模型、网络能够接收的输入 (往往是 PyTorch Tensor 类型), 它涉及到的流程:
a) 读取数据
b) 对数据做变换 transforms。比如 crop,数据增强等
c) 转换成 PyTorch Tensor
4.1 basic/data目录介绍
basicsr/data 下面主要的文件有:

meta_info的txt文件是可以根据自己的需要创建的。BasicSR提供了一些约定的meta_info文件,【具体参见第八章第3节:meta文件介绍】
我们新建数据集的dataset的时候,需要以_dataset.py结尾,这样才能够被程序自动扫描import
更多的dataset参见代码或者在线API文档
4.2 Dataloader和Dataset的创建
dataloader 的创建是在 basicsr/data/init.py 文件中的 build_dataloader 函数。这里不赘述,请参见代码。
dataset 的创建是通过 Register 机制实现的。 具体可以参考:
- 【第五章第2节:动态实例化与register注册机制】说明了 Register 机制是如何根据配置文件中的类型,来自动实例化
类的 - 【第四章第2.2节:dataset和model的创建】通过一个完整的例子,说明了其中 dataset 的创建过程
4.3Dataset示例讲解
下面,我们以PairedImageDataset为例,大致讲解Dataset文件的内容。PairedImageDataset常被用在图像复原(超分辨率、去噪、去模糊)任务中。它会从两个目录中读取成对的训练数据对。
@DATASET_REGISTRY.register()
class PairedImageDataset(data.Dataset):
def __init__(self, opt): # 这里是初始化函数
super(PairedImageDataset, self).__init__()
self.opt = opt
# file client (io backend) 这是初始化 file client 部分
self.file_client = None
self.io_backend_opt = opt['io_backend']
# 赋值常用的配置参数
self.mean = opt['mean'] if 'mean' in opt else None
self.std = opt['std'] if 'std' in opt else None
数据读取格式: 在 option 文件中可以指定数据读取方式 (opt[’io_backend’])。
我们支持三种读取数据的模式:
- 直接从 lmdb 格式的文件中读取
- 若提供了 meta_info 文件,则直接从该文件中列出的文件路径读取数据
- 输入文件目录,代码会自动扫描该目录中的文件,然后读取
详见参见 File Client 说明【第八章第4节:File Client介绍】。
# 这块内容是根据 GT 和 LQ 的图像目录读取出相应的文件列表
self.gt_folder, self.lq_folder = opt['dataroot_gt'],opt['dataroot_lq']
if 'filename_tmpl' in opt:
self.filename_tmpl = opt['filename_tmpl']
else:
self.filename_tmpl = '{}'
# 如果输入是 lmdb,则使用 paired_paths_from_lmdb 函数
if self.io_backend_opt['type'] == 'lmdb':
self.io_backend_opt['db_paths'] = [self.lq_folder,self.gt_folder]
self.io_backend_opt['client_keys'] = ['lq', 'gt']
self.paths = paired_paths_from_lmdb([self.lq_folder,self.gt_folder], ['lq', 'gt'])
# 如果输入是 meta_info_file 方式,则使用paired_paths_from_meta_info_file 函数
elif 'meta_info_file' in self.opt and self.opt['meta_info_file'] is not None:
self.paths = paired_paths_from_meta_info_file([self.lq_folder,self.gt_folder], ['lq', 'gt'],self.opt['meta_info_file'],self.filename_tmpl)
# 如果是一般文件目录方式,则使用 paired_paths_from_folder 函数
else:
self.paths = paired_paths_from_folder([self.lq_folder,self.gt_folder], ['lq', 'gt'], self.filename_tmpl)
# 以上这些函数都已经实现在 basicsr/data/data_util.py 文件中
下面是一个 dataset 中重要的函数 getitem, 它定义了从输入图像,经过变换、数据增强等变为 PyTorch Tensor的过程。
def __getitem__(self, index):
# 初始化 file client
if self.file_client is None:
self.file_client = FileClient(self.io_backend_opt.pop('type'),**self.io_backend_opt)
scale = self.opt['scale']
# 下面这个代码块是从存储介质中读取相应的数据到内存的过程
# Load gt and lq images. Dimension order: HWC; channel order: BGR;
# image range: [0, 1], float32.
gt_path = self.paths[index]['gt_path']
img_bytes = self.file_client.get(gt_path, 'gt')
img_gt = imfrombytes(img_bytes, float32=True)
lq_path = self.paths[index]['lq_path']
img_bytes = self.file_client.get(lq_path, 'lq')
img_lq = imfrombytes(img_bytes, float32=True)
# 下面这个代码块是做数据增强,在这里主要是成对数据的随机裁剪和旋转、翻转
# augmentation for training
if self.opt['phase'] == 'train':
gt_size = self.opt['gt_size']
# random crop
img_gt, img_lq = paired_random_crop(img_gt, img_lq, gt_size,scale, gt_path)
# flip, rotation
img_gt, img_lq = augment([img_gt, img_lq], self.opt['use_hflip'],self.opt['use_rot'])
# 如果有需要的话,会做色彩空间转换
# color space transform
if 'color' in self.opt and self.opt['color'] == 'y':
img_gt = rgb2ycbcbgr2ycbcrr(img_gt, y_only=True)[..., None]
img_lq = bgr2ycbcr(img_lq, y_only=True)[..., None]
# 以下代码块将 numpy 数据格式转换成 PyTorch 所需的 Tensor 格式,并根据需要作归一化
# BGR to RGB, HWC to CHW, numpy to tensor
img_gt, img_lq = img2tensor([img_gt, img_lq], bgr2rgb=True,float32=True)
# normalize
if self.mean is not None or self.std is not None:
normalize(img_lq, self.mean, self.std, inplace=True)
normalize(img_gt, self.mean, self.std, inplace=True)
# 最后,我们返回一个字典,包括输入的 LQ 图像,作为标签的 GT 图像,以及他们的路径
return {'lq': img_lq, 'gt': img_gt, 'lq_path': lq_path, 'gt_path':gt_path}
4.4 Dataset prefetch说明
下面介绍数据预读取prefetch机制。为了加速数据读取的进程,作者提供了数据预读取机制,具体的实现代码详见data/prefetch_dataloader.py。
目前作者提供了三种数据预读取方式,可以在训练配置文件中进行设置。
- None 模式。默认不使用。如果使用了 LMDB 或者 IO 开销不大,可以不使用 prefetch。
prefetch_mode: ~
- cuda 模式。使用 CUDA prefetcher,具体介绍可以参考 NVIDIA/apex。这个模式会多占用一些 GPU 显存。注意,如果使用这个模型,一定要设置 pin_memory=True。
prefetch_mode: cuda
pin_memory: true
- cpu 模式。使用 CPU prefetcher,具体介绍可以参考 IgorSusmelj/pytorch-styleguide。这个加速效果可能不明显。
prefetch_mode: cpu
num_prefetch_queue: 1 # 1 by default
5、模型(Model)
5.1 basic/models目录介绍
basicsr/models 下面主要的文件有:

我们新建 model 的时候,需要以 _model.py 结尾,这样才能够被程序自动扫描 import。
为增加模型间的复用, 很多模型都是继承的, 以下为主要模型的的继承关系。通过继承,可以精简代码开发,复用功能函数。 注意这里之列了一些基本的,更多的 model 请参见代码或者在线API 文档 。
5.2 Model的创建
model 的创建是通过 Register 机制实现的。 具体可以参考:
- 【第五章第2节:动态实例化与register注册机制】说明了 Register 机制是如何根据配置文件中的类型,来自动实例化类的
- 【第四章第2.2节:dataset和model的创建】通过一个完整的例子,说明了其中 model 的创建过程
model 创建完后,网络结构、损失函数等都是在 model 的初始化过程中创建的。【第四章第2.2节:dataset和model的创建】也提供了一个概览。
5.3Base Model 和Model 示例讲解
5.3.1 Base Model
Base Model 是所有模型的基类,定义一些共同操作。 这里做一个简要的介绍。
class BaseModel():
def __init__(self, opt):
# 初始化
...
def feed_data(self, data):
# 喂数据,需要在继承的类里面具体实现
pass
def optimize_parameters(self):
# 优化参数,这里特指一次完整的训练过程,即 train_step
pass
def save(self, epoch, current_iter):
# 保存训练模型和训练状态
pass
def validation(self, dataloader, current_iter, tb_logger,save_img=False):
# validation 函数
...
def model_ema(self, decay=0.999):
# 进行模型 EMA
...
def model_to_device(self, net):
# 将模型放到 GPU 上
...
def get_optimizer(self, optim_type, params, lr, **kwargs):
# 根据 yml 配置文件获取优化器
...
def setup_schedulers(self):
# 根据 yml 配置文件获取学习率的策略方式
...
@master_only
def print_network(self, net):
# 打印网络,包括总参数
...
def update_learning_rate(self, current_iter, warmup_iter=-1):
# 更新学习率
...
def get_current_learning_rate(self):
# 获取现在的学习率
...
@master_only
def save_network(self, net, net_label, current_iter, param_key='params'):
# 保存网络参数
...
def load_network(self, net, load_path, strict=True, param_key='params'):
# 加载网络参数
...
@master_only
def save_training_state(self, epoch, current_iter):
# 保存网络训练状态
...
def resume_training(self, resume_state):
# 断点恢复训练
...
def reduce_loss_dict(self, loss_dict):
# 在多卡训练时,平均多个 GPU 的损失函数
...
说明:
- 对于没有实现的函数 (内容是 pass),需要在继承的类中实现函数的功能,即它们是必须要重新实现的
- @master_only 表示在多卡下,只在主卡上进行调用
5.3.2 SRModel 简单说明
我们在这里简单说明 SRModel 类,它是图像超分辨率模型的基础类,定义了基础的单张图像超分辨率模型。 下面的代码主要为了说明核心流程,代码不一定完整。
class SRModel(BaseModel):
"""Base SR model for single image super-resolution."""
def ___init___(self, opt):
# 初始化,主要包括以下几块内容:
# 定义网络结构,根据配置文件,自动实例化相应的网络结构类
self.net_g = build_network(opt['network_g'])
self.net_g = self.model_to_device(self.net_g) # 将网络放到 GPU 上
self.print_network(self.net_g) # 打印网络
# 加载预训练网络
load_path = self.opt['path'].get('pretrain_network_g', None)
if load_path is not None:
param_key = self.opt['path'].get('param_key_g', 'params')
self.load_network(self.net_g, load_path,self.opt['path'].get('strict_load_g', True), param_key)
# 初始化训练的设置
if self.is_train:
self.init_training_settings()
def init_training_settings(self):
# 初始化训练设置。包括优化器、损失函数的定义,学习率的初始化等
self.net_g.train()
...
if self.ema_decay > 0:
# 如果设置了模型 EMA,则设置 EMA 模型和参数
...
# 定以损失函数, 通过 build_loss,根据配置文件,实例化相应的损失函数
self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
# 设置优化器、学习率策略
self.setup_optimizers()
self.setup_schedulers()
def setup_optimizers(self):
# 设置优化器,可以控制哪些参数会被更新
for k, v in self.net_g.named_parameters():
optim_params.append(v)
optim_type = train_opt['optim_g'].pop('type')
self.optimizer_g = self.get_optimizer(optim_type, optim_params,**train_opt['optim_g'])
self.optimizers.append(self.optimizer_g)
def feed_data(self, data):
# 把训练数据送入模型。这里是从 dataloader 中取出数据,用于训练或测试。在SRModel 中,每次取用一个 batch 的 LR 和 GT 图像
# 其他模型对 batch 做不同操作时,经常会改写这个函数。比如只读取 GT 、读取额外 label 、对读取的数据添加 degradation 等操作,都通过修改 feed_data()来实现
self.lq = data['lq'].to(self.device)
self.gt = data['gt'].to(self.device)
def optimize_parameters(self, current_iter):
# 优化参数,这里会完成一次完整的训练过程,即 train_step
# 将优化器梯度归零
self.optimizer_g.zero_grad()
# forward 网络
self.output = self.net_g(self.lq)
# 计算 loss
l_pix = self.cri_pix(self.output, self.gt)
l_total += l_pix
loss_dict['l_pix'] = l_pix
...
# 梯度反传
l_total.backward()
# 优化器优化
self.optimizer_g.step()
# 同步多卡上的损失函数
self.log_dict = self.reduce_loss_dict(loss_dict)
def test(self):
# 测试函数
self.net_g.eval()
with torch.no_grad():
self.output = self.net_g(self.lq)
self.net_g.train()
def dist_validation(self, dataloader, current_iter, ...):
def nondist_validation(self, dataloader, current_iter, ...):
# validation (dist 表示 distributed training,多卡训练)。这里分为了多卡和单卡的 validation
# 这个过程包括读取验证数据集、测试、计算指标、保存结果图等
def save(self, epoch, current_iter):
# 保存训练模型和训练状态
5.4 保存模型、训练状态 和 Resume
悬链的时候,checkpoint会保存两个文件:
- 网络参数 .pth 文件。在每个实验的 models文件夹中,文件名诸如:net_g_5000.pth 、net_g_10000.pth
- 包含optimizer 和 scheduler信息的 .state文件。在每个实验的training_states文件夹中,文件名诸如:5000.state、1000.state
5.4.1如何Resume?
Resume指程序中断后,我们希望能够接着中断的地方,继续训练。只要有保存的网络参数和训练状态,就可以断点重训。在Resume下,实验文件夹不会被覆盖,而是会继续上次的实验文件夹继续保存文件。但是log文件会重新产生。
有两种凡是进行resume:
- 手动resume:在yml配置文件内,设置resume_state为待resume的.state文件路径。然后重新运行训练命令。此时程序会自动查找相应的网络参数.pth文件(即不需要设置类似pretrain_network_g的路径);然后进行resume。注意:resume_state设置后,会覆盖pretrain_network_g的设定。
- 自动resume:只要在命令行中加入–auto_resume,程序就会找到保存的最近的模型参数和状态,并加载进来,接着训练
5.5模型 validation
在框架设计的时候,作者把validation放到每个model中,作为它的成员函数。
根据单卡和多卡训练的不同,我们分别定义了nondist_validation 和 dist_validadtion,对应单卡和多卡validation。
5.6 EMA介绍
EMA(Exponential Moving Average),指数移动平均。它是用来平均一个变量在历史上的值。使用怎样的权重平均呢?如名字所示,随着时间,越是过往的时间,以一个指数衰减的权重来平均。
在BasicSR里面,EMA一般作用于模型的参数上。他的效果一般是:
- 稳定训练效果。GAN训练的结果一般瑕疵更少,视觉效果更好
- 对于以PSNR为目的的模型,其PSNR一般会更高一些
由于开启EMA的代价几乎可以不计,所以推荐开启EMA
如何开启EMA?
在yml的配置文件中,只要指定ema_decay大于0,就会开始EMA。
# training settings
train:
ema_decay:0.9 # 开启EMA,滑动系数为0.9
开启了EMA后,保存的模型会有两个字段:params和params_ema,其中params_ema就是EMA保存的模型。 在测试或者推理时,我们要留意加载的到底是params还是params_ema,这个在yml文件中,一般通过param_key_g:params_ema来指定。
6、网络结构(Architecture)
6.1 basic/arch 目录介绍
在 basicsr/archs/ 目录下,我们提供了若干经典的网络结构:

我们新建 arch 的时候,需要以 _arch.py 结尾,这样才能够被程序自动扫描 import。
6.2网络结构 arch的创建
arch的创建是通过Register机制实现的。具体参考:
- 【第五章第2节:动态实例化与register注册机制】,说明了Register机制是如何根据配置文件中的类型,来自动实例化类的
- 【第四章第2.2节:dataset和model的创建】通过一个完整的例子,说明了其中model的创建过程,在model初始化时,进行了arch的创建
7、损失函数(loss)
7.1basic/losses目录介绍
在basicsr/losses/目录下,我们提供了若干常用的损失函数。

在创建 loss 的时候,需要以_loss.py结尾,才能被程序自动扫描 import。
7.2 loss的创建
loss的创建是通过Register机制实现的。具体可以参考:
- 【第五章第2节:动态实例化与register注册机制】,说明了Register机制是如何根据配置文件中的类型,来自动实例化类的
- 【第四章第2.2节:dataset和model的创建】通过一个完整的例子,说明了其中model的创建过程,在model初始化时,进行了loss的创建
7.3 loss在日志中的添加
loss添加的大部分工作都是代码自动化的。在实际使用中,只需要在xx_model.py计算loss之后,执行loss_dict[‘新的loss’] = 新的loss,即可同时记录在log和tensorboard(tb_logger)文件中。
以basicr、models、sr_models.py 为例:
class SRModel(BaseModel):
...
def optimize_parameters(self, current_iter):
...
loss_dict = OrderedDict() # 使用有序字典,可以在 log 显示的时候,保持我们添加先后的顺序
...
loss_dict['l_pix'] = l_pix # 添加 pixel loss, 字典的 key 以 l_ 打头
loss_dict['l_percep'] = l_percep # 添加 perceptual loss, 字典的 key以 l_ 打头
self.log_dict = self.reduce_loss_dict(loss_dict) # 通过调用reduce_loss_dict 来同步多卡 的loss
# 只要赋值到 self.log_dict,程序即可自动进行后续的 log
添加非loss值
有时需要记录每个iteration的其他一些值(比如gradient norm),我们希望可以在log文件的每一行记录和tb_logger中都有体现。如果为了简便,也可以使用以上方法记录不是loss的其他值。即把其他值也添加到loss_dict中。
注:其实loss_dict正确的含义应该是log_dict。但由于历史原因,被叫做loss_dict,然后为了后面的兼容,就不改名字了。
log命名的约定
在log的时候,loss项使用l_开头,这样在Tensorboard显示时候,所有loss会被组织到一起。比如在basicsr/models/srgan_model.py中,使用了l_g_pix,l_g_percep,l_g_gan等。在basicsr/utils/logger.py中,他们会被组织到一起:
if k.startswith('l_'):
self.tb_logger.add_scalar(f'losses/{k}', v, current_iter)
else:
self.tb_logger.add_scalar(k, v, current_iter)
8、算子(Ops)
8.1什么是算子?
当使用pytorch时,绝大多数操作作为张量(Tensor)的运算。张量计算的种类有很多,比如加法、乘法、矩阵相乘、矩阵转置等,这些计算被称为算子(Operator),它们是pytorch的核心组件。
有时候出于一些其他方面的考虑,会需要增加底层算子。例如有时候对性能要求很高,python不满足需求,因此pytorch也提供了直接扩展底层C++算子的能力。
8.2 BasicSR中的自定义算子
BasicSR 中所用的自定义算子代码在 BasicSR/basicsr/ops 中。采用 C++ extension 的方式添加。它与 PyTorch 相互解耦,分开编译。它的原理其实就是通过 pybind11,将 C++ 编译为PyTorch 的一个模块,这样就可以在 PyTorch 中通过这个新的模块来执行新的操作了。添加方法详情参阅 pytorch官方文档 。
BasicSR 中的自定义算子主要有:
• 可变形卷积 DCN:deform_conv。它在 BasicSR 里面主要用来做隐式对齐,比如用在 EDVR中。注意:如果安装的Torchvision 版本 >= 0.9.0,会自动使用 TorchVision 中提供的 DCN,故不需要安装此编译算子
• StyleGAN2 中的特定的算子,比如:upfirdn2d, fused_act
8.3 BasicSR中算子的编译、安装、使用
编译和安装的过程参见(五)代码主体结构
当算子成功编译后就像调用pytorch原生算子一样
# 调用 PyTorch 原生算子 nn
from torch import nn
Class xxx():
def __init__():
conv1 = nn.Conv2d(...)
def forward():
out = conv1(...)
# 调用自定义算子,可以直接在 forward 中使用
from basicsr.ops.upfirdn2d import upfirdn2d
Class xxx():
def forward():
out = upfirdn2d(...)
9、日志系统(Logger)
BasicSR的日志系统主要包括:
- 记录的log文件
- 通过tensorboard可视化的tb_logger
- wandb
日志系统的实现不过多赘述,有兴趣参阅BasicSR/basicsr/utils/logger.py。本章节主要讲述日志系统各个项目代表什么,以及如何使用。
9.1 log文件记录与解读
当进行实验的时候,代码会在BasicSR/experiments中创建一个属于当前实验的文件夹,文件夹名字为实验名,文件夹中会存在一个按照train_[exp_name]_[timestamp].log方式命名的log文件。下面说明如何按照自己的要求记录log文件,以及现有log文件每个条目的意义。
添加一条 log 信息非常简单:
logger = get_root_logger() # 获得 logger
logger.info(要添加的内容) # 添加正常信息
logger.warning(要添加的警告) # 添加警告信息
下面是一个log文件的例子
# log 文件所在位置: experiments/实验名字/train_[exp_name]_[timestamp].log
2022-06-17 02:27:36,068 INFO:
# 在代码中调用 logger.info()后,会自动记录时间并增加条目 INFO:
# 为节省篇幅,下面 log 中删掉了时间信息
Version Information:
# 软件的版本
BasicSR: 1.3.3.10
PyTorch: 1.9.1+cu111
TorchVision: 0.10.1+cu111
INFO:
name: 000_SRResNet_DIV2K
# 实验名,整个 配置option 的内容都会记录在这里,这里省略掉了
INFO: Dataset [XXXDataset] - XXXdata is built.
INFO: Training statistics:
实验过程中产生的log信息:
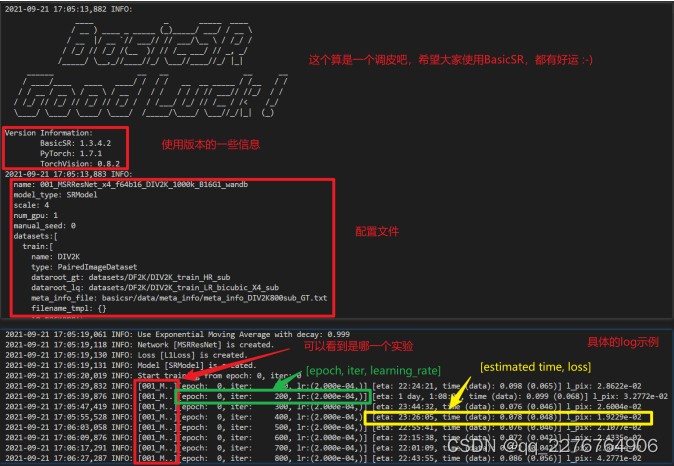
# 训练数据的信息,数量、batchsize 等
Number of train images: 38684
Dataset enlarge ratio: 1
Batch size per gpu: 16
World size (gpu number): 1
Require iter number per epoch: 2418
Total epochs: 207; iters: 500000.
INFO: Dataset [PairedImageDataset] - validation is built.
# dataset 类型
INFO: Number of val images/folders in validation: 14
# 验证集信息
INFO: Network [MSRResNet] is created.
INFO: Network: MSRResNet, with parameters: 1,222,147
# 网络参数量
INFO: MSRResNet(
# 网络结构,此处省略
INFO: Use Exponential Moving Average with decay: 0.999
INFO: Loss [L1Loss] is created.
INFO: Model [RealESRNetModel_XXX] is created.
INFO: Start training from epoch: 0, iter: 0
# 开始训练
INFO: [001_M..][epoch: 0, iter: 100, lr:(2.000e-04,)] [eta: 2 days,21:55:41, time (data): 0.040 (0.004)] l_pix: 5.0581e-02
# [001_M..]: 实验名字,推荐使用数字打头的实验名,这样可以很方便区分实验
# [epoch: 第几轮, iter: 第几次迭代 (一次迭代是一个batch), lr:学习率 (如果分组,则会显示多组)]
# [eta:预估剩余时间, time (data):一次迭代所需时间 (读取数据的时间)]
# l_pix: 当前的各项 loss
INFO: Validation validation
# 验证集验证结果
# psnr: 18.0289
INFO: End of training. Time consumed: 10:22:17
INFO: Save the latest model.
INFO: Validation validation
# 训练结束,最终验证集结果
# psnr: 20.7466
9.2 tensorboard logger记录及解读
除了上述的 log 文件外,BasicSR 还会生成可以用 tensorboard 打开的 tb_logger 文件。一般保存在 BasicSR/experiments/tb_logger/实验名。
如何开启
在 yml 配置文件中设置 ‘use_tb_logger: true’:
# yml 配置文件
logger:
use_tb_logger: true
如何查看
在命令行输入以下命令,就可以在浏览器中查看:
tensorboard --logdir tb_logger --port 5500 --bind_all
下图4.3是一个示例:
如何添加
- 被添加到 log 文件中的值,会被自动添加到 tb_logger 中,比如损失函数
- 其他需要的 (比如 validation 时,metric的值),可仿照下面的方式进行添加
下面是 basicr/models/sr_models.py 中 validation 添加 metrics 值到 tb_logger 的例子:
def _log_validation_metric_values(self, current_iter, dataset_name,tb_logger):
...
for metric, value in self.metric_results.items():
tb_logger.add_scalar(f'metrics/{dataset_name}/{metric}', value,current_iter)
如 果 有 需 要 添 加 其 他 图 片 内 容 , 也 可 以 根 据 需 要 添 加 , 比 如 在 basicsr/models/stylegan2_model.py 中 validation 添加 samples 到 tb_logger 的例子:
def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
# add sample images to tb_logger
result = (result / 255.).astype(np.float32)
result = cv2.cvtColor(result, cv2.COLOR_BGR2RGB)
if tb_logger is not None:
tb_logger.add_image('samples', result, global_step=current_iter,dataformats='HWC')
9.3 Wandb记录及解读
wandb 类似 tensorboard 的云端版本, 可以在浏览器方便地查看模型训练的过程和曲线。
BasicSR 提供了部分模型的 Wandb 训练曲线
https://app.wandb.ai/xintao/basicsr
我们目前只是把 tensorboard 的内容同步到 wandb 上, 因此要使用 wandb, 必须打开 tensorboard
logger。 配置文件如下:
logger:
# 是否使用 tensorboard logger
use_tb_logger: true
# 是否使用 wandb logger,目前 wandb 只是同步 tensorboard 的内容,因此要使用wandb, 必须也同时使用 tensorboard
wandb:
# wandb 的 project. 默认是 None, 即不使用 wandb
project: ~
# 如果是 resume, 可以输入上次的 wandb id, 则 log 可以接起来
resume_id: ~
六、指标
本章节介绍在图像超分辨(去噪亦如是)研究中经常使用的评价指标的相关知识,以及如何在BasicSR框架中使用这些指标进行测试。
1、概述
深度学习发展的旋风产生了源源不断的图像处理算法,这些算法可以生成失真较小、或对人感知上友好的复原图像。然而,限制图像处理方法未来发展的关键瓶颈之一就是“评估机制”。尽管人眼几乎可以毫不费力地区分感知上更好的图像,但算法要公平地衡量视觉质量是一项挑战。
我们通常通过一些图像质量评估方法 (Image quality assessment, IQA) 测量复原图像和真实图像(Ground Truth,GT) 之间的相似性来评估。最近,一些不需要参考图像的 IQA 方法也被用于评估各种算法,例如 Ma 和 Perceptual Index (PI) 。在某种程度上,这些 IQA 方法是图像处理领域取得长足进步的主要原因,因为他们提供了一个量化的基准,以促进指标上更优秀的算法的诞生。
接下来,我们先介绍图像质量评估(IQA) 方面的知识。IQA 方法用于测量在采集、压缩、复制和后处理操作过程中可能会降低的图像质量。根据不同的使用场景,IQA 方法可以分为全参考法 (Full-reference IQA,FR-IQA) 和无参考法 (No-reference IQA,NR-IQA) 。FR-IQA 方法通常
从信息或感知特征相似度的角度衡量两幅图像之间的相似度,已广泛应用于图像/视频编码、恢复和通信质量的评估。除了最广泛使用的 PSNR,FR-IQA 已经经过广泛的研究,并至少可以追溯到 2004 年提出的 SSIM,它首先在测量图像相似性时引入了结构信息。PSNR 和 SSIM 同时也是在各种图像复原研究中使用最广泛的评价指标。除此之外,很多 FR-IQA 方法也被提出来弥补IQA 方法的结果与人类判断之间的差距,例如 IFC,VSI,FSIM 等。然而,不断出现的新算法一直在不断提高图像恢复的效果,PSNR 和 SSIM 的定量结果和感知质量之间越来越不一致。有研究指出,面向感知效果的图像处理中,PSNR 和 SSIM 等指标衡量的失真程度和图像所展示的感知质量是彼此冲突的。此时,一些更符合人感知判断的评价指标也被用于评价图像复原算法,如LPIPS。
除了上述 FR-IQA 方法外,一些 NR-IQA 方法也经常被用来在没有参考图像时评价图像的质量。一个比较典型的场景就是对真实世界中图像复原效果的评价。一些流行的 NR-IQA 方法包括NIQE、BRISQUE 和 PI。在最近的一些工作中,结合 NR-IQA 和 FR-IQA 方法来测量 IR 算法。
2、PSNR
PSNR (Peak signal-to-noise ratio,峰值信噪比) 是图像处理研究中应用最广泛的评价指标之一。PSNR 是一个表示信号的最大可能功率和影响它的精度的破坏性噪声功率的比值的工程术语。PSNR 常用对数分贝单位来表示,简写为 dB (decibel) 。PSNR 基于逐像素的均方误差 (Mean square error,MSE) 来定义。两个尺寸为 𝑚 × 𝑛 的单通道图像 𝐼 和 𝐼′,其中 𝐼是高质量的参考图像,𝐼′为经过退化的低质量图片或者复原后的图像,那么它们的的均方误差定义为:
M
S
E
=
1
m
n
∑
i
=
1
m
∑
j
=
1
n
(
I
[
i
,
j
]
−
I
′
[
i
,
j
]
)
2
.
\mathrm{MSE}=\frac{1}{mn}\sum_{i=1}^{m}\sum_{j=1}^{n}(I[i,j]-I'[i,j])^2.
MSE=mn1∑i=1m∑j=1n(I[i,j]−I′[i,j])2.
而PSNR被定义为:
P
S
N
R
=
10
×
log
10
(
Peak
2
MSE
)
=
20
×
log
10
(
Peak
MSE
)
.
\mathrm{PSNR}=10\times\log_{10}\big(\frac{\text{Peak}^2}{\text{MSE}}\big) = 2 0 \times \log_{10}\big(\frac{\text{Peak}}{\sqrt{\text{MSE}}}\big).
PSNR=10×log10(MSEPeak2)=20×log10(MSEPeak).
其中,Peak是表示图像像素强度的最大取值,如果每个采样点用 8 位表示,那么Peak = 255。
在 BasicSR 框架中,与 PSNR 计算相关的代码存放在basicsr/metrics/psnr_ssim.py 文件中。对于 numpy.ndarray 类型的变量,我们约定输入图像的数据格式为 Unit8,尺寸为 h,w,c 。对于彩色图片通道顺序为 BGR。此时输入图像像素的取值范围为[0, 255]整数取值。此时,我们使用如下函数计算 PSNR:
@METRIC_REGISTRY.register()
def calculate_psnr(img, img2, crop_border, input_order='HWC',
test_y_channel=False, **kwargs):
# img, img2: 输入图像变量
# crop_border: 是否在计算PSNR时切除边缘的像素。使用神经网络处理图像时,边缘的几个像素通常会有较大误差。
# input_order: 输入的尺寸顺序,默认为'HWC'
# test_y_channel: 是否转换到 Y 空间计算 PSNR。Y 指代 YCbCr格式图像中的灰度通道。
...
当输入变量为 torch.Tensor 类型时,我们约定输入图像的数据格式为 Float32,尺寸为[n,c,h,w] (批次大小,通道数 (3或者1) ,高,宽) 。对于彩色图片通道顺序为 RGB。此时输入图像像素的取值范围为[0, 1] 浮点数取值。此时,我们使用如下以 _pt 结尾的函数计算 PSNR:
@METRIC_REGISTRY.register()
def calculate_psnr_pt(img, img2, crop_border,
test_y_channel=False, **kwargs):
...
需要注意的是,此函数支持对于一整个批次 (batch) 的数据计算 PSNR。
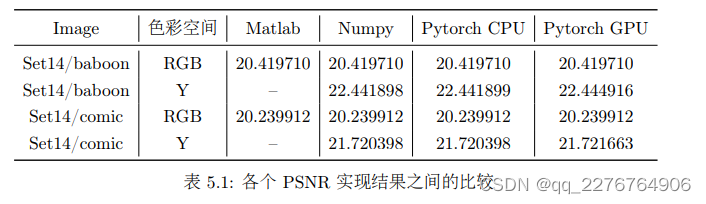
在实现上, PSNR 的计算在不同人、不同版本的实现之间有微小的差异。我们对比了我们的实现和其他实现之间的差异,结果如表 5.2 所示:
3、SSIM
SSIM (structural similarity index,图像结构相似性指标) 是另一个被广泛使用的图像相似度评价指标。与 PSNR 评价逐像素的图像之间差异不同,SSIM 在图像质量上的衡量更侧重于图像的结构信息,这与人类对于视觉信息的感知是相似的。因此普遍认为 SSIM 更贴近人类对于图像质量的判断。
此处的结构相似性的基本思想是自然图像是高度结构化的,即自然图像中相邻像素之间存在很强的相关性,这种相关性承载着场景中物体的结构信息。人类视觉系统习惯于在查看图像时提取这样的结构信息。因此,在设计衡量图像畸变程度的图像质量测量指标时,结构畸变的测量是重要的一环。给定两个图像信号x 和y,SSIM 被定义为:
S
S
I
M
(
x
,
y
)
=
[
l
(
x
,
y
)
]
α
[
c
(
x
,
y
)
]
β
[
s
(
x
,
y
)
]
γ
\mathrm{SSIM}(\mathrm{x},\mathrm{y})=[l(\mathrm{x},\mathrm{y})]^{\alpha}[c(\mathrm{x},\mathrm{y})]^{\beta}[s(\mathrm{x},\mathrm{y})]^{\gamma}
SSIM(x,y)=[l(x,y)]α[c(x,y)]β[s(x,y)]γ
SSIM 由亮度对比 𝑙(x, y)、对比度对比𝑐(x, y)、结构对比𝑠(x, y)三部分组成。这些评价指标由以下方式定义:
l
(
x
,
y
)
=
2
μ
x
μ
y
+
C
1
μ
x
2
+
μ
y
2
+
C
1
,
c
(
x
,
y
)
=
2
σ
x
σ
y
+
C
2
σ
x
2
+
σ
y
2
+
C
2
,
s
(
x
,
y
)
=
σ
x
y
+
C
3
σ
x
σ
y
+
C
3
.
l(\mathrm{x},\mathrm{y})=\frac{2\mu_x\mu_y+C_1}{\mu_x^2+\mu_y^2+C_1},c(\mathrm{x},\mathrm{y})=\frac{2\sigma_x\sigma_y+C_2}{\sigma_x^2+\sigma_y^2+C_2},s(\mathrm{x},\mathrm{y})=\frac{\sigma_{xy}+C_3}{\sigma_x\sigma_y+C_3}.
l(x,y)=μx2+μy2+C12μxμy+C1,c(x,y)=σx2+σy2+C22σxσy+C2,s(x,y)=σxσy+C3σxy+C3.
其 中 𝛼 > 0,𝛽 > 0,𝛾 > 0用 于 调 整 亮 度 , 对 比 度 和 结 构 之 间 的 相 对 重 要 性 。𝜇𝑥及𝜇𝑦、𝜎𝑥及𝜎𝑦分表示x和y的平均值和标准差,𝜎𝑥𝑦x和y的协方差,𝐶1、𝐶2、𝐶3是常数,用于维持结果的稳定。实际使用时,为简化起见,我们定义参数为𝛼 = 𝛽 = 𝛾 = 1以及𝐶3 = 𝐶2/2,
得到:
SSIM(x,y)
=
(
2
μ
x
μ
y
+
C
1
)
(
2
σ
x
y
+
C
2
)
(
μ
x
2
+
μ
y
2
+
C
1
)
(
σ
x
2
+
σ
y
2
+
C
2
)
.
\text{SSIM(x,y)}=\frac{(2\mu_x\mu_y+C_1)(2\sigma_{xy}+C_2)}{(\mu_x^2+\mu_y^2+C_1)(\sigma_x^2+\sigma_y^2+C_2)}.
SSIM(x,y)=(μx2+μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2).
在实际计算两幅图像的结构相似度指数时,我们会指定一些局部化的窗口,一般为𝑁 × 𝑁的小块,计算窗口内信号的结构相似度指数。然后每次以像素为单位移动窗口,直到计算出整幅图像每个位置的局部结构相似度指数。所有局部结构相似度指标的平均值为两幅图像的结构相似度指标。结构相似度指数的值越大,表明两个信号之间的相似度越高。一般来讲,PSNR 和 SSIM的结果趋势是一致的,即一般 PSNR 高,则 SSIM 也高。
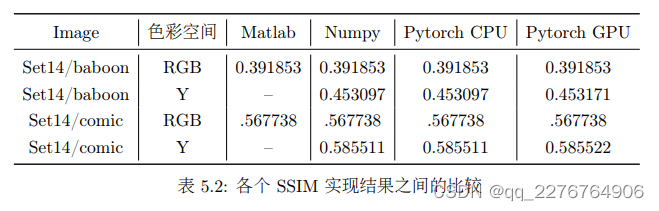
在 BasicSR 框架中,与 PSNR 计算相关的代码存放在 basicsr/metrics/psnr_ssim.py 文件中。与计算 PSNR 的接口类似,其函数包含对 numpy.ndarray 类型的输入进行处理的calculate_ssim 函数以及对 torch.Tensor 类型的输入进行处理的calculate_ssim_pt 函数。其对于输入的类型,格式,尺寸以及各参数的约定是与 PSNR 的计算中描述的一致的。与 PSNR 不同,SSIM 的计算在不同实验版本之间的差异较大。在 BasicSR 中,我们以 Matlab最原始的版本保持一致。我们对比了我们的实现和其他实现之间的差异,结果如表 5.2 所示
4、NIQE
待完善…
5、如何使用指标
5.1 通过配置文件指定
在训练的 validation 阶段或者使用 test.py 测试时,我们可以在配置文件中指定所需要使用的指标。这样程序就会自动计算相应指标了。 比如下面的配置就会计算 PSNR 和 NIQE 的指标,分别调用了 calculate_psnr 和 calculate_niqe。
# validation settings
val:
...
metrics: # 这块是 validation 中使用的指标的配置
psnr: # metric 名字, 这个名字可以是任意的
type: calculate_psnr # 选择指标类型
# 以下属性是灵活的, 根据不同 metric 有不同的设置
crop_border: 4 # 计算指标时 crop 图像边界像素范围 (不纳入计算范围)
test_y_channel: false # 是否转成在 Y(CbCr) 空间上计算
better: higher # 该指标是越高越好,还是越低越好。选择 higher 或者lower,默认为 higher
niqe: # 这是在 validation 中使用的另外一个指标
type: calculate_niqe
crop_border: 4
better: lower # the lower, the better
5.2使用脚本计算
我们在 scripts/metrics 文件中也提供了调用指标的脚本。 读者可以根据相关说明计算指标。
七、如何添加与修改
本章主要介绍如何在BasicSR框架中添加自定义的Dataset、网络结构(Architecture)、模型(Model),损失函数(Loss)以及指标(Metric)。使用者需要关注四个方面,即:
- 相关文件的存放和命名
- 编写自定义文件
- 注册新添加类
- 以及在配置文件中进行设置
这一部分的内容大体上十分相似,使用者只要对某一个模块比较熟悉(如添加网络结构),即可快速类比至其他各部分。在添加新的自定义模块时,理解并参考已有文件可以帮助使用者快速上手。
值得提及的是,当用户使用BasicSR-template进行开发,尤其是针对指标模块时,以下操作可能并不完全适用。具体详见BasicSR-examples模版部分。
1、添加修改Dataset
第 1 步
Dataset 文 件 的 存 放 与 命 名 :Dataset 文 件 存 放 在 basicsr/data/ 文 件 夹 下 。 例如,basicsr/data/paired_image_dataset.py。用户可根据需求对已有的 Dataset 进行修改,或是添加自定义 Dataset 文件。在创建新的自定义 Dataset 文件时,注意文件名需以_dataset.py 作为结尾
第 2 步
编写自定义 Dataset :在 Dataset 文件中对自定义 Dataset 类进行命名,需要注意新建类名不能与已有类名重复,否则会导致后续注册机制报错。关于 Dataset 文件中函数功能详解见【第五章第4节:数据】,此处不再赘述。对于需要添加新的设置参数,用户可以灵活利用 opt 参数从配置文件中读取
第 3 步
注册 Dataset :用户需要对新建的 Dataset 类进行注册。注册机制的原理详见【第五章第2节:动态实例化与register注册机制】。此处具体操作为,首先对 DATASET_REGISTRY 函数进行导入,然后在新建类上方添加修饰器来注册新建函数。以paired_image_dataset.py 中的 PairedImageDataset 为例:
from basicsr.utils.registry import DATASET_REGISTRY
@DATASET_REGISTRY.register()
class PairedImageDataset(data.Dataset):
...
第 4 步
在配置文件中设置自定义 Dataset :将配置文件(即 YAML 文件)中 datasets 部分中type 参数设置为新建的 Dataset 类名即可。 该部分其余参数的功能与 Dataset 中用户自定义的功能对应。以使用 paired_image_dataset.py 中的PairedImageDataset 为例:
# dataset and data loader settings
dataset:
...
type: PairedImageDataset # 设置为需要使用的 Dataset 类名
...
2、添加修改模型
第 1 步
模 型 文 件 的 存 放 与 命 名 : 模 型 文 件 存 放 在 basicsr/models/ 文 件 夹 下 。 例如,basicsr/archs/sr_model.py。用户可根据需求对已有的模型进行修改,或是添加自定义模型文件。在创建新的自定义模型文件时,注意文件名需以 _model.py 作为结尾。
第 2 步
编写自定义模型:在模型文件中对自定义模型类进行命名,需要注意新建类名不能与已有类名重复,否则会导致后续注册机制报错。关于模型文件中的函数功能详解见【第五章第5节:模型】。模型部分涉及的函数较多,但一般情况下需要改写的部分非常有限。用户往往只需要继承已有模型,并对需要更改的函数进行重构即可。以basicsr/archs/swinir_model.py 中的 SwinIRModel 为例,该模型相较于图像超分通用的 basicsr/archs/sr_model.py 中的 SRModel 仅需更改 test 函数,因此 SwinIRModel类在继承了 SRModel 的基础上只对 test 函数进行了重构:
class SwinIRModel(SRModel): # SwinIRModel 继承自 SRModel
def test(self): # 重构 test 函数
...
第 3 步
注册模型:用户需要对新建的模型类进行注册。注册机制的原理详见【第五章第2节:动态实例化与register注册机制】。此处具体操作为,首先对 MODEL_REGISTRY 函数进行导入,然后在新建类上方添加修饰器来注册新建类。以 sr_model.py 中的 SRModel 为例:
1 from basicsr.utils.registry import MODEL_REGISTRY
2
3 @MODEL_REGISTRY.register()
4 class SRModel(nn.Module):
5 ...
第 4 步
在配置文件中设置自定义模型:将配置文件(即 YAML 文件)中 general settings部分中的 model_type 参数设置为新建的模型类名即可。以使用 sr_model.py 中的SRModel 为例:
# general settings
...
type: SRModel # 设置为需要使用的模型类名
...
除此之外,模型与整个配置文件的内容都是息息相关的,涉及到数据的读取与处理、模型网络结构、训练优化和测试评估等几乎所有内容的设置组成,而非一个独立的部分。用户在修改配置文件的结构时,建议参考已有文件作为模板,重点对模型进行修改的部分在配置文件中做对应处理。
3、添加修改网络结构
第 1 步
网络结构文件的存放与命名:网络结构文件存放在 basicsr/archs/ 文件夹下。例如,basicsr/archs/srresnet_arch.py。用户可根据需求对已有的网络结构进行修改,或是添加自定义网络结构文件。在创建新的自定义网络结构文件时,注意文件名需以_arch.py 作为结尾。
第 2 步
编写自定义网络结构:在网络结构文件中对自定义网络结构类进行命名,需要注意新建类名不能与已有类名重复,否则会导致后续注册机制报错。关于网络结构文件中的函数功能详解见【第五章第6节:网络结构】。对于需要手工设置的参数,用户可以灵活利用 opt参数从配置文件中读取。
第 3 步
注册网络结构:用户需要对新建的网络结构类进行注册。注册机制的原理详见【第五章第2节:动态实例化与register注册机制】。此处具体操作为,首先对 ARCH_REGISTRY 函数进行导入,然后在新建类上方添加修饰器来注册新建类。以 srresnet_arch.py 中的 MSRResNet 类为例:
from basicsr.utils.registry import ARCH_REGISTRY
@ARCH_REGISTRY.register()
class MSRResNet(nn.Module):
...
第 4 步
在配置文件中设置自定义网络结构:将配置文件(即 YAML 文件)中 network structures 部分中的 type 参数设置为新建的网络结构类名即可。 该部分其余参数的功能与模型和网络结构中用户自定义的功能对应。以使用 srresnet_arch.py 中的 MSRResNet 为例:
network structures
network_g: # g网络设置
...
type: MSRResNet # 设置为需要使用的网络结构类名
...
4、 添加修改损失函数
第 1 步
损 失 函 数 的 存 放 与 命 名 : 损 失 函 数 文 件 存 放 在 basicsr/losses/ 文 件 夹 下 。 例如,basicsr/losses/gan_loss.py。用户可根据需求对已有的损失函数进行修改,或是添加自定义损失函数文件。在创建新的损失函数文件时,注意文件名需以 _loss.py 作为结尾。
第 2 步
编写自定义损失函数:在损失函数文件中对自定义损失函数类进行命名,需要注意新建类名不能与已有类名重复,否则会导致后续注册机制报错。关于损失函数的功能详解见【第五章第7节:损失函数】。对于需要手工设置的参数,用户可以灵活利用 opt 参数从配置文件中读取。
第 3 步
注册损失函数:用户需要对新建的损失函数类进行注册。注册机制的原理详见【第五章第2节:动态实例化与register注册机制】。此处具体操作为,首先对 LOSS_REGISTRY 函数进行导入,然后在新建类上方添加修饰器来注册新建类。以 basicsr/losses/basic_loss.py 中的L1Loss 为例:
1 from basicsr.utils.registry import LOSS_REGISTRY
2
3 @LOSS_REGISTRY.register()
4 class L1Loss(nn.Module):
5 ...
第 4 步
在配置文件中设置自定义损失函数:将配置文件(即 YAML 文件)中 losses 部分中相应损失函数项的 type 参数设置为新建的损失类名即可。需要注意损失函数项的存在与模型有关。以使用 basicsr/losses/basic_loss.py 中的 L1Loss 为例:
1 # losses
2 pixel_opt: # pixel-wise 损失函数项,与模型有关
3 type: L1Loss # 设置为需要使用的损失函数类名
4 ...
添加非 Class 的损失函数
在实际使用情况中,我们会遇到一些损失函数,他们不是以类 (Class )的形式出现,而是普通的函数。比如 StyleGAN2 中使用的 r1_penalty 和 gradient_penalty_loss。
此时,我们不再以注册机制的方式使用,而是直接在模型中调用相关函数。
from basicsr.losses.gan_loss import r1_penalty
class StyleGAN2Model(BaseModel):
...
def optimize_parameters(self, current_iter):
...
real_pred = self.net_d(self.real_img)
l_d_r1 = r1_penalty(real_pred, self.real_img) # 直接调用损失函数r1_penalty
...
5、添加修改指标
第 1 步
指标的存放与命名:指标文件存放在 basicsr/metrics/ 文件夹下。对于命名规则无要求,一般直接以功能命名即可,如 basicsr/metrics/psnr_ssim.py。
第 2 步
编写自定义指标:在指标文件中对自定义指标函数进行命名,需要注意新建函数名不能与已有函数名重复,否则会导致后续注册机制报错。关于指标的功能详解见【第六章:指标】。在编写完自定义指标后,注意在basicsr/metrics/init.py 文件中对添加的自定义指标进行导入。以 calculate_psnr 为例:
from .psnr_ssim import calculate_psnr
第 3 步
注册指标:用户需要对新建的指标函数进行注册。注册机制的原理详见【第五章第2节:动态实例化与register注册机制】。此处具体操作为,首先对 METRIC_REGISTRY 函数进行导入,然后在新建函数上方添加修饰器来注册新建函数。以 psnr_ssim.py 中的 calculate_psnr 为例:
from basicsr.utils.registry import METRIC_REGISTRY
@METRIC_REGISTRY.register()
def calculate_psnr(img, img2, ... ):
...
第 4 步
在配置文件中设置自定义指标:将配置文件(即 YAML文件)中 validation settings 部分中 metric 部分中的 type 参数设置为新建的指标函数名即可。指标的其他参数设置对应其功能部分代码。以使用 psnr_ssim.py 中的 calculate_psnr 为例:
# validation settings
val:
...
metrics:
psnr: # 指标名称,可以是任意的,用于标记
type: calculate_psnr # 设置为需要使用的指标函数名
...
八、数据准备
这部分主要讲述数据存储形式,FileClient类,以及一些常见数据集的获取和描述。
1、常见用法
目前支持的数据存储形式有以下三种:
- 直接以图像/视频帧的格式存放在硬盘
- 制作成 LMDB。 训练数据使用这种形式,一般会加快读取速度
- 若是支持 Memcached,则可以使用。 它们一般应用在集群上
目前,我们可以通过 yaml 配置文件方便地修改。以支持 DIV2K 的 PairedImageDataset 为例,根据不同的要求修改 yaml 文件。
- 直接读取硬盘数据
type: PairedImageDataset
dataroot_gt: datasets/DIV2K/DIV2K_train_HR_sub
dataroot_lq: datasets/DIV2K/DIV2K_train_LR_bicubic/X4_sub
io_backend:
type: disk
- 使用 LMDB。在使用前需要先制作 LMDB,参见本章节 2.1:数据准备, 注意我们在原有的LMDB 上,新增加了 meta 信息,而且具体保存二进制内容也不同,因此其他来源的 LMDB并不能直接拿过来使用
type: PairedImageDataset
dataroot_gt: datasets/DIV2K/DIV2K_train_HR_sub.lmdb
dataroot_lq: datasets/DIV2K/DIV2K_train_LR_bicubic_X4_sub.lmdb
io_backend:
type: lmdb
- 使用 Memcached。 机器/集群需要支持 Memcached。具体的配置文件根据实际的Memcached 需要进行修改:
type: PairedImageDataset
dataroot_gt: datasets/DIV2K_train_HR_sub
dataroot_lq: datasets/DIV2K_train_LR_bicubicX4_sub
io_backend:
type: memcached
server_list_cfg: /mnt/lustre/share/memcached_client/server_list.conf
client_cfg: /mnt/lustre/share/memcached_client/client.conf
sys_path: /mnt/lustre/share/pymc/py3
2、数据存储格式
2.1 LMDB具体说明
我们在训练的时候使用 LMDB 存储形式可以加快 IO 和 CPU 解压缩的速度 (测试的时候数据较少, 一般就没有太必要使用 LMDB)。其具体的加速要根据机器的配置来,以下几个因素会影响:
- 有的机器设置了定时清理缓存,而 LMDB 依赖于缓存。因此若一直缓存不进去,则需要检查一下。一般 free -h 命令下, LMDB 占用的缓存会记录在 buff/cache 条目下面
- 机器的内存是否足够大,能够把整个 LMDB 数据都放进去。如果不是,则它由于需要不断更换缓存,会影响速度
- 若是第一次缓存 LMDB 数据集,可能会影响训练速度。可以在训练前,进入 LMDB 数据集目录,把数据先缓存进去:cat data.mdb > /dev/null
2.1.1 文件结构
除了标准的 LMDB 文件 (data.mdb 和 lock.mdb) 外,我们还增加了 meta_info.txt 来记录额外的信息。下面用一个例子来说明:
DIV2K_train_HR_sub.lmdb
├── data.mdb
├── lock.mdb
├── meta_info.txt
2.1.2 meta信息
meta_info.txt。我们采用 txt 来记录,是为了可读性。其里面的内容为:
0001_s001.png (480,480,3) 1
0001_s002.png (480,480,3) 1
0001_s003.png (480,480,3) 1
0001_s004.png (480,480,3) 1
...
每一行记录了一张图片,有三个字段,分别表示:
- 图像名称 (带后缀): 0001_s001.png
- 图像大小:(480,480,3) 表示是480 × 480 × 3的图像
- 其 他 参 数 (BasicSR 里 面 使 用 了 cv2 压 缩 png 程 度): 因 为 在 复 原 任 务 中 ,我 们 通 常 使 用 png 来 存 储 , 所 以 这 个 1 表 示 png 的 压 缩 程 度 , 也 就 是CV_IMWRITE_PNG_COMPRESSION 为 1。CV_IMWRITE_PNG_COMPRESSION可以取值为 [0, 9] 的整数,更大的值表示更强的压缩,即更小的储存空间和更长的压缩时间
2.1.3二进制内容
为 了 方 便 , 我 们 在 LMDB 数 据 集 中 存 储 的 二 进 制 内 容 是 cv2 encode 过 的 image:cv2.imencode(‘.png’, img, [cv2.IMWRITE_PNG_COMPRESSION, compress_level]。可以通过compress_level 控制压缩程度,平衡存储空间和读取 (包括解压缩) 的速度。
2.1.4如何制作
我们提供了脚本 scripts/data_preparation/create_lmdb.py 来制作。在运行脚本前,需要根据需求修改相应的参数。目前支持 DIV2K,REDS 和 Vimeo90K 数据集,其他数据集可仿照进行制作。
python scripts/data_preparation/create_lmdb.py --dataset div2k
python scripts/data_preparation/create_lmdb.py --dataset reds
python scripts/data_preparation/create_lmdb.py --dataset vimeo90k
加速IO的方法:
除了使用LMDB加速IO外,还可以使用prefetch方式,【具体参见第五章第4.4节dataset prefetch说明】
3、meta文件介绍
meta 文件是记录数据集信息的。一般我们使用 txt 格式,这样我们打开就能够知道它里面记录的内容。
有时候我们从一个目录里面扫描全部的文件会比较慢、耗时,此时如果提供了 meta 文件,就可以比较快速地得到所有文件 (比如图片) 的路径列表了。
同时我们也会使用 meta 文件来划分数据集,比如训练、测试集等。
它一般在以下几个场景中使用:
- 制作 LMDB 后会同步产生一个 meta 文件,这个meta 有着自己固定的格式,不能修改,否则可能会影响 LMDB 数据的读取。
- PairedImageDataset 支持 meta_info_file 参数,会使用这个 meta 文件生成待读取的文件
路径。这个可以根据用户自己的需要进行自定义
3.1现有meta文件说明
在basicsr/data/meta_info目录下有提供了一些常用的meta文件,说明如下:
待完善…
4、File Client 介绍
作者参考了MMCV的FileClient设计。为了使其兼容BasicSR,作者对接口做了一些改动(主要是为了适应LMDB)。具体可以参见代码file_client.py。
待完善…
5、常见数据集介绍与准备
推荐把数据通过ln -s src dst 软链到datasets目录下。
具体数据集介绍见作者官方给的数据集,出于学习笔记的目的此处仅记录数据准备步骤。
5.1 图像数据集 DIV2K 与 DF2K
- 从 DIV2K 官网下载数据。 Flickr 2K 可从https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar
下载 - Crop to sub-images:因为 DIV2K 数据集是 2K 分辨率的 (比如: 2048×1080), 而我们在训练的时候往往并不要那么大 (常见的是 128×128 或者 192×192 的训练 patch). 因此我们可以先把 2K 的图片裁剪成有 overlap 的 480×480 的子图像块. 然后再由 dataloader 从这个 480×480 的子图像块中随机 crop 出 128×128 或者 192×192 的训练patch。 运行脚本extract_subimages.py:
python scripts/data_preparation/extract_subimages.py
使用之前可能需要修改文件里面的路径和配置参数。注意:sub-image 的尺寸和训练patch 的尺寸 (gt_size) 是不同的。我们先把2K分辨率的图像 crop 成 sub-images (往往是 480×480),然后存储起来。在训练的时候,dataloader 会读取这些 sub-images,然后进一步随机裁剪成 gt_size × gt_size 的大小
3. [可选] 若需要使用 LMDB,则需要制作 LMDB,参考章节7.2.1。数据准备 运行脚本:
python scripts/data_preparation/create_lmdb.py --dataset div2k
注意选择 create_lmdb_for_div2k 函数,并需要修改函数相应的配置和路径
4. 单 元 测 试 : 我 们 可 以 单 独 测 试 dataset 是 否 正 常 。 注 意 修 改 函 数 相 应 的 配 置 和 路径:test_scripts/test_paired_image_dataset.py。
5. [可选] 若需要生成 meta_info_file 文件,请运行
python scripts/data_preparation/generate_meta_info.py

















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









