







系列文章目录
文章名称:Swin Transformer UNet for Image Denoising
文章地址:http://arxiv.org/abs/2202.14009
代码地址:https://github.com/fanchimao/sunet
发表时间:2022
应用领域:
主要模块:
摘要
在本文中我们提出了一种称为SUNet的恢复模型,它使用Swin Transformer层作为我们的基本块,然后应用于UNet架构以进行图像去噪。源代码和预训练模型可在https://github.com/FanChiMao/SUNet获取。
Introduction
图像复原是一种重要的低级图像处理,可以提高目标检测、图像分割和图像分类等高级视觉任务的性能。 在一般的恢复任务中,损坏的图像 Y 可以表示为:
Y = D(X) +n (1)
其中 X 是干净的图像,D(.) 表示退化函数,n 表示加性噪声。 一些常见的恢复任务是去噪、去模糊和去块。
传统的图像复原方法通常基于算法,称为基于先验或基于模型的方法,例如用于去噪的BM3D、WNNM;反卷积,图像先验用于去模糊。尽管大多数基于卷积神经网络(CNN)的方法都取得了出色的性能,但原始卷积层存在一些问题。首先,卷积核与图像内容无关,使用相同的卷积核来恢复不同的图像区域可能不是最好的解决方案。其次,因为卷积核可以看作是一个小补丁,获取的特征是局部信息,换句话说,当我们进行远程依赖建模时,全局信息会丢失。尽管在一些论文中,他们提出了一些方法来克服这些缺点,如自适应卷积、非局部卷积和全局平均池化等,但直到Swin Transformer的出现。
最近,提出了一种基于 transformer 的新主干,称为 Swin Transformer,并在图像分类方面取得了令人印象深刻的性能。 此外,在越来越多的计算机视觉任务中,包括图像分割、目标检测、修复和超分辨率,使用Swin 作为主干的 Transformer 已经超越了基于 CNN 的方法,达到了最先进的水平。 在本文中,我们还将 Swin Transformer 视为我们的主要骨干,并将其集成到称为 SUNet 的 UNet 架构中以进行图像去噪。
总的来说,本文的主要贡献可以概括如下:
• 我们提出了一种基于图像分割Swin-UNet 模型的Swin Transformer 网络,用于图像去噪。
• 我们提出了一种双上采样块架构,它包括亚像素和双线性上采样方法,以防止棋盘伪影。实验结果证明,它比转置卷积的原始上采样更好。
• 据我们所知,我们的模型是第一个在去噪中结合Swin Transformer 和UNet 的模型。
• 我们在两个用于图像去噪的常用数据集中展示了我们的 SUNet 的竞争结果。
Realated work
随着硬件(例如 GPU)的快速发展,基于学习的方法在执行速度和性能上都击败了传统的基于模型的方法。 在本节中,我们首先将介绍以前关于去噪的工作。 然后,我们将描述UNet和Swin Transformer的相关工作。
Image Restoration
如前所述,传统的图像恢复方法基于图像先验或通常称为基于模型的方法的算法,例如自相似性 NL-Means、备用编码和全变分。 这些方法在不适定问题上的性能是可以接受的,但它们有一些缺点,如耗时、计算量大、难以恢复复杂的图像纹理等。与传统的恢复方法相比,基于学习的方法,尤其是卷积神经网络(CNNs),由于其令人印象深刻的性能,已成为包括图像恢复在内的计算机视觉领域的主流。
UNet
如今,UNet是许多图像处理应用中的知名架构,因为它具有分层特征图以获得丰富的多尺度上下文特征。 此外,它使用编码器和解码器之间的跳跃连接来增强图像的重建过程。 UNet 广泛用于许多计算机视觉任务,如分割、恢复。 此外,它还有各种改进版本,如 Res-UNet、Dense-UNet、Attention UNet和 Non-local UNet。 由于强大的自适应主干,UNet 可以很容易地应用于不同的提取块以提高性能。
SwinTransformer
Transformer模型在自然语言处理邻域取得了成功,并且与CNN具有竞争优势,尤其是在图像分类方面。然而,直接使用Transformer进行诗句任务的两个主要问题是:1.图像和序列之间的尺度差异较大。Transformer存在建模长序列的缺陷,因为他需要大约一维序列参数的平方倍。2.Transformer不擅长解决密集预测任务,如实例分割,这是一个像素级别的任务。然而,Swin Transformer通过移位窗口以减少参数解决了上述问题,并在许多像素级视觉任务中实现了最先进性能。
Proposed Method
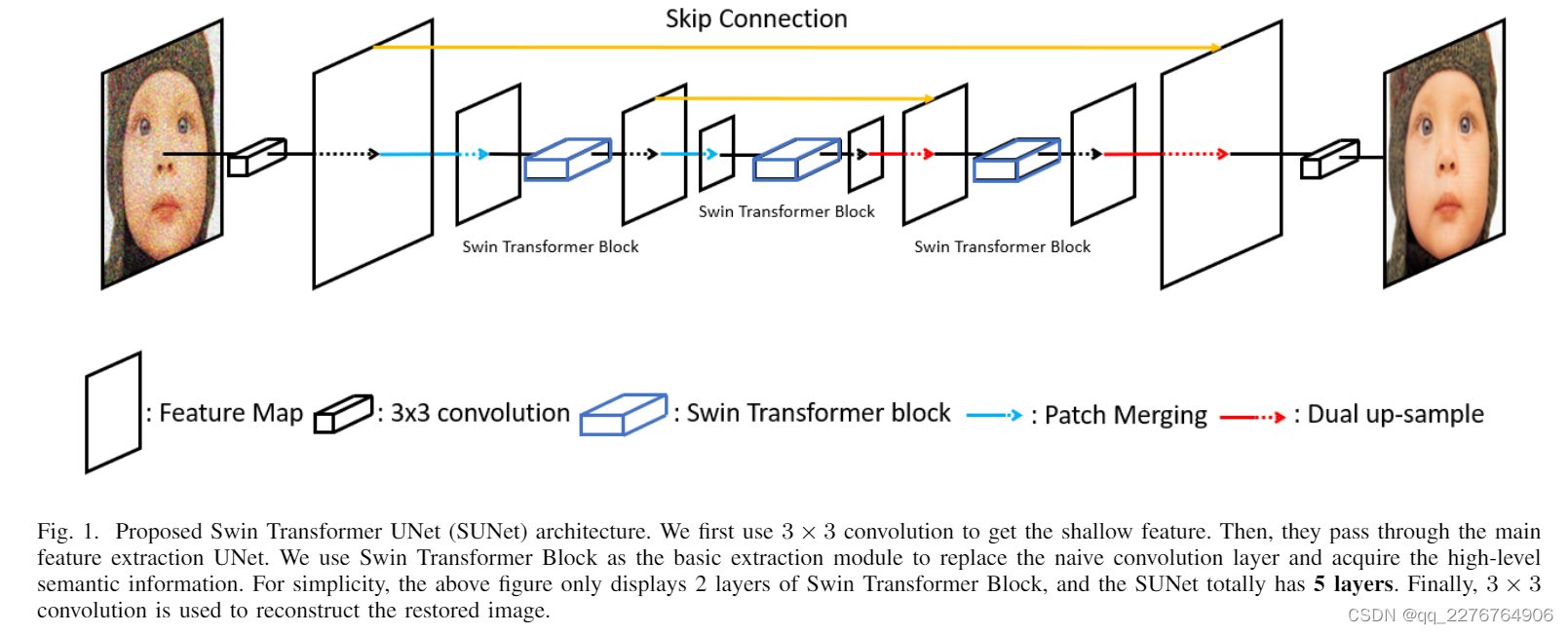
SUNet
所提出的 Swin Transformer UNet (SUNet) 的架构基于图像分割模型 [19],如图 1 所示。SUNet 由三个模块组成:1)浅层特征提取; 2)UNet特征提取; 3)重建模块。
shallow feature extaction module
输入一个含噪图像
Y
∈
R
H
×
W
×
3
Y\in\mathbb{R}^{H\times W\times3}
Y∈RH×W×3,其中H、W是损坏图像的分辨率。我们使用单个3*3卷积层
M
S
F
E
(
.
)
M_{SFE}(.)
MSFE(.)来获取输入图像的颜色或纹理等低频信息。浅层特征
F
s
h
a
l
l
o
w
∈
R
H
×
W
×
C
F_{s h a l l o w}\in\mathbb{R}^{H\times W\times C}
Fshallow∈RH×W×C可以表示为:
F
s
h
a
l
l
o
w
=
M
S
F
E
(
Y
)
F_{shallow}=M_{SFE}(Y)
Fshallow=MSFE(Y) (2)
其中c是浅层特征的通道数,其中我们后面的实验部分都设置为96.
UNet feature extraction module
然后将浅层特征图
F
s
h
a
l
l
o
w
F_{shallow}
Fshallow馈入UNet特征提取层
M
U
F
E
(
.
)
M_{UFE}(.)
MUFE(.)提取高级和多尺度深度特征
F
d
e
e
p
∈
R
H
×
W
×
3
F_{deep}\in\mathbb{R}^{H\times W\times3}
Fdeep∈RH×W×3
F
d
e
e
p
=
M
U
F
E
(
F
s
h
a
l
l
o
w
)
F_{deep} = M_{UFE}(F_{shallow})
Fdeep=MUFE(Fshallow) (3)
其中 MUFE(.) 是带有 Swin Transformer Block 的 UNet 架构,它在单个块中包含 8 个 Swin Transformer 层以替换卷积。 Swin Transformer Block (STB) 和 Swin Transformer Layer (STL) 将在下一节中详细说明。
Reconstruction module
最后,我们仍然使用 3 × 3 卷积 MR(.) 从深度特征
F
d
e
e
p
F_{deep}
Fdeep生成无噪声图像
X
^
∈
R
H
×
W
×
3
\hat{X}\in\mathbb{R}^{H\times W\times3}
X^∈RH×W×3,公式为:
X
^
=
M
R
(
F
d
e
e
p
)
\hat{X} = M_R(F_{deep})
X^=MR(Fdeep) (4)
请注意,
X
^
\hat{X}
X^是通过将噪声图像 Y 作为 SUNet 的输入而获得的,X 是(1)中 Y 图像的真实和干净版本。
Loss function
我们使用常规的L1像素损失对SUNet进行端到端优化以进行图像去噪。
L
d
e
n
o
i
s
e
=
∣
∣
X
^
−
X
∣
∣
1
\mathcal{L}_{denoise}=||\hat{X}-X||_1
Ldenoise=∣∣X^−X∣∣1 (5)
Swin Transformer block
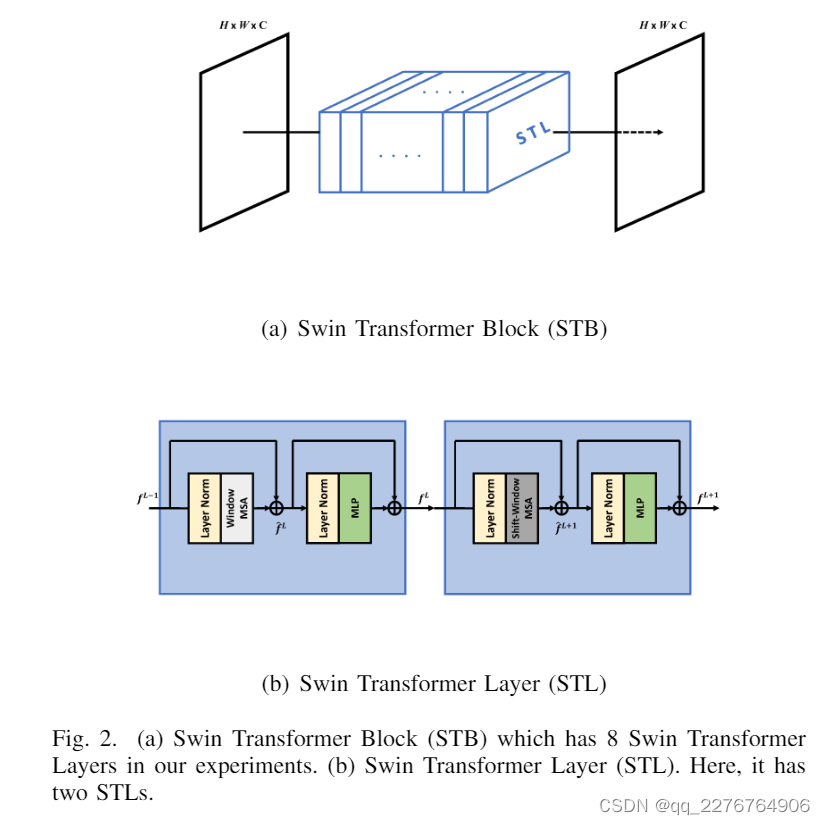
在 UNet 提取模块中,我们使用 STB 代替传统的卷积层,如图 2 所示。STL基于来自 NLP 的原始 Transformer 层。 STL的数量总是2的倍数,其中一个用于window multi-head self-attention (W-MSA),另一个用于shifted-window multi-head self-attention (SW-MSA)。 如Section II-C所述,在CV任务中直接使用Transformer会出现一些问题。 因此,他们提出了cyclic shift(循环移位)技术来减少计算时间并保持卷积的特性,包括平移不变性、旋转不变性和感受野与层之间关系的大小不变性。 由于篇幅限制,我们在本文中没有解释SW-MSA的原理以及它可以降低多少计算复杂度。 但我们想强调 Swin Transformer 的一个关键属性(即我们可以控制输出特征的分辨率(H,W)和通道数(C)与卷积操作相同)。 以图2(b)为例,整个过程表示为:
f
^
L
=
W
−
M
S
A
(
L
N
(
f
L
−
1
)
)
+
f
L
−
1
,
f
L
=
M
L
P
(
L
N
(
f
^
L
)
)
+
f
^
L
,
f
^
L
+
1
=
S
W
−
M
S
A
(
L
N
(
f
L
)
)
+
f
L
,
f
L
+
1
=
M
L
P
(
L
N
(
f
^
(
f
L
+
1
)
)
+
f
^
L
+
1
,
\begin{aligned}\hat f^L&=W-MSA(LN(f^{L-1}))+f^{L-1},\\ f^L&=MLP(LN(\hat f^L))+\hat f^L,\\ \hat f^{L+1}&=SW-MSA(LN(f^L))+f^L,\\ f^{L+1}&=MLP( LN(\hat f(f^{L+1}))+\hat f^{L+1},\\ \end{aligned}
f^LfLf^L+1fL+1=W−MSA(LN(fL−1))+fL−1,=MLP(LN(f^L))+f^L,=SW−MSA(LN(fL))+fL,=MLP(LN(f^(fL+1))+f^L+1, (6)
其中 LN (.) 表示层归一化,M LP 是多层感知器,它有两个完全连接的层,具有高斯误差线性单元 (GELU) 激活函数。
Resizing moule(调整大小模块)
由于 UNet 具有不同比例的特征图,因此需要调整大小的模块(例如,下采样和上采样)。 在我们的 SUNet 中,我们分别使用patch merging和建议的双上采样作为下采样和上采样模块。
Patch merging
对于下采样模块,我们按照Swin Transformer、Swin-unet将每组2×2相邻块的输入特征连接起来,然后使用线性层获得指定通道数的输出特征。 我们也可以将此视为进行卷积操作的第一步,即展开输入特征图。
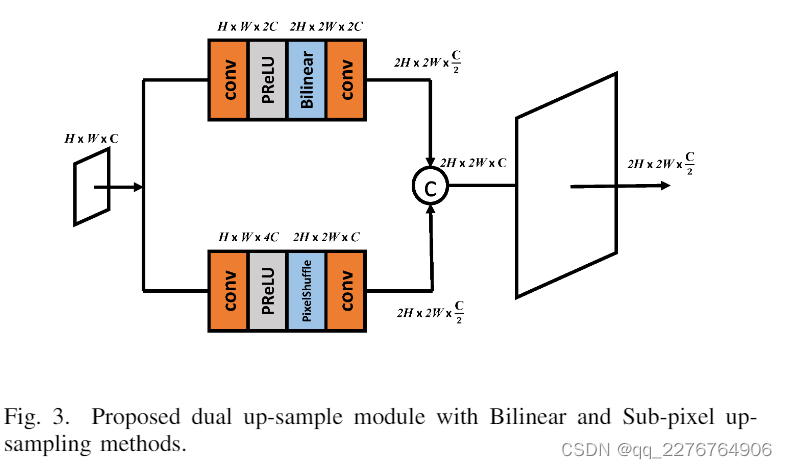
Dual up-sample
至于上采样,原始的Swin-unet使用patch expanding方法,相当于上采样模块中的转置卷积。 然而,转置卷积容易面临块效应。 在这里,我们提出了一个名为双上采样的新模块,它包含两种现有的上采样方法(即双线性和 PixelShuffle Subpixl),以防止棋盘伪影。 所提出的上采样模块的架构如图 3 所示。
Experiments
Implementation Details(实施细节)
我们的SUNet是一个没有任何预训练网络的端到端可训练模型,由pytorch1.8.0和单个NVIDIA GTX 1080 Ti GPU实现
Evaluation Metrics(评估指标)
对于定量比较,我们考虑了峰值信噪比(PSNR)和结构相似性(SSIM)指标。注意PSNR和SSIM值都是越高越好,PSNR的单位是分贝(dB)。
Experiment Datasets(实验数据集)
Traning Set
使用同DHDN、DRUNet相同的图像去噪实验设置,我们在图像超分辨率DIV2K数据集上训练我们的模型,该数据集具有800和100个高质量(平均分辨率约为19201080)图像分别用于训练和测试。
我们为每个训练图像随机裁剪 100 个大小为 256 × 256 的块,并随机将 AWGN 添加到噪声级别从 σ = 5 到 σ = 50 的块中,用于 800 个训练图像。 至于验证,我们直接使用包含 100 张图像的测试集,并添加具有 σ = 10、σ = 30 和 σ = 50 三种不同噪声水平的 AWGN。
Testing Set
为了评估,我们选择了CBSD68数据集,他有68张彩色图像,分辨率为768512,Kodak24数据集由24张图像组成,图像大小为321*481.
Image Denoising Performance
我们将我们的 SUNet 与基于先验的方法(例如 CBM3D)、基于 CNN 的方法(例如 DnCNN
、IRCNN、FFDNet)和基于 UNet 的方法(例如 UNet )进行比较 , DHDN, RDUNet [9])。 图 4 说明了图像去噪的视觉比较 [39]、[40] 结果。 在表 I 中,我们对去噪图像进行了客观质量评估 [41]-[43],并观察到以下三点:1)我们的 SUNet 具有具有竞争力的 SSIM 值,因为 Swin-Transformer 基于全局信息,这使得去噪图像感知上更有信服力。 2)与基于 UNet 的方法(DHDN、RDUNet)相比,所提出的 SUNet 在三个模型中具有更少的参数(↓ 60%)和 FLOPs(↓ 3%),并且在 PSNR 和 SSIM 上仍然保持良好的分数。 3) 与基于 CNN 的方法(DnCNN、IrCNN、FFDNet)相比,我们拥有其中最好的 PSNR 和 SSIM 结果以及几乎相同的 FLOP。 虽然我们模型的参数最多(99M),但这是由于无法共享内核权重的自注意力操作造成的。 然而,正如我们在第一节中讨论的那样,不同层中的特征应该使用不同的核值更为合理。
conclusion
在本文中我们提出了基于Swin Transformer新主干的SUNet架构,并在去噪访民啊取得了有竞争力的结果。此外,我们提出双上采样模块来避免棋盘伪影。现在说Swin Transformer可以取代卷积该为时过早。不过,未来Swin Transformer的潜力还是值得期待的。我们未来的作品将尝试更复杂的修复任务。如仍用基于Swin Transformer的模型去噪真实世界的噪声和雾。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









